El Dummy Regressor es un tipo de regresor que ofrece predicciones basadas en estrategias simples sin prestar atención a los datos de entrada. Al igual que Dummy Classifier, la biblioteca sklearn también proporciona Dummy Regressor, que se utiliza para establecer una línea de base para comparar otros Regressor existentes, a saber, Poisson Regressor, Linear Regression, Ridge Regression y muchos más. Sin embargo, en este artículo, el enfoque principal será hacer una comparación entre la regresión ficticia y la regresión lineal.
- PASO 1- Importación de los módulos necesarios. El módulo ficticio de sklearn proporciona un modelo DummyRegressor integrado que se utilizará en este caso. Además de importar otros módulos, el error cuadrático medio y el error absoluto mediano merecen una mención especial y el propósito de hacerlo se explicará más adelante en su debido momento.
Python3
import matplotlib.pyplot as plt import numpy as np from sklearn.model_selection import train_test_split from sklearn import datasets from sklearn.linear_model import LinearRegression from sklearn.metrics import mean_squared_error, r2_score, median_absolute_error from sklearn.dummy import DummyRegressor
- PASO 2- Cargando el conjunto de datos. Aquí, el conjunto de datos de Boston se ha utilizado para el propósito que está disponible en el módulo de conjunto de datos de sklearn. Dado que este es un problema de regresión, solo una característica, es decir, los «datos», se ha considerado como una característica de entrada y se ha etiquetado como X y «objetivo» como y para las etiquetas de destino. Para hacer coincidir la dimensionalidad X e Y, la X se reduce a 1 elemento en cada fila, mediante el siguiente código.
Python3
boston=datasets.load_boston() X=boston.data[:, None, 6] y= boston.target
- PASO 3- Entrenamiento y prueba del maniquí y el modelo lineal. El siguiente código muestra que entrenar el modelo ficticio es similar a entrenar cualquier modelo de regresión regular, excepto por las estrategias. El papel principal de la estrategia es predecir los valores objetivo sin ninguna influencia de los datos de entrenamiento. Hay cuatro tipos de estrategias que utiliza Dummy Regressor:
- Media: esta es la estrategia predeterminada utilizada por el Dummy Regressor. Siempre predice la media de los valores objetivo de entrenamiento.
- Mediana: se utiliza para predecir la mediana de los valores objetivo de entrenamiento.
- Cuantil: se usa para predecir un cuantil particular de los valores objetivo de entrenamiento siempre que el parámetro del cuantil se use junto con él.
- Constante: generalmente se usa para predecir un valor personalizado específico que se proporciona y se debe mencionar el parámetro constante.
Python3
X_train, X_test, y_train, y_test = train_test_split(X, y, random_state=0) lm = LinearRegression().fit(X_train, y_train) lm_dummy_mean = DummyRegressor(strategy = 'mean').fit(X_train, y_train) lm_dummy_median = DummyRegressor(strategy = 'median').fit(X_train, y_train) y_predict = lm.predict(X_test) y_predict_dummy_mean = lm_dummy_mean.predict(X_test) y_predict_dummy_median = lm_dummy_median.predict(X_test)
En este caso, sin embargo, la «media» y la «mediana» se han utilizado para la estrategia. Pero los otros dos pueden usarse dependiendo de la necesidad.
Después de entrenar ambos modelos, se evalúan en el conjunto de prueba utilizando y_predict para el modelo lineal y y_predict_dummy_mean y y_predict_dummy_median para predecir la media y la mediana ficticias, respectivamente.
- PASO 4- Análisis de errores. Para comprender qué tan bien se desempeñó el modelo, las métricas de evaluación, como el error cuadrático medio, el error absoluto mediano y la puntuación r2_, se calculan para los modelos lineal y ficticio. El error cuadrático medio y el error absoluto mediano se evalúan junto con la puntuación r2_, principalmente para demostrar la influencia de las estrategias «media», «mediana» del DummyRegressor.
