Dado un conjunto de datos que comprende un grupo de puntos, encuentre el mejor ajuste que represente los datos.
A menudo tenemos un conjunto de datos que consta de datos que siguen una ruta general, pero cada dato tiene una desviación estándar que los hace dispersos en la línea de mejor ajuste. Podemos obtener una sola línea usando la función curve-fit().
Uso de SciPy:
Scipy es el módulo de computación científica de Python que proporciona funciones integradas en muchas funciones matemáticas conocidas. El paquete scipy.optimize nos proporciona múltiples procedimientos de optimización. Puede encontrar una lista detallada de todas las funcionalidades de Optimize escribiendo lo siguiente en la consola de iPython:
help(scipy.optimize)
Entre los más utilizados se encuentran la minimización por mínimos cuadrados, el ajuste de curvas, la minimización de funciones escalares multivariadas, etc.
Ejemplos de ajuste de curvas:
entrada:
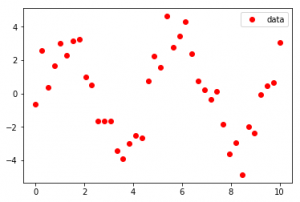
Producción :
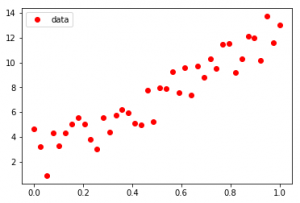
Aporte :
Producción :
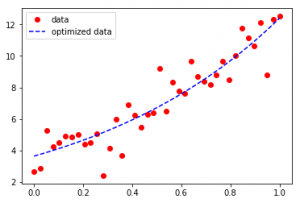
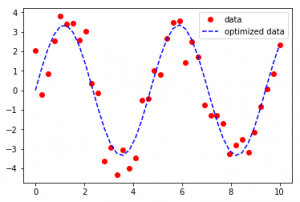
Como se ve en la entrada, el conjunto de datos parece estar disperso en una función sinusoidal en el primer caso y una función exponencial en el segundo caso, Curve-Fit da legitimidad a las funciones y determina los coeficientes para proporcionar la línea de mejor ajuste.
Código que muestra la generación del primer ejemplo:
Python3
import numpy as np
# curve-fit() function imported from scipy
from scipy.optimize import curve_fit
from matplotlib import pyplot as plt
# numpy.linspace with the given arguments
# produce an array of 40 numbers between 0
# and 10, both inclusive
x = np.linspace(0, 10, num = 40)
# y is another array which stores 3.45 times
# the sine of (values in x) * 1.334.
# The random.normal() draws random sample
# from normal (Gaussian) distribution to make
# them scatter across the base line
y = 3.45 * np.sin(1.334 * x) + np.random.normal(size = 40)
# Test function with coefficients as parameters
def test(x, a, b):
return a * np.sin(b * x)
# curve_fit() function takes the test-function
# x-data and y-data as argument and returns
# the coefficients a and b in param and
# the estimated covariance of param in param_cov
param, param_cov = curve_fit(test, x, y)
print("Sine function coefficients:")
print(param)
print("Covariance of coefficients:")
print(param_cov)
# ans stores the new y-data according to
# the coefficients given by curve-fit() function
ans = (param[0]*(np.sin(param[1]*x)))
'''Below 4 lines can be un-commented for plotting results
using matplotlib as shown in the first example. '''
# plt.plot(x, y, 'o', color ='red', label ="data")
# plt.plot(x, ans, '--', color ='blue', label ="optimized data")
# plt.legend()
# plt.show()
Sine function coefficients: [ 3.66474998 1.32876756] Covariance of coefficients: [[ 5.43766857e-02 -3.69114170e-05] [ -3.69114170e-05 1.02824503e-04]]
El segundo ejemplo se puede lograr usando la función exponencial numpy que se muestra a continuación:
Python3
x = np.linspace(0, 1, num = 40) y = 3.45 * np.exp(1.334 * x) + np.random.normal(size = 40) def test(x, a, b): return a*np.exp(b*x) param, param_cov = curve_fit(test, x, y)
Sin embargo, si los coeficientes son demasiado grandes, la curva se aplana y no proporciona el mejor ajuste. El siguiente código explica este hecho:
Python3
import numpy as np
from scipy.optimize import curve_fit
from matplotlib import pyplot as plt
x = np.linspace(0, 10, num = 40)
# The coefficients are much bigger.
y = 10.45 * np.sin(5.334 * x) + np.random.normal(size = 40)
def test(x, a, b):
return a * np.sin(b * x)
param, param_cov = curve_fit(test, x, y)
print("Sine function coefficients:")
print(param)
print("Covariance of coefficients:")
print(param_cov)
ans = (param[0]*(np.sin(param[1]*x)))
plt.plot(x, y, 'o', color ='red', label ="data")
plt.plot(x, ans, '--', color ='blue', label ="optimized data")
plt.legend()
plt.show()
Sine funcion coefficients: [ 0.70867169 0.7346216 ] Covariance of coefficients: [[ 2.87320136 -0.05245869] [-0.05245869 0.14094361]]
La línea de puntos azul es, sin duda, la línea con las distancias mejor optimizadas desde todos los puntos del conjunto de datos, pero no proporciona una función de seno con el mejor ajuste.
El ajuste de curvas no debe confundirse con la regresión. Ambos implican aproximar datos con funciones. Pero el objetivo del ajuste de curvas es obtener los valores de un conjunto de datos a través del cual un conjunto dado de variables explicativas puede representar otra variable. La regresión es un caso especial de ajuste de curvas, pero aquí simplemente no necesita una curva que se ajuste a los datos de entrenamiento de la mejor manera posible (lo que puede conducir a un sobreajuste), sino un modelo que pueda generalizar el aprendizaje y, por lo tanto, predecir nuevos puntos. eficientemente.
Publicación traducida automáticamente
Artículo escrito por ArijitGayen y traducido por Barcelona Geeks. The original can be accessed here. Licence: CCBY-SA