La noción de conjuntos brutosfue presentado por Z Pawlak en su artículo seminal de 1982 (Pawlak 1982). Es una teoría formal derivada de la investigación fundamental sobre las propiedades lógicas de los sistemas de información. La teoría de conjuntos aproximados ha sido una metodología de minería de bases de datos o descubrimiento de conocimiento en bases de datos relacionales. En su forma abstracta, es una nueva área de las matemáticas de la incertidumbre estrechamente relacionada con la teoría difusa. Podemos utilizar un enfoque de conjunto aproximado para descubrir la relación estructural dentro de datos imprecisos y ruidosos. Los conjuntos aproximados y los conjuntos borrosos son generalizaciones complementarias de los conjuntos clásicos. Los espacios de aproximación de la teoría de conjuntos aproximados son conjuntos con pertenencias múltiples, mientras que los conjuntos borrosos se ocupan de pertenencias parciales. El rápido desarrollo de estos dos enfoques proporciona una base para la «computación suave», iniciada por Lotfi A. Zadeh. Soft Computing incluye, junto con conjuntos preliminares,
Problemas básicos en análisis de datos resueltos por Rough Set:
- Caracterización de un conjunto de objetos en términos de valores de atributo.
- Encontrar dependencia entre los atributos.
- Reducción de atributos superfluos.
- Encontrar los atributos más significativos.
- Generación de reglas de decisión.
Objetivos de la teoría de conjuntos aproximados:
- El objetivo principal del análisis de conjuntos aproximados es la inducción de (aprendizaje) aproximaciones de conceptos. Los conjuntos en bruto constituyen una base sólida para KDD. Ofrece herramientas matemáticas para descubrir patrones ocultos en los datos.
- Se puede utilizar para la selección de funciones, la extracción de funciones, la reducción de datos, la generación de reglas de decisión y la extracción de patrones (plantillas, reglas de asociación), etc.
- Identifica dependencias parciales o totales en los datos, elimina datos redundantes, da aproximación a valores nulos, datos faltantes, datos dinámicos y otros.
Sistema de informacion –
En Rough Set, la información del modelo de datos se almacena en una tabla. Cada fila (tuplas) representa un hecho o un objeto. A menudo los hechos no son consistentes entre sí. En la terminología de conjunto aproximado, una tabla de datos se denomina sistema de información. Por lo tanto, la tabla de información representa datos de entrada, recopilados de cualquier dominio.
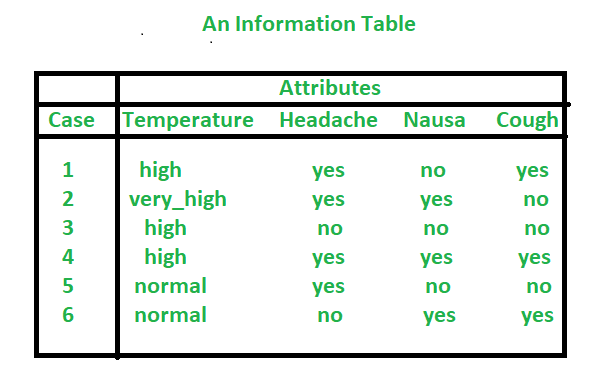
Nota: Las filas de una tabla se denominan ejemplos (objetos, entidades). El sistema de información es un par (U, A), U es un conjunto finito no vacío de objetos y A es un conjunto finito no vacío de atributos. Los elementos de A se denominan atributos condicionales. Una tabla de información a veces llamada tabla de decisión cuando contiene atributo/atributos de decisión. El sistema de decisión es un par de (U, A unión {d}), donde d es un atributo de decisión (en lugar de uno podemos considerar más atributos de decisión).
