Hay muchas aplicaciones en las que los sitios web recopilan datos de sus usuarios y los usan para predecir los gustos y disgustos de sus usuarios. Esto les permite recomendar el contenido que les gusta. Los sistemas de recomendación son una forma de sugerir elementos e ideas similares a la forma de pensar específica de un usuario.
El sistema de recomendación es de diferentes tipos:
- Filtrado colaborativo: el filtrado colaborativo recomienda elementos en función de las medidas de similitud entre usuarios y/o elementos. La suposición básica detrás del algoritmo es que los usuarios con intereses similares tienen preferencias comunes.
- Recomendación basada en el contenido: es
Basado en el contenido de alta calificación
a ,
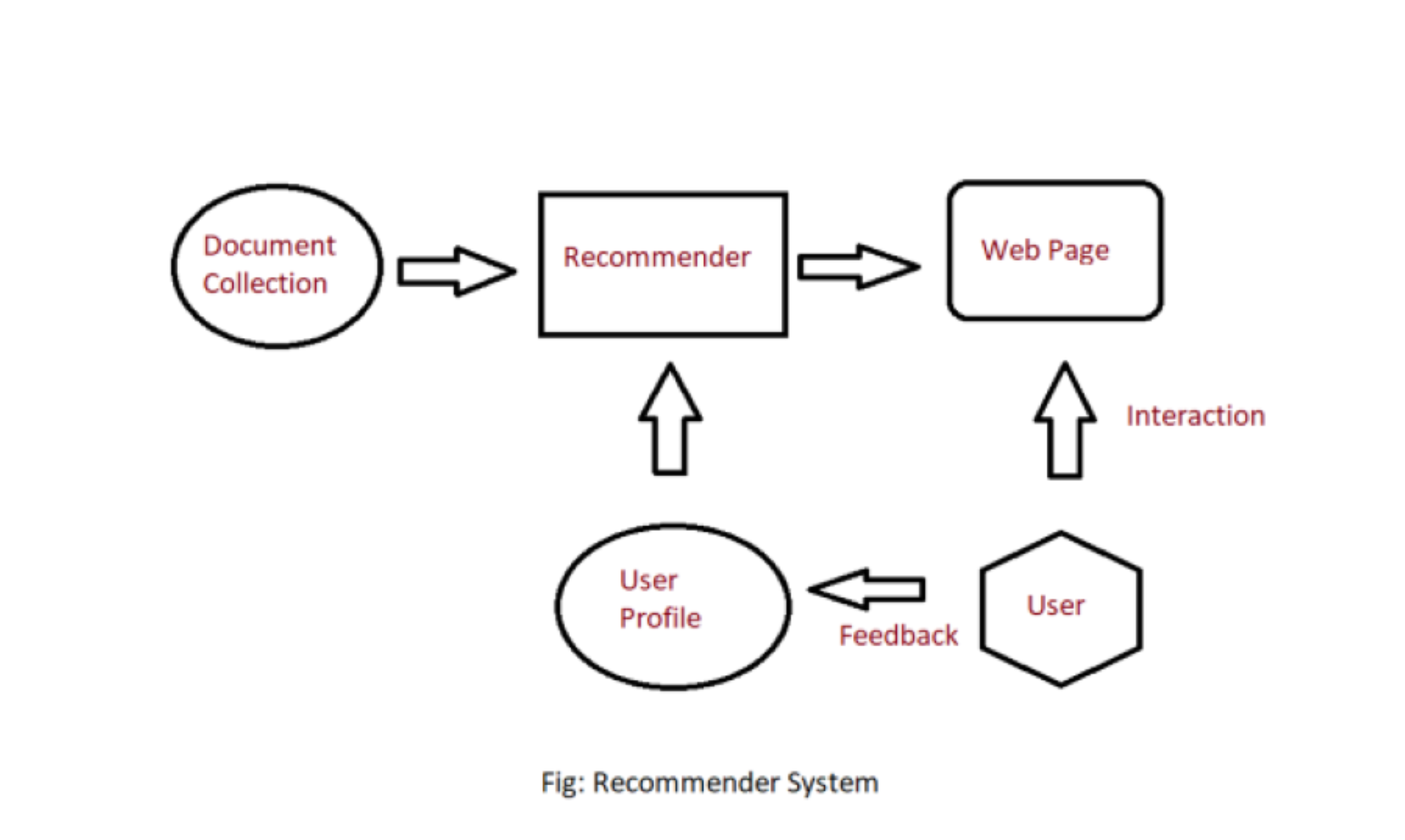
Sistema de recomendación basado en contenido
En un sistema de recomendación basado en el contenido, necesitamos crear un perfil para cada elemento, que contenga las propiedades importantes de cada elemento. Por ejemplo, si la película es un elemento, entonces,,,
Veamos cómo crear un perfil de artículo. Primero, necesitamos realizar el vectorizador TF-IDF, aquí TF (frecuencia de término)IDF (frecuencia de documento inversa)

donde f ij es la frecuencia del término (característica) i en el documento (elemento) j.

