Los datos faltantes pueden ocurrir cuando no se proporciona información para uno o más elementos o para una unidad completa. La falta de datos es un problema muy grande en escenarios de la vida real. Los datos faltantes también pueden referirse a valores NA (no disponibles) en pandas. En DataFrame, a veces, muchos conjuntos de datos simplemente llegan con datos faltantes, ya sea porque existen y no se recopilaron o porque nunca existieron. Por ejemplo, suponga que diferentes usuarios encuestados pueden optar por no compartir sus ingresos, algunos usuarios pueden optar por no compartir la dirección de esta manera, muchos conjuntos de datos desaparecieron.  En Pandas, los datos que faltan están representados por dos valores:
En Pandas, los datos que faltan están representados por dos valores:
- Ninguno: Ninguno es un objeto único de Python que a menudo se usa para datos faltantes en el código de Python.
- NaN: NaN (un acrónimo de Not a Number), es un valor especial de punto flotante reconocido por todos los sistemas que utilizan la representación estándar de punto flotante IEEE
Pandas trata a None y NaN como esencialmente intercambiables para indicar valores faltantes o nulos. Para facilitar esta convención, existen varias funciones útiles para detectar, eliminar y reemplazar valores nulos en Pandas DataFrame:
En este artículo estamos usando un archivo CSV, para descargar el archivo CSV usado, haga clic aquí .
Comprobación de valores faltantes usando isnull() y notnull()
Para verificar los valores faltantes en Pandas DataFrame, usamos una función isnull() y notnull(). Ambas funciones ayudan a verificar si un valor es NaN o no. Esta función también se puede usar en Pandas Series para encontrar valores nulos en una serie.
Comprobación de valores faltantes usando isnull()
Para verificar los valores nulos en Pandas DataFrame, usamos la función isnull(), esta función devuelve un marco de datos de valores booleanos que son verdaderos para los valores NaN. Código #1:
Python
# importing pandas as pd
import pandas as pd
# importing numpy as np
import numpy as np
# dictionary of lists
dict = {'First Score':[100, 90, np.nan, 95],
'Second Score': [30, 45, 56, np.nan],
'Third Score':[np.nan, 40, 80, 98]}
# creating a dataframe from list
df = pd.DataFrame(dict)
# using isnull() function
df.isnull()
Salida: 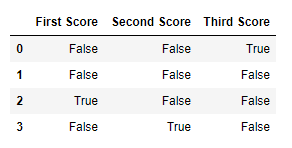 Código #2:
Código #2:
Python
# importing pandas package
import pandas as pd
# making data frame from csv file
data = pd.read_csv("employees.csv")
# creating bool series True for NaN values
bool_series = pd.isnull(data["Gender"])
# filtering data
# displaying data only with Gender = NaN
data[bool_series]
Salida: como se muestra en la imagen de salida, solo se muestran las filas que tienen Género = NULL.