Python3
print('Linear model, coefficients: ', lm.coef_)
print("Mean squared error (dummy): {:.2f}".format(mean_squared_error(y_test,
y_predict_dummy_mean)))
print("Mean squared error (linear model): {:.2f}".format(mean_squared_error(y_test, y_predict)))
print("Median absolute error (dummy): {:.2f}".format(median_absolute_error(y_test,
y_predict_dummy_median)))
print("Median absolute error (linear model): {:.2f}".format(median_absolute_error(y_test, y_predict)))
print("r2_score (dummy mean): {:.2f}".format(r2_score(y_test, y_predict_dummy_mean)))
print("r2_score (dummy median): {:.2f}".format(r2_score(y_test, y_predict_dummy_median)))
print("r2_score (linear model): {:.2f}".format(r2_score(y_test, y_predict)))
Producción-
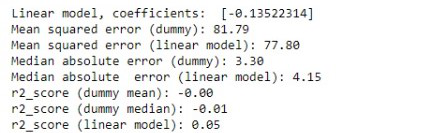
Análisis de errores
OBSERVACIÓN: Como puede verse en el resultado anterior. El regresor ficticio esperado siempre predice la puntuación r2_ como 0 tanto para la media como para la mediana, ya que siempre predice una constante sin tener una idea de la salida. (En general, el mejor r2_score es 1 y el r2_score constante es 0). El modelo de regresión lineal parece ajustarse un poco mejor que el regresor ficticio en términos de «error cuadrático medio», «error absoluto medio» y «puntuación_r2».
- PASO 5: para visualizar el rendimiento de Dummy Regressor y Linear Regressor, ambos modelos se trazan sobre los datos de prueba.
Python3
plt.scatter(X_test, y_test, color='black') plt.plot(X_test, y_predict, color='green', linewidth=2) plt.plot(X_test, y_predict_dummy_median, color='blue', linestyle = 'dashed', linewidth=2, label = 'dummy') plt.plot(X_test, y_predict_dummy_mean, color='red', linestyle = 'dashed', linewidth=2, label = 'dummy')
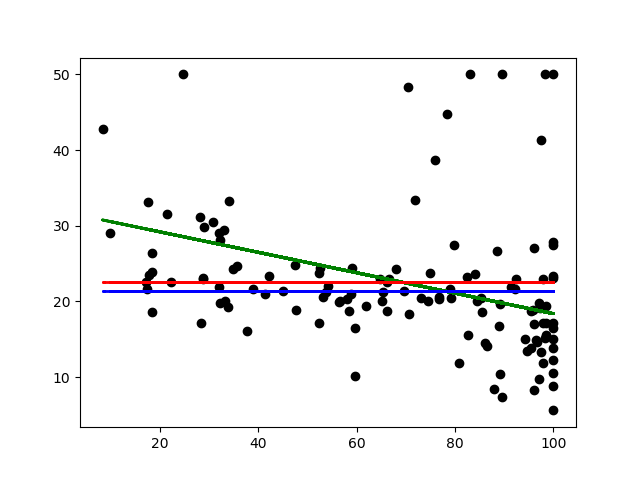
Gráfico de datos vs objetivo
Conclusión: el gráfico disperso en el gráfico anterior son las instancias del conjunto de prueba que tienden a acumularse ligeramente en la parte inferior derecha. La línea verde es el modelo de regresión lineal que se ajustó a los puntos de entrenamiento. La línea roja muestra la media ficticia que siempre usa la estrategia de predecir la media del conjunto de entrenamiento, de manera similar, la línea azul muestra la mediana ficticia y tiene el mismo propósito para predecir la mediana del conjunto de entrenamiento. Tal como está, vea que el modelo lineal no se ajusta tan bien a los datos de prueba.
Por lo tanto, ahora se puede concluir finalmente que Dummy Regressor se puede usar para verificar qué tan bien se ajusta un modelo de regresión regular a un conjunto de datos en particular, pero nunca se puede usar en ningún problema real.
Consulte la documentación de aprendizaje de scikit (» https://scikit-learn.org/stable/modules/generated/sklearn.dummy.DummyRegressor.html «) para obtener más detalles.
Publicación traducida automáticamente
Artículo escrito por torshamond333 y traducido por Barcelona Geeks. The original can be accessed here. Licence: CCBY-SA