donde, n i número de documentos que mencionan el término i. N es el número total de documentos.

Aquí, doc profile es el conjunto de palabras con
Perfil del usuario:
El perfil de usuario es un vector que describe la preferencia del usuario. Durante la creación del perfil del usuario, utilizamos una array de utilidad que describe la relación entre el usuario y el artículo. A partir de esta información, la mejor estimación que podemos decidir es la
-
-
- No recomienda elementos fuera del perfil de usuario.
Filtrado colaborativo: el filtrado colaborativo se basa en la idea de que a las personas similares (según los datos) generalmente les gustan cosas similares. yo
preferenciaretroalimentación implícita
- escasoa vecescostos
- comportamiento
Ejemplo:
- Considere un usuario x, necesitamos encontrar otro usuario cuya calificación sea similar a la calificación de x, y luego estimamos la calificación de x en función de otro usuario.
| M_1 | M_2 | M_3 | M_4 | M_5 | M_6 | M_7 | |
|---|---|---|---|---|---|---|---|
| A | 4 | 5 | 1 | ||||
| B | 5 | 5 | 4 | 5 | |||
| C | 2 | 4 | |||||
| D | 3 | 3 |
- Vamos a crear una array que represente diferentes usuarios y películas:
- Considere dos usuarios x, y con vectores de calificación r x y r y . Necesitamos decidir una array de similitud para calcular la similitud b/w sim(x,y). Hay muchos métodos para calcular la similitud, tales como: similitud de Jaccard, similitud de coseno y similitud de Pearson. Aquí, usamos similitud de coseno centrado/similitud de Pearson, donde normalizamos la calificación restando la media:
| M_1 | M_2 | M_3 | M_4 | M_5 | M_6 | M_7 | |
|---|---|---|---|---|---|---|---|
| A | 2/3 | 5/3 | -7/3 | ||||
| B | 1/3 | 1/3 | -2/3 | ||||
| C | -5/3 | 1/3 | 4/3 | ||||
| D | 0 | 0 |
- Aquí, podemos calcular la similitud: Por ejemplo: sim(A,B) = cos(r A , r B ) = 0.09 ; sim(A,C) = -0.56. sim(A,B) > sim(A,C).
Predicciones de calificación
- Sea r x el vector de calificación del usuario x. Sea N el conjunto de k usuarios similares que también calificaron el ítem i. Luego podemos calcular la predicción del usuario x y el elemento i usando la siguiente fórmula:

-
- Capture características sutiles inherentes.
-
- No se pueden manipular artículos frescos debido a un problema de arranque en frío.
- Es difícil agregar nuevas características que puedan mejorar la calidad del modelo.