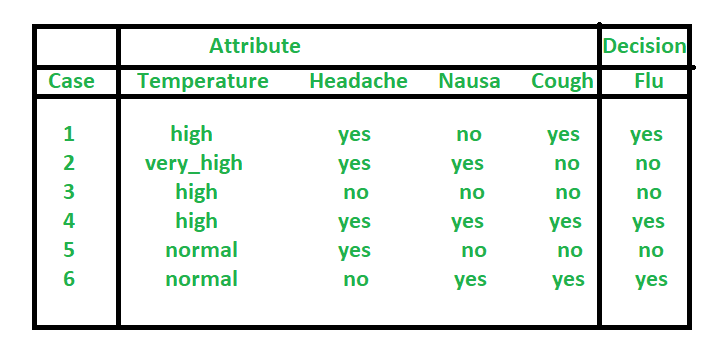
Indiscernibilidad –
Las tablas pueden contener muchos objetos que tienen las mismas características. Una forma de reducir el tamaño de la tabla es almacenar solo un objeto representativo para cada conjunto de objetos con las mismas características. Estos objetos se denominan objetos indiscernibles o tuplas. Con cualquier P subconjunto A existe una relación de equivalencia asociada IND(P): 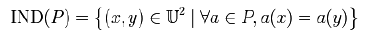 Donde IND(P) se denomina indiscernibilidad de la relación. Aquí x e y son indiscernibles entre sí por el atributo P.
Donde IND(P) se denomina indiscernibilidad de la relación. Aquí x e y son indiscernibles entre sí por el atributo P.  En el ejemplo anterior,
En el ejemplo anterior,
IND({p1}) = {{O1, O2}, {O3, O5, O7, O9, O10}, {O4, O6, O8}} O1 y O2 se caracterizan por los mismos valores del atributo p1 y el valor es 1. O3, O5, O7, O9, O10 se caracterizan por el mismo valor del atributo p1 y el valor es 2. O4, O6, O8 se caracterizan por el mismo valor del atributo p1 y el valor es 0.
La relación de indiscernibilidad es una relación de equivalencia. Los conjuntos que son imperceptibles se llaman conjuntos elementales.
Aproximaciones –
Es una aproximación formal de un conjunto nítido definido por sus dos aproximaciones: aproximación superior y aproximación inferior .
- La aproximación superior es el conjunto de objetos que posiblemente pertenecen al conjunto objetivo.

- La aproximación inferior es el conjunto de objetos que pertenecen positivamente al conjunto objetivo.
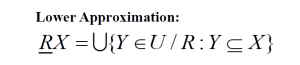
representa la región positiva que contiene los objetos que definitivamente pertenecen al conjunto objetivo X.
representa la región negativa que contiene los objetos que pueden descartarse definitivamente como miembros del conjunto objetivo X.
representa la región límite que contiene los objetos que pueden o no puede no pertenecer al conjunto objetivo X.
Se dice que un conjunto es aproximado si su región límite no está vacía, de lo contrario, el conjunto es nítido.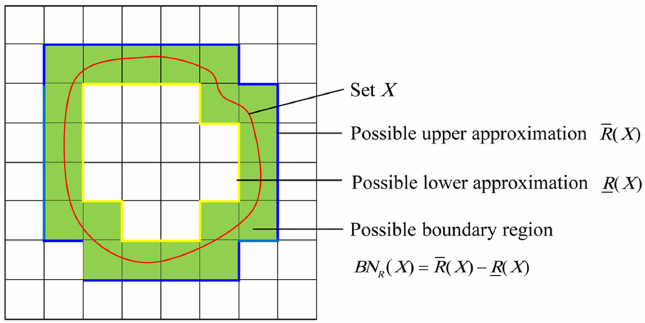
Analicemos un ejemplo. la tabla anterior se toma como tabla de información.
Referencias: http://zsi.tech.us.edu.pl/~nowak/bien/w2.pdf https://www.sciencedirect.com/science/article/pii/S2468232216300786 https://www.mimuw.edu .pl/~son/datamining/RSDM/Intro.pdf
Publicación traducida automáticamente
Artículo escrito por Avik_Dutta y traducido por Barcelona Geeks. The original can be accessed here. Licence: CCBY-SA