La regularización es un tipo de regresión donde los algoritmos de aprendizaje se modifican para reducir el sobreajuste. Esto puede incurrir en un mayor sesgo pero conducirá a una menor varianza en comparación con los modelos no regularizados, es decir, aumenta la generalización del algoritmo de entrenamiento.
En un algoritmo de aprendizaje general, el conjunto de datos se divide en un conjunto de entrenamiento y un conjunto de prueba. Después de cada época del algoritmo, los parámetros se actualizan en consecuencia después de comprender el conjunto de datos. Finalmente, este modelo entrenado se aplica al conjunto de prueba. Generalmente, el error del conjunto de entrenamiento será menor en comparación con el error del conjunto de prueba. Esto se debe al sobreajuste por el cual el algoritmo memoriza los datos de entrenamiento y produce los resultados correctos en el conjunto de entrenamiento. Por lo tanto, el modelo se vuelve muy exclusivo para el conjunto de entrenamiento y no produce resultados precisos para otros conjuntos de datos, incluido el conjunto de prueba. Las técnicas de regularización se utilizan en tales situaciones para reducir el sobreajuste y aumentar el rendimiento del modelo en cualquier conjunto de datos general. La interrupción anticipada es una técnica de regularización popular debido a su simplicidad y eficacia.
La regularización por detención anticipada se puede realizar dividiendo el conjunto de datos en conjuntos de entrenamiento y prueba y luego usando validación cruzada en el conjunto de entrenamiento o dividiendo el conjunto de datos en conjuntos de entrenamiento, validación y prueba, en cuyo caso no se requiere validación cruzada. . Aquí se analiza el segundo caso. En la detención anticipada, el algoritmo se entrena utilizando el conjunto de entrenamiento y el punto en el que detener el entrenamiento se determina a partir del conjunto de validación. Se analiza el error de entrenamiento y el error de validación. El error de entrenamiento disminuye constantemente mientras que el error de validación disminuye hasta un punto, después del cual aumenta. Esto se debe a que, durante el entrenamiento, el modelo de aprendizaje comienza a sobreajustarse a los datos de entrenamiento. Esto hace que el error de entrenamiento disminuya mientras que el error de validación aumenta. Por lo tanto, se puede obtener un modelo con un mejor error de conjunto de validación si se utilizan los parámetros que dan el menor error de conjunto de validación. Cada vez que disminuye el error en el conjunto de validación, se almacena una copia de los parámetros del modelo. Cuando finaliza el algoritmo de entrenamiento, estos parámetros que dan el menor error de conjunto de validación finalmente se devuelven y no los últimos parámetros modificados.
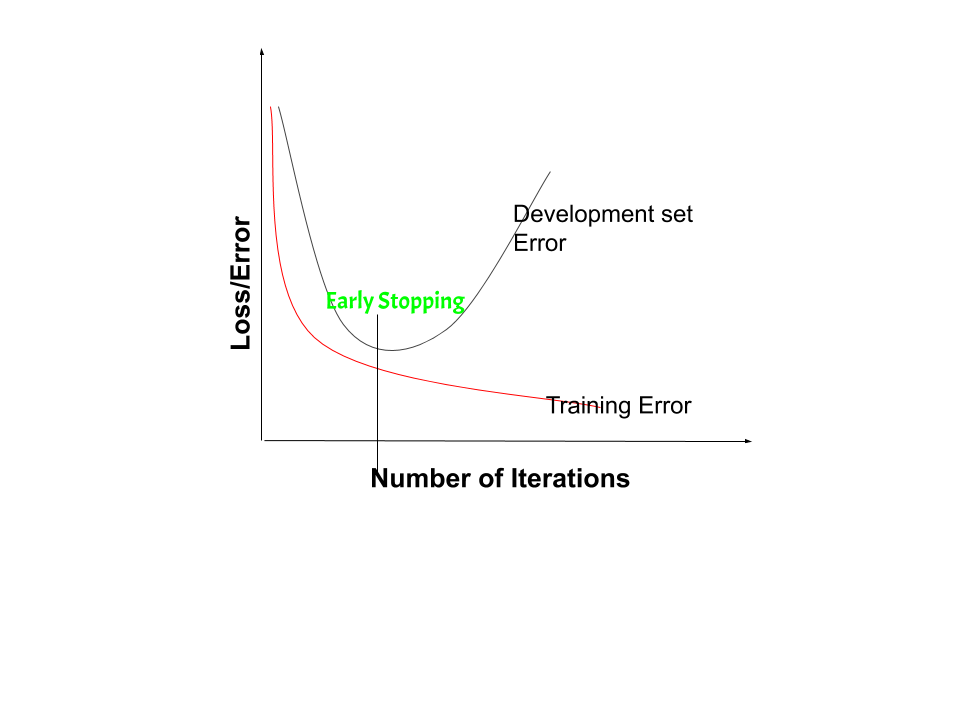 En la Regularización por detención anticipada, dejamos de entrenar el modelo cuando el rendimiento del modelo en el conjunto de validación empeora, aumenta la pérdida o disminuye la precisión o los valores más pobres de la métrica de puntuación. Al graficar el error en el conjunto de datos de entrenamiento y el conjunto de datos de validación juntos, ambos errores disminuyen con una cantidad de iteraciones hasta el punto en que el modelo comienza a sobreajustarse. Después de este punto, el error de entrenamiento aún disminuye pero el error de validación aumenta. Por lo tanto, incluso si el entrenamiento continúa después de este punto, la detención anticipada esencialmente devuelve el conjunto de parámetros que se usaron en este punto y, por lo tanto, es equivalente a detener el entrenamiento en ese punto. Por lo tanto, los parámetros finales devueltos permitirán que el modelo tenga una varianza baja y una mejor generalización. El modelo en el momento en que se detiene el entrenamiento tendrá un mejor rendimiento de generalización que el modelo con el menor error de entrenamiento. Se puede considerar que la interrupción temprana es una regularización implícita, contrariamente a la regularización a través de la disminución del peso. Este método también es eficiente ya que requiere menos cantidad de datos de entrenamiento, que no siempre están disponibles. Debido a este hecho, la parada temprana requiere menos tiempo de entrenamiento en comparación con otros métodos de regularización. Repetir el proceso de detención anticipada muchas veces puede dar como resultado que el modelo sobreajuste el conjunto de