Regresión logística
La regresión logística, también conocida como clasificación binaria, es uno de los algoritmos de aprendizaje automático más populares. Viene bajo algoritmos de clasificación de aprendizaje supervisado. Se utiliza para predecir la probabilidad de la etiqueta objetivo. Por clasificación binaria, significa que el modelo predice la etiqueta 0 o 1. La variable de destino son tipos de datos categóricos, por ejemplo: Sí o No, Sobrevivió o No sobrevivió, Hombre o Mujer, Aprobado o Reprobado, etc. La regresión logística hace uso de la función sigmoidea para hacer la predicción. La función de activación sigmoidea es una función no lineal que se define como:
y = 1/(1+e-z) #the y is in range 0-1 #z = x*w + b where w is weight and b is bias
Regresión logística de MNIST en Pytorch
Pytorch es el poderoso marco Python de aprendizaje automático . Con el marco Pytorch, se vuelve más fácil implementar la regresión logística y también proporciona el conjunto de datos MNIST.
Instalación:
pip install torch pip install torchvision --no-deps
Pasos para construir un modelo de predicción MNIST completo usando Regresión Logística
Importar módulos necesarios
import torch import torchvision import torch.nn as tn import matplotlib.pyplot as plt import torchvision.transforms as tt import torch.utils as utils
Descargar los conjuntos de datos de torchvision
El módulo Torchvision proporciona el conjunto de datos MNIST que se puede descargar ingresando este código:
Python
train_data = torchvision.datasets.MNIST('./data',download=True)
test_data = torchvision.datasets.MNIST('data',train=False)
print(train_data)
print(test_data)
Producción:
Dataset MNIST
Number of datapoints: 60000
Root location: ./data
Split: Train
Dataset MNIST
Number of datapoints: 10000
Root location: data
Split: Test
Ok, los datos de entrenamiento y de prueba que tenemos ahora están en forma de imágenes:
Python3
print(train_data[0])
Producción:
(<PIL.Image.Image image mode=L size=28x28 at 0x7FEFA4362E80>, 5)
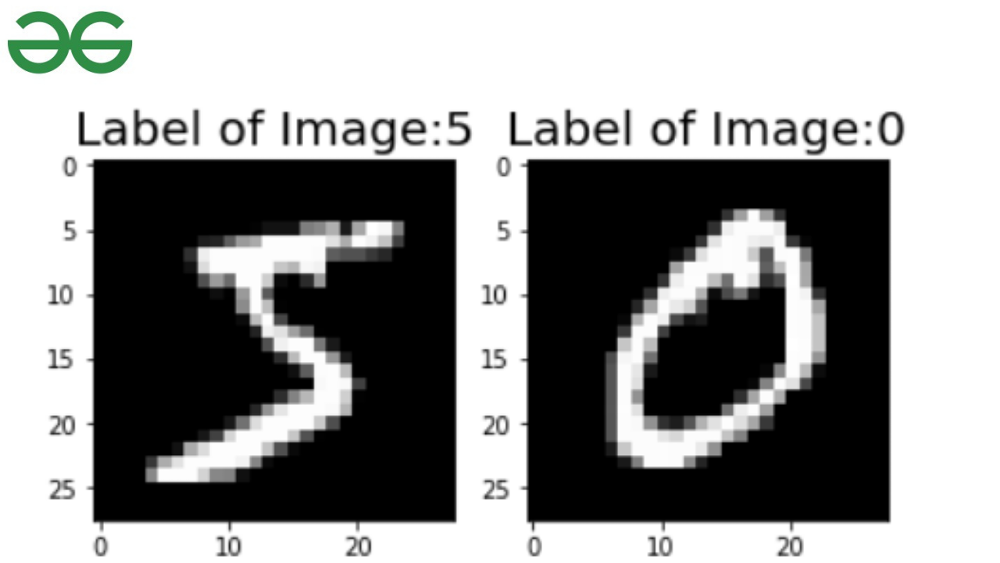
Si observa la salida cuidadosamente, obtenemos una idea de los datos del tren. La imagen está compuesta por 28*28 píxeles y la primera imagen de índice es 5. Dado que tiene forma de tupla, donde el índice uno es la imagen y el índice dos es la etiqueta del bloque de código. Usando Matplotlib podemos visualizar qué imagen contiene el índice de datos del primer tren.
Visualizar
Python3
import matplotlib.pyplot as plt
plt.subplot(1,2,1)
image, label = train_data[0]
plt.imshow(image, cmap='gray')
plt.title("Label of Image:{}".format(label),fontsize=20)
plt.subplot(1,2,2)
image, label = train_data[1]
plt.imshow(image, cmap='gray')
plt.title("Label of Image:{}".format(label),fontsize=20)
Producción:
Transformación de datos:
Dado que los datos están en forma de imagen, deben transformarse en Tensor, para que la red neuronal PyTorch pueda entrenar los datos. Torchvision proporciona un método de transformación.
train_data = torchvision.datasets.MNIST('data',train=True,transform=tt.ToTensor())
test_data = torchvision.datasets.MNIST('data',train=False,transform=tt.ToTensor())
Argumentos requeridos
input_size = 28*28 #Tamaño de la imagen
num_classes = 10 #el número de imagen está en el rango 0-10
num_epochs = 5 #un ciclo a través de los datos completos del tren
batch_size = 100 #tamaño de muestra considerar antes de actualizar los pesos del modelo
learning_rate = 0.001 #tamaño del paso para actualizar el parámetro
Hazlo iterable
Usando DataLoader podemos recorrer el tensor de los datos del tren.
train_dataLoader = torch.utils.data.DataLoader(train_data, batch_size=batch_size,shuffle=True) test_dataLoader = torch.utils.data.DataLoader(test_data,batch_size=batch_size,shuffle=False)
Construir modelo de regresión logística
Cree un modelo de regresión logística que se ajuste a las características y los datos de salida.
class LogisticRegression(tn.Module):
def __init__(self,input_size,num_classes):
super(LogisticRegression,self).__init__()
self.linear = tn.Linear(input_size,num_classes)
def forward(self,feature):
output = self.linear(feature)
return output
Pérdida y optimizador
Usaremos la función CrossEntropyLoss para calcular la pérdida calculada. La razón para usar la función CrossEntropyLoss es que calcula la función softmax y la entropía cruzada.
Y Stochastic Gradient Descent es el optimizador utilizado para calcular el gradiente y actualizar los parámetros.
model = LogisticRegression(input_size,num_classes) loss = tn.CrossEntropyLoss() optimizer = torch.optim.SGD(model.parameters(),lr=learning_rate)
entrenar y predecir
Convierta imágenes y etiquetas en tensores con gradientes y luego borre los parámetros wrt de gradientes (optimizer.zero_grad()). Calcule la pérdida del gradiente e intente reducir la pérdida actualizando los parámetros agregando una tasa de aprendizaje. Este proceso se llama propagación hacia atrás.
run = 0
for epoch in range(num_epochs):
for i,(images,labels) in enumerate(train_dataLoader):
images = torch.autograd.Variable(images.view(-1,input_size))
labels = torch.autograd.Variable(labels)
# Nullify gradients w.r.t. parameters
optimizer.zero_grad()
#forward propagation
output = model(images)
# compute loss based on obtained value and actual label
compute_loss = loss(output,labels)
# backward propagation
compute_loss.backward()
# update the parameters
optimizer.step()
run+=1
if (i+1)%200 == 0:
# check total accuracy of predicted value and actual label
accurate = 0
total = 0
for images,labels in test_dataLoader:
images = torch.autograd.Variable(images.view(-1,input_size))
output = model(images)
_,predicted = torch.max(output.data, 1)
# total labels
total+= labels.size(0)
# Total correct predictions
accurate+= (predicted == labels).sum()
accuracy_score = 100 * accurate/total
print('Iteration: {}. Loss: {}. Accuracy: {}'.format(run, compute_loss.item(), accuracy_score))
print('Final Accuracy:',accuracy_score)
Resultado final:
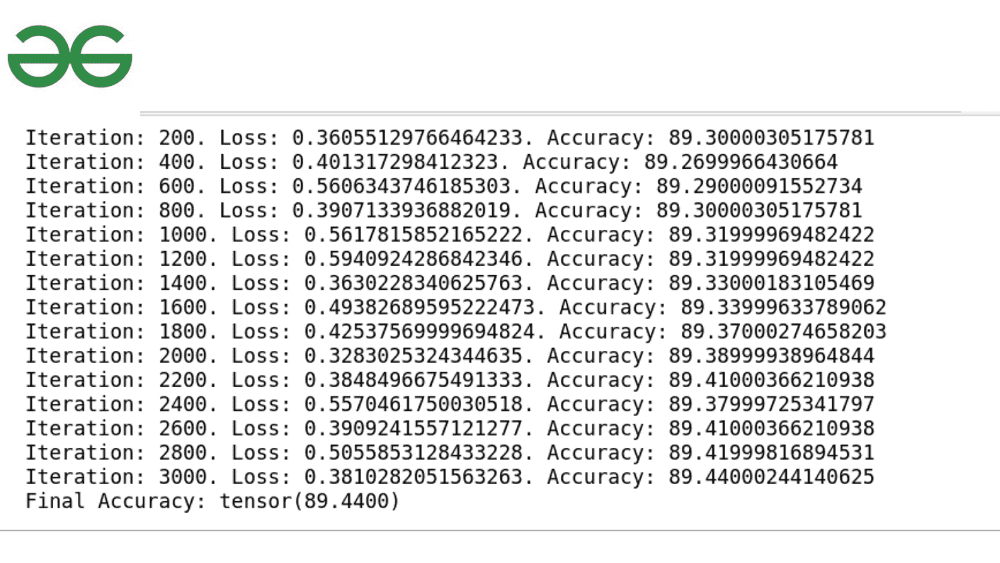
La puntuación de precisión es 89, que no está mal.