En este artículo, vamos a ver cómo raspar Reddit usando Python, aquí usaremos el módulo PRAW (Python Reddit API Wrapper) de Python para raspar los datos. Praw es un acrónimo de Python Reddit API wrapper, permite la API de Reddit a través de scripts de Python.
Instalación
Para instalar PRAW, ejecute los siguientes comandos en el símbolo del sistema:
pip install praw
Crear una aplicación Reddit
Paso 1: Para extraer datos de Reddit, necesitamos crear una aplicación de Reddit. Puede crear una nueva aplicación Reddit (https://www.reddit.com/prefs/apps).
Reddit: crea una aplicación
Paso 2: Haz clic en “¿eres desarrollador? crear una aplicación…”.
Paso 3: Aparecerá un formulario como este en su pantalla. Introduzca el nombre y la descripción de su elección. En el cuadro de uri de redirección , ingrese http://localhost:8080

Formulario de solicitud
Paso 4: después de ingresar los detalles, haga clic en «crear aplicación».
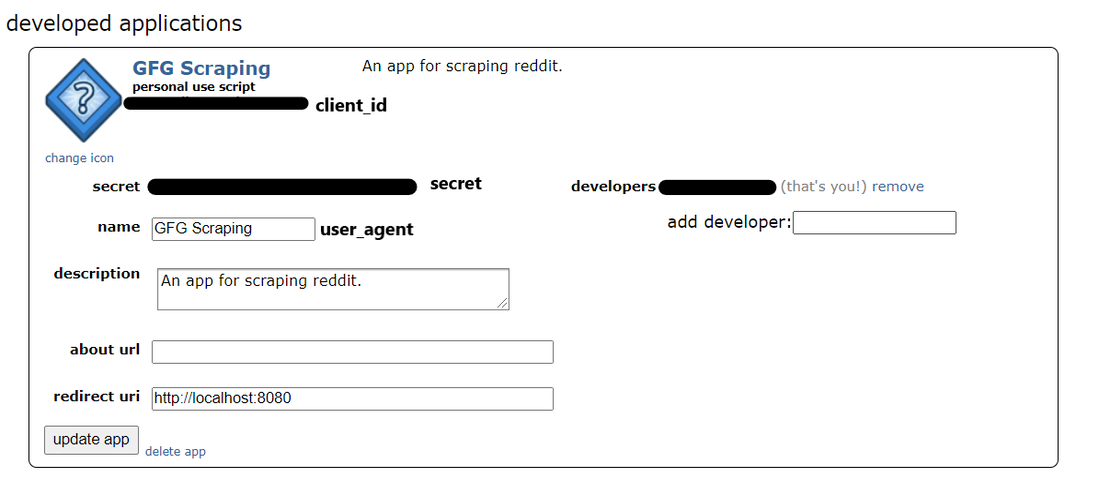
Aplicación desarrollada
Se ha creado la aplicación Reddit. Ahora, podemos usar python y praw para extraer datos de Reddit. Anote los valores de client_id, secret y user_agent. Estos valores se usarán para conectarse a Reddit usando python.
Creación de una instancia PRAW
Para conectarnos a Reddit, necesitamos crear una instancia de praw. Hay 2 tipos de instancias de gambas:
- Instancia de solo lectura: al usar instancias de solo lectura, solo podemos recopilar información disponible públicamente en Reddit. Por ejemplo, recuperar las 5 publicaciones principales de un subreddit en particular.
- Instancia autorizada : con una instancia autorizada, puede hacer todo lo que hace con su cuenta de Reddit. Se pueden realizar acciones como votar, publicar, comentar, etc.
Python3
# Read-only instance reddit_read_only = praw.Reddit(client_id="", # your client id client_secret="", # your client secret user_agent="") # your user agent # Authorized instance reddit_authorized = praw.Reddit(client_id="", # your client id client_secret="", # your client secret user_agent="", # your user agent username="", # your reddit username password="") # your reddit password
Ahora que hemos creado una instancia, podemos usar la API de Reddit para extraer datos. En este tutorial, solo usaremos la instancia de solo lectura.
Raspado de subreddits de Reddit
Hay diferentes formas de extraer datos de un subreddit. Las publicaciones en un subreddit se clasifican como populares, nuevas, principales, controvertidas, etc. Puede usar cualquier método de clasificación de su elección.
Extraigamos algo de información del subreddit de redditdev.
Python3
import praw
import pandas as pd
reddit_read_only = praw.Reddit(client_id="", # your client id
client_secret="", # your client secret
user_agent="") # your user agent
subreddit = reddit_read_only.subreddit("redditdev")
# Display the name of the Subreddit
print("Display Name:", subreddit.display_name)
# Display the title of the Subreddit
print("Title:", subreddit.title)
# Display the description of the Subreddit
print("Description:", subreddit.description)
Producción:
Nombre, Título y Descripción
Ahora extraigamos 5 publicaciones calientes del subreddit de Python:
Python3
subreddit = reddit_read_only.subreddit("Python")
for post in subreddit.hot(limit=5):
print(post.title)
print()
Producción:

