Los datos no lineales generalmente se encuentran en la vida diaria. Considere algunas de las ecuaciones de movimiento estudiadas en la física.
- Movimiento de proyectil : La altura de un proyectil se calcula como h = -½ gt 2 +ut +ho
- Ecuación de movimiento en caída libre : La distancia recorrida por un objeto después de caer libremente por gravedad durante ‘t’ segundos es ½ gt 2 .
- Distancia recorrida por un cuerpo uniformemente acelerado : La distancia se puede calcular como ut + ½at 2
donde,
g = aceleración de la gravedad
u = velocidad inicial
ho = altura inicial
a = aceleración
Además de estos ejemplos, también se observan tendencias no lineales en la tasa de crecimiento de los tejidos, el progreso de la epidemia de enfermedades, la radiación del cuerpo negro, el movimiento del péndulo, etc. Estos ejemplos indican claramente que no siempre podemos tener una relación lineal entre los atributos independientes y dependientes. Por lo tanto, la regresión lineal es una mala elección para tratar este tipo de situaciones no lineales . ¡Aquí es donde la regresión polinomial viene a rescatarnos!
La regresión polinomial es una técnica poderosa para encontrar situaciones en las que existe una relación no lineal cuadrática, cúbica o de mayor grado. El concepto subyacente en la regresión polinomial es agregar potencias de cada atributo independiente como nuevos atributos y luego entrenar un modelo lineal en esta colección ampliada de características.
Ilustremos el uso de la regresión polinomial con un ejemplo. Considere una situación donde la variable dependiente y varía con respecto a una variable independiente x siguiendo una relación
y = 13x2 + 2x + 7
.
Usaremos la clase PolynomialFeatures de Scikit-Learn para la implementación.
Paso 1: importe las bibliotecas y genere un conjunto de datos aleatorio.
# Importing the libraries import numpy as np import matplotlib.pyplot as plt from sklearn.linear_model import LinearRegression from sklearn.preprocessing import PolynomialFeatures from sklearn.metrics import mean_squared_error, r2_score # Importing the dataset ## x = data, y = quadratic equation x = np.array(7 * np.random.rand(100, 1) - 3) x1 = x.reshape(-1, 1) y = 13 * x*x + 2 * x + 7
Paso 2: Trace los puntos de datos.
# data points
plt.scatter(x, y, s = 10)
plt.xlabel('x')
plt.ylabel('y')
plt.title('Non Linear Data')
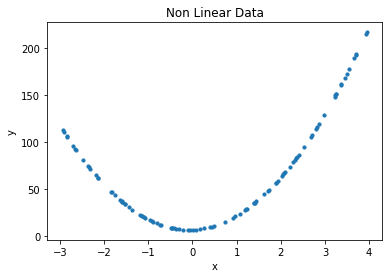
Step3: First try to fit the data with a linear model.
# Model initialization
regression_model = LinearRegression()
# Fit the data(train the model)
regression_model.fit(x1, y)
print('Slope of the line is', regression_model.coef_)
print('Intercept value is', regression_model.intercept_)
# Predict
y_predicted = regression_model.predict(x1)
Producción:
Slope of the line is [[14.87780012]] Intercept value is [58.31165769]
Paso 4: Trace los puntos de datos y la línea lineal.
# data points
plt.scatter(x, y, s = 10)
plt.xlabel("$x$", fontsize = 18)
plt.ylabel("$y$", rotation = 0, fontsize = 18)
plt.title("data points")
# predicted values
plt.plot(x, y_predicted, color ='g')
Producción: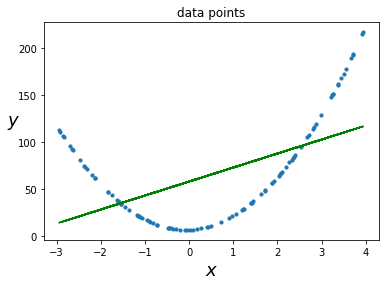
Equation of the linear model is y = 14.87x + 58.31
Paso 5: Calcular el rendimiento del modelo en términos de error cuadrático medio, error cuadrático medio y puntuación r2.
# model evaluation
mse = mean_squared_error(y, y_predicted)
rmse = np.sqrt(mean_squared_error(y, y_predicted))
r2 = r2_score(y, y_predicted)
# printing values
print('MSE of Linear model', mse)
print('R2 score of Linear model: ', r2)
Producción:
MSE of Linear model 2144.8229656677095 R2 score of Linear model: 0.3019970606151057
El rendimiento del modelo lineal no es satisfactorio. Probemos la regresión polinomial con grado 2
Paso 6: Para mejorar el rendimiento, debemos hacer que el modelo sea un poco complejo. Entonces, ajustemos un polinomio de grado 2 y procedamos con la regresión lineal.
poly_features = PolynomialFeatures(degree = 2, include_bias = False) x_poly = poly_features.fit_transform(x1) x[3]
Producción:
Out[]:array([-2.84314447])
x_poly[3]
Producción:
Out[]:array([-2.84314447, 8.08347046])
Además de la columna x, se ha introducido una columna más que es el cuadrado de los datos reales. Ahora procedemos con la regresión lineal simple
lin_reg = LinearRegression()
lin_reg.fit(x_poly, y)
print('Coefficients of x are', lin_reg.coef_)
print('Intercept is', lin_reg.intercept_)
Producción:
Coefficients of x are [[ 2. 13.]] Intercept is [7.]
Esta es la ecuación deseada 13x 2 + 2x + 7
Paso 7: Graficar la ecuación cuadrática obtenida.
x_new = np.linspace(-3, 4, 100).reshape(100, 1)
x_new_poly = poly_features.transform(x_new)
y_new = lin_reg.predict(x_new_poly)
plt.plot(x, y, "b.")
plt.plot(x_new, y_new, "r-", linewidth = 2, label ="Predictions")
plt.xlabel("$x_1$", fontsize = 18)
plt.ylabel("$y$", rotation = 0, fontsize = 18)
plt.legend(loc ="upper left", fontsize = 14)
plt.title("Quadratic_predictions_plot")
plt.show()
Producción: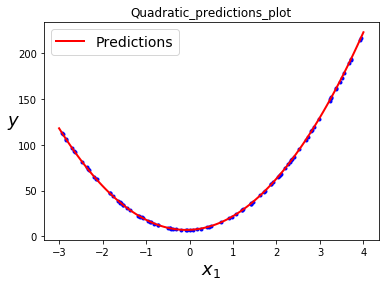
Paso 8: Calcular el rendimiento del modelo obtenido por Regresión Polinomial.
y_deg2 = lin_reg.predict(x_poly)
# model evaluation
mse_deg2 = mean_squared_error(y, y_deg2)
r2_deg2 = r2_score(y, y_deg2)
# printing values
print('MSE of Polyregression model', mse_deg2)
print('R2 score of Linear model: ', r2_deg2)
Producción:
MSE of Polyregression model 7.668437973562934e-28 R2 score of Linear model: 1.0
El rendimiento del modelo de regresión polinomial es mucho mejor que el modelo de regresión lineal para la ecuación cuadrática dada.
Datos importantes : PolynomialFeatures (grado = d) transforma una array que contiene n características en una array que contiene (n + d). / ¡d! ¡norte! caracteristicas.
Conclusión : la regresión polinomial es una forma efectiva de manejar datos no lineales, ya que puede encontrar relaciones entre características que el modelo de regresión lineal simple tiene dificultades para hacer.