datos de validación, de la misma manera que ocurre el sobreajuste en el caso de los datos de entrenamiento. Este método también es eficiente ya que requiere menos cantidad de datos de entrenamiento, que no siempre están disponibles. Debido a este hecho, la parada temprana requiere menos tiempo de entrenamiento en comparación con otros métodos de regularización. Repetir el proceso de detención anticipada muchas veces puede dar como resultado que el modelo sobreajuste el conjunto de datos de validación, de la misma manera que ocurre el sobreajuste en el caso de los datos de entrenamiento. Este método también es eficiente ya que requiere menos cantidad de datos de entrenamiento, que no siempre están disponibles. Debido a este hecho, la parada temprana requiere menos tiempo de entrenamiento en comparación con otros métodos de regularización. Repetir el proceso de detención anticipada muchas veces puede dar como resultado que el modelo sobreajuste el conjunto de datos de validación, de la misma manera que ocurre el sobreajuste en el caso de los datos de entrenamiento.
En la Regularización por detención anticipada, dejamos de entrenar el modelo cuando el rendimiento del modelo en el conjunto de validación empeora, aumenta la pérdida o disminuye la precisión o los valores más pobres de la métrica de puntuación. Al graficar el error en el conjunto de datos de entrenamiento y el conjunto de datos de validación juntos, ambos errores disminuyen con una cantidad de iteraciones hasta el punto en que el modelo comienza a sobreajustarse. Después de este punto, el error de entrenamiento aún disminuye pero el error de validación aumenta. Por lo tanto, incluso si el entrenamiento continúa después de este punto, la detención anticipada esencialmente devuelve el conjunto de parámetros que se usaron en este punto y, por lo tanto, es equivalente a detener el entrenamiento en ese punto. Por lo tanto, los parámetros finales devueltos permitirán que el modelo tenga una varianza baja y una mejor generalización. El modelo en el momento en que se detiene el entrenamiento tendrá un mejor rendimiento de generalización que el modelo con el menor error de entrenamiento. Se puede considerar que la interrupción temprana es una regularización implícita, contrariamente a la regularización a través de la disminución del peso. Este método también es eficiente ya que requiere menos cantidad de datos de entrenamiento, que no siempre están disponibles. Debido a este hecho, la parada temprana requiere menos tiempo de entrenamiento en comparación con otros métodos de regularización. Repetir el proceso de detención anticipada muchas veces puede dar como resultado que el modelo sobreajuste el conjunto de datos de validación, de la misma manera que ocurre el sobreajuste en el caso de los datos de entrenamiento. Este método también es eficiente ya que requiere menos cantidad de datos de entrenamiento, que no siempre están disponibles. Debido a este hecho, la parada temprana requiere menos tiempo de entrenamiento en comparación con otros métodos de regularización. Repetir el proceso de detención anticipada muchas veces puede dar como resultado que el modelo sobreajuste el conjunto de datos de validación, de la misma manera que ocurre el sobreajuste en el caso de los datos de entrenamiento. Este método también es eficiente ya que requiere menos cantidad de datos de entrenamiento, que no siempre están disponibles. Debido a este hecho, la parada temprana requiere menos tiempo de entrenamiento en comparación con otros métodos de regularización. Repetir el proceso de detención anticipada muchas veces puede dar como resultado que el modelo sobreajuste el conjunto de datos de validación, de la misma manera que ocurre el sobreajuste en el caso de los datos de entrenamiento.
El número de iteraciones necesarias para entrenar el modelo puede considerarse un hiperparámetro . Luego, el modelo tiene que encontrar un valor óptimo para este hiperparámetro (mediante el ajuste de hiperparámetro) para el mejor rendimiento del modelo de aprendizaje.
Consejo: Las desventajas de detenerse antes de tiempo son las siguientes:
Al detenernos temprano, no podemos optimizar mucho la función de costo (J) para el conjunto de entrenamiento. Entonces, usamos un concepto diferente conocido como ortogonalización .
Publicación traducida automáticamente
Artículo escrito por irenecasmir y traducido por Barcelona Geeks. The original can be accessed here. Licence: CCBY-SA