Tpot es un paquete de aprendizaje automático automatizado en python que utiliza conceptos de programación genética para optimizar la tubería de aprendizaje automático. Automatiza la parte más tediosa del aprendizaje automático mediante la exploración inteligente de miles de posibles para encontrar el mejor parámetro posible que se adapte a sus datos. Tpot es Tpot se basa en scikit-learn, por lo que su código se parece a scikit-learn.
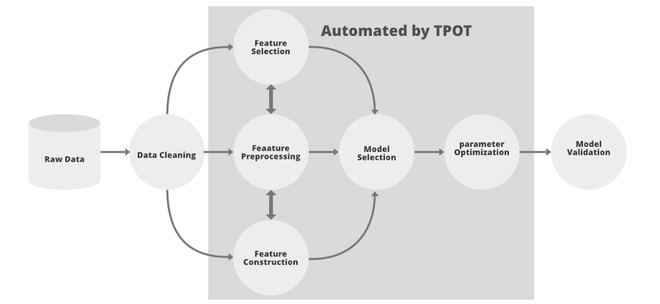
Partes de la canalización de ML automatizadas por Tpot
Tpot usa programación genética para generar el espacio de búsqueda optimizado, están inspirados en la idea de Darwin de la selección natural, la programación genética usa las siguientes propiedades:
- Selección: En esta etapa se evalúa la función de aptitud en cada uno de los individuos y se normalizan sus valores, de manera que cada uno de ellos tenga valores entre 0 y 1 y su suma sea 1. Luego de eso, se decide un número aleatorio R b/w 0 y 1. Ahora, nos quedamos con aquellos individuos cuyo valor de función de aptitud sea mayor o igual a R.
- Cruce: ahora, podemos seleccionar los individuos más aptos de arriba y realizar un cruce entre ellos para generar una nueva población.
- Mutación: Mute los individuos generados por el cruce y realice algunas modificaciones aleatorias y repítalo durante unos pocos pasos o hasta que obtengamos la mejor población.
A continuación se presentan algunas funciones importantes de Tpot:
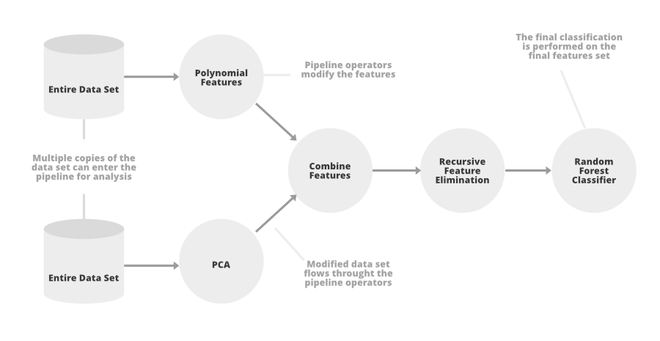
Tubería TpoT
- TpotClassifier: módulo para realizar aprendizaje automático para la tarea de clasificación supervisada. A continuación se presentan algunos argumentos importantes que se necesitan:
- generaciones : número de iteraciones para ejecutar el proceso de canalización (predeterminado: 100).
- población_tamaño : número de individuos para retener la población de programación genética cada generación (por defecto 100).
- offspring_size : número de descendientes a generar en cada iteración de programación genética. (predeterminado 100).
- tasa_mutación : tasa de mutación b/n [0,1] (predeterminado 0.9)
- crossover_rate: tasa de cruce b/n [0,1] (predeterminado 0.1) {tasa de mutación + tasa de cruce <= 1}.
- Scoring : métricas para evaluar la calidad del pipeline. Aquí la puntuación toma parámetros como Precisión, puntuación F1, etc.
- cv : método de validación cruzada, si el valor dado es Integer, entonces será K en la validación cruzada K-Fold.
- n_job : número de procesos que se pueden ejecutar en paralelo (por defecto 1).