Implementación:
Python3
# code
import numpy as np
import pandas as pd
import sklearn
import matplotlib.pyplot as plt
import seaborn as sns
import warnings
warnings.simplefilter(action='ignore', category=FutureWarning)
ratings = pd.read_csv("https://s3-us-west-2.amazonaws.com/recommender-tutorial/ratings.csv")
ratings.head()
movies = pd.read_csv("https://s3-us-west-2.amazonaws.com/recommender-tutorial/movies.csv")
movies.head()
n_ratings = len(ratings)
n_movies = len(ratings['movieId'].unique())
n_users = len(ratings['userId'].unique())
print(f"Number of ratings: {n_ratings}")
print(f"Number of unique movieId's: {n_movies}")
print(f"Number of unique users: {n_users}")
print(f"Average ratings per user: {round(n_ratings/n_users, 2)}")
print(f"Average ratings per movie: {round(n_ratings/n_movies, 2)}")
user_freq = ratings[['userId', 'movieId']].groupby('userId').count().reset_index()
user_freq.columns = ['userId', 'n_ratings']
user_freq.head()
# Find Lowest and Highest rated movies:
mean_rating = ratings.groupby('movieId')[['rating']].mean()
# Lowest rated movies
lowest_rated = mean_rating['rating'].idxmin()
movies.loc[movies['movieId'] == lowest_rated]
# Highest rated movies
highest_rated = mean_rating['rating'].idxmax()
movies.loc[movies['movieId'] == highest_rated]
# show number of people who rated movies rated movie highest
ratings[ratings['movieId']==highest_rated]
# show number of people who rated movies rated movie lowest
ratings[ratings['movieId']==lowest_rated]
## the above movies has very low dataset. We will use bayesian average
movie_stats = ratings.groupby('movieId')[['rating']].agg(['count', 'mean'])
movie_stats.columns = movie_stats.columns.droplevel()
# Now, we create user-item matrix using scipy csr matrix
from scipy.sparse import csr_matrix
def create_matrix(df):
N = len(df['userId'].unique())
M = len(df['movieId'].unique())
# Map Ids to indices
user_mapper = dict(zip(np.unique(df["userId"]), list(range(N))))
movie_mapper = dict(zip(np.unique(df["movieId"]), list(range(M))))
# Map indices to IDs
user_inv_mapper = dict(zip(list(range(N)), np.unique(df["userId"])))
movie_inv_mapper = dict(zip(list(range(M)), np.unique(df["movieId"])))
user_index = [user_mapper[i] for i in df['userId']]
movie_index = [movie_mapper[i] for i in df['movieId']]
X = csr_matrix((df["rating"], (movie_index, user_index)), shape=(M, N))
return X, user_mapper, movie_mapper, user_inv_mapper, movie_inv_mapper
X, user_mapper, movie_mapper, user_inv_mapper, movie_inv_mapper = create_matrix(ratings)
from sklearn.neighbors import NearestNeighbors
"""
Find similar movies using KNN
"""
def find_similar_movies(movie_id, X, k, metric='cosine', show_distance=False):
neighbour_ids = []
movie_ind = movie_mapper[movie_id]
movie_vec = X[movie_ind]
k+=1
kNN = NearestNeighbors(n_neighbors=k, algorithm="brute", metric=metric)
kNN.fit(X)
movie_vec = movie_vec.reshape(1,-1)
neighbour = kNN.kneighbors(movie_vec, return_distance=show_distance)
for i in range(0,k):
n = neighbour.item(i)
neighbour_ids.append(movie_inv_mapper[n])
neighbour_ids.pop(0)
return neighbour_ids
movie_titles = dict(zip(movies['movieId'], movies['title']))
movie_id = 3
similar_ids = find_similar_movies(movie_id, X, k=10)
movie_title = movie_titles[movie_id]
print(f"Since you watched {movie_title}")
for i in similar_ids:
print(movie_titles[i])
Producción:
Number of ratings: 100836
Number of unique movieId's: 9724
Number of unique users: 610
Average number of ratings per user: 165.3
Average number of ratings per movie: 10.37
==========================================
# lowest rated
movieId title genres
2689 3604 Gypsy (1962) Musical
# highest rated
movieId title genres
48 53 Lamerica (1994) Adventure|Drama
# who rate highest rated movie
userId movieId rating timestamp
13368 85 53 5.0 889468268
96115 603 53 5.0 963180003
# who rate lowest rated movie
userId movieId rating timestamp
13633 89 3604 0.5 1520408880
Since you watched Grumpier Old Men (1995)
Grumpy Old Men (1993)
Striptease (1996)
Nutty Professor, The (1996)
Twister (1996)
Father of the Bride Part II (1995)
Broken Arrow (1996)
Bio-Dome (1996)
Truth About Cats & Dogs, The (1996)
Sabrina (1995)
Birdcage, The (1996