Las 5 publicaciones más populares
Ahora guardaremos las publicaciones principales del subreddit de python en un marco de datos de pandas:
Python3
posts = subreddit.top("month")
# Scraping the top posts of the current month
posts_dict = {"Title": [], "Post Text": [],
"ID": [], "Score": [],
"Total Comments": [], "Post URL": []
}
for post in posts:
# Title of each post
posts_dict["Title"].append(post.title)
# Text inside a post
posts_dict["Post Text"].append(post.selftext)
# Unique ID of each post
posts_dict["ID"].append(post.id)
# The score of a post
posts_dict["Score"].append(post.score)
# Total number of comments inside the post
posts_dict["Total Comments"].append(post.num_comments)
# URL of each post
posts_dict["Post URL"].append(post.url)
# Saving the data in a pandas dataframe
top_posts = pd.DataFrame(posts_dict)
top_posts
Producción:

publicaciones principales del subreddit de python
Exportación de datos a un archivo CSV:
Python3
import pandas as pd
top_posts.to_csv("Top Posts.csv", index=True)
Producción:

Archivo CSV de publicaciones principales
Raspado de publicaciones de Reddit:
Para extraer datos de las publicaciones de Reddit, necesitamos la URL de la publicación. Una vez que tenemos la URL, necesitamos crear un objeto de envío.
Python3
import praw import pandas as pd reddit_read_only = praw.Reddit(client_id="", # your client id client_secret="", # your client secret user_agent="") # your user agent # URL of the post url = "https://www.reddit.com/r/IAmA/comments/m8n4vt/\ im_bill_gates_cochair_of_the_bill_and_melinda/" # Creating a submission object submission = reddit_read_only.submission(url=url)
Extraeremos los mejores comentarios del post que hayamos seleccionado. Necesitaremos el objeto MoreComments del módulo praw. Para extraer los comentarios, utilizaremos un bucle for en el objeto de envío. Todos los comentarios se agregarán a la lista post_comments. También agregaremos una declaración if en el ciclo for para verificar si algún comentario tiene el tipo de objeto de más comentarios. Si es así, significa que nuestra publicación tiene más comentarios disponibles. Así que agregaremos estos comentarios a nuestra lista también. Finalmente, convertiremos la lista en un marco de datos de pandas.
Python3
from praw.models import MoreComments post_comments = [] for comment in submission.comments: if type(comment) == MoreComments: continue post_comments.append(comment.body) # creating a dataframe comments_df = pd.DataFrame(post_comments, columns=['comment']) comments_df
Producción:

lista en un marco de datos de pandas
Publicación traducida automáticamente
Artículo escrito por urvishmahajan y traducido por Barcelona Geeks. The original can be accessed here. Licence: CCBY-SA