- max_time_mins : tiempo máximo que Tpot permitió optimizar la canalización (predeterminado: Ninguno).
- max_eval_time_mins : (predeterminado: ninguno).
- verbosidad:
- TpotRegressor: módulo para realizar aprendizaje profundo automatizado para tareas de regresión. La mayoría de los argumentos son comunes a la descripción anterior de TpotClassifier. Aquí el único parámetro que es diferente es la puntuación . En TpotRegression, necesitamos evaluar la regresión, por lo que usamos parámetros como:
Ambos módulos proporcionan 4 funciones para ajustar y evaluar el conjunto de datos. Estos son:
- fit(features, target): Ejecute la canalización de optimización de TPOT en los datos proporcionados.
- predecir (características): use la canalización optimizada para predecir los valores objetivo de un ejemplo/ejemplos de conjunto de características.
- score(test_features, test_target): evalúa el modelo en los datos de prueba y devuelve la puntuación más optimizada generada
- export(output_file_name): exporta la canalización optimizada como código python.
Implementación
- En esta implementación, usaremos el conjunto de datos de viviendas de Boston y usaremos ‘neg_mean_squared error’ como nuestra función de puntuación.
Python3
# install TPot and other dependencies
!pip install sklearn fsspec xgboost
%pip install -U distributed scikit-learn dask-ml dask-glm
%pip install "tornado>=5"
%pip install "dask[complete]"
!pip install TPOT
# import required modules
from tpot import TPOTRegressor
from sklearn.datasets import load_boston
from sklearn.model_selection import train_test_split
import numpy as np
# load boston dataset
X, y = load_boston(return_X_y=True)
# divide the data into train and test
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size= .25)
# define TpotRegressor
reg = TPOTRegressor(verbosity=2, population_size=50, generations=10, random_state=35)
# fit the regressor on training data
reg.fit(X_train, y_train)
# print the results on test data
print(reg.score(X_test, y_test))
#save the model in top_boston.py
reg.export('top_boston.py')
Generation 1 - Current best internal CV score: -13.196955982336481 Generation 2 - Current best internal CV score: -13.196955982336481 Generation 3 - Current best internal CV score: -13.196955982336481 Generation 4 - Current best internal CV score: -13.196015224855723 Generation 5 - Current best internal CV score: -13.143264025811806 Generation 6 - Current best internal CV score: -12.800705944988994 Generation 7 - Current best internal CV score: -12.717234303495596 Generation 8 - Current best internal CV score: -12.717234303495596 Generation 9 - Current best internal CV score: -11.707932909438588 Generation 10 - Current best internal CV score: -11.707932909438588 Best pipeline: ExtraTreesRegressor(input_matrix, bootstrap=False, max_features=0.7000000000000001, min_samples_leaf=1, min_samples_split=3, n_estimators=100) -8.098697897637797
- Ahora, miramos el archivo generado por TpotRegressor, es decir: el archivo contiene código para leer datos usando pandas y el modelo para el mejor regresor.
#tpot_boston.py
import numpy as np
import pandas as pd
from sklearn.ensemble import ExtraTreesRegressor
from sklearn.model_selection import train_test_split
# NOTE: Make sure that the outcome column is labeled 'target' in the data file
tpot_data = pd.read_csv('PATH/TO/DATA/FILE', sep='COLUMN_SEPARATOR', dtype=np.float64)
features = tpot_data.drop('target', axis=1)
training_features, testing_features, training_target, testing_target = \
train_test_split(features, tpot_data['target'], random_state=35)
# Average CV score on the training set was: -11.707932909438588
exported_pipeline = ExtraTreesRegressor(bootstrap=False, max_features=0.7000000000000001,
min_samples_leaf=1, min_samples_split=3, n_estimators=100)
# Fix random state in exported estimator
if hasattr(exported_pipeline, 'random_state'):
setattr(exported_pipeline, 'random_state', 35)
exported_pipeline.fit(training_features, training_target)
results = exported_pipeline.predict(testing_features)