La regresión logística en la programación R es un algoritmo de clasificación que se utiliza para encontrar la probabilidad de éxito y falla del evento. La regresión logística se utiliza cuando la variable dependiente es de naturaleza binaria (0/1, Verdadero/Falso, Sí/No). La función logit se utiliza como función de enlace en una distribución binomial.
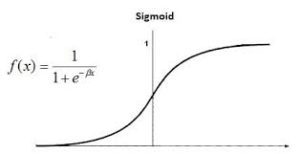
Logistic regression is also known as Binomial logistics regression. It is based on sigmoid function where output is probability and input can be from -infinity to +infinity.
Teoría
La regresión logística también se conoce como modelo lineal generalizado. Como se utiliza como técnica de clasificación para predecir una respuesta cualitativa, el valor de y varía de 0 a 1 y se puede representar mediante la siguiente ecuación:
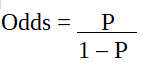
pes la probabilidad de la característica de interés. La razón de posibilidades se define como la probabilidad de éxito en comparación con la probabilidad de fracaso. Es una representación clave de los coeficientes de regresión logística y puede tomar valores entre 0 e infinito. La razón de probabilidad de 1 es cuando la probabilidad de éxito es igual a la probabilidad de fracaso. La razón de probabilidad de 2 es cuando la probabilidad de éxito es el doble de la probabilidad de fracaso. La razón de probabilidad de 0,5 es cuando la probabilidad de fracaso es el doble de la probabilidad de éxito.
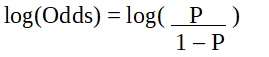
Dado que estamos trabajando con una distribución binomial (variable dependiente), debemos elegir una función de enlace que se adapte mejor a esta distribución.
![]()
Es función logit . En la ecuación anterior, el paréntesis se elige para maximizar la probabilidad de observar los valores de la muestra en lugar de minimizar la suma de los errores al cuadrado (como en la regresión ordinaria). El logit también se conoce como registro de probabilidades. La función logit debe estar relacionada linealmente con las variables independientes. Esto es de la ecuación A, donde el lado izquierdo es una combinación lineal de x. Esto es similar a la suposición de MCO de que y se relaciona linealmente con x.
Las variables b0, b1, b2, etc. son desconocidas y deben estimarse con los datos de entrenamiento disponibles. En un modelo de regresión logística, multiplicar b1 por una unidad cambia el logit por b0. Los cambios de P debido a un cambio de una unidad dependerán del valor multiplicado. Si b1 es positivo, P aumentará y si b1 es negativo, P disminuirá.
El conjunto de datos
mtcars(prueba de carretera de automóvil de tendencia de motor) comprende el consumo de combustible, el rendimiento y 10 aspectos del diseño del automóvil para 32 automóviles. Viene preinstalado con el dplyrpaquete en R.
# Installing the package
install.packages("dplyr")
# Loading package
library(dplyr)
# Summary of dataset in package
summary(mtcars)
Realización de una regresión logística en un conjunto de datos
La regresión logística se implementa en R mediante glm()el entrenamiento del modelo mediante funciones o variables en el conjunto de datos.
# Installing the package
install.packages("caTools") # For Logistic regression
install.packages("ROCR") # For ROC curve to evaluate model
# Loading package
library(caTools)
library(ROCR)
# Splitting dataset
split <- sample.split(mtcars, SplitRatio = 0.8)
split
train_reg <- subset(mtcars, split == "TRUE")
test_reg <- subset(mtcars, split == "FALSE")
# Training model
logistic_model <- glm(vs ~ wt + disp,
data = train_reg,
family = "binomial")
logistic_model
# Summary
summary(logistic_model)
# Predict test data based on model
predict_reg <- predict(logistic_model,
test_reg, type = "response")
predict_reg
# Changing probabilities
predict_reg <- ifelse(predict_reg >0.5, 1, 0)
# Evaluating model accuracy
# using confusion matrix
table(test_reg$vs, predict_reg)
missing_classerr <- mean(predict_reg != test_reg$vs)
print(paste('Accuracy =', 1 - missing_classerr))
# ROC-AUC Curve
ROCPred <- prediction(predict_reg, test_reg$vs)
ROCPer <- performance(ROCPred, measure = "tpr",
x.measure = "fpr")
auc <- performance(ROCPred, measure = "auc")
auc <- auc@y.values[[1]]
auc
# Plotting curve
plot(ROCPer)
plot(ROCPer, colorize = TRUE,
print.cutoffs.at = seq(0.1, by = 0.1),
main = "ROC CURVE")
abline(a = 0, b = 1)
auc <- round(auc, 4)
legend(.6, .4, auc, title = "AUC", cex = 1)
wt influye positivamente en las variables dependientes y un aumento de una unidad en wt aumenta el logaritmo de probabilidades para vs = 1 en 1,44. disp influye negativamente en las variables dependientes y un aumento de una unidad en disp disminuye el logaritmo de probabilidades para vs =1 en 0,0344. La desviación nula es 31,755 (variable dependiente ajustada con intercepción) y la desviación residual es 14,457 (variable dependiente ajustada con todas las variables independientes). El valor de AIC (criterios de información alcalina) es 20,457, es decir, cuanto menor, mejor para el modelo. La precisión resulta ser 0,75, es decir, 75%.
El modelo se evalúa utilizando la array de confusión, AUC (área bajo la curva) y la curva ROC (características operativas del receptor). En la array de confusión no siempre debemos buscar la precisión sino también la sensibilidad y la especificidad. Se traza la curva ROC y AUC.
Producción:
- Evaluación de la precisión del modelo utilizando la array de confusión:
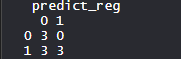
Hay 0 errores de tipo 2, es decir, no se puede rechazar cuando es falso. Además, hay 3 errores de tipo 1, es decir, rechazarlo cuando es cierto.
- Curva ROC:
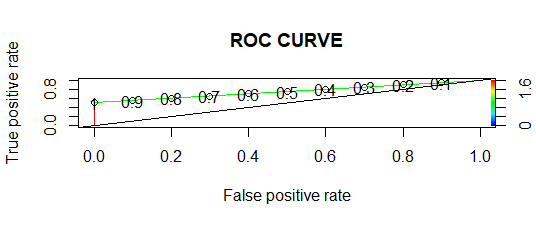
En la curva ROC, cuanto mayor sea el área bajo la curva, mejor será el modelo.
- Curva ROC-AUC:
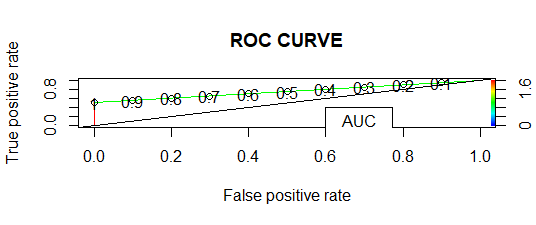
AUC es 0,7333, por lo que cuanto más AUC es, mejor funciona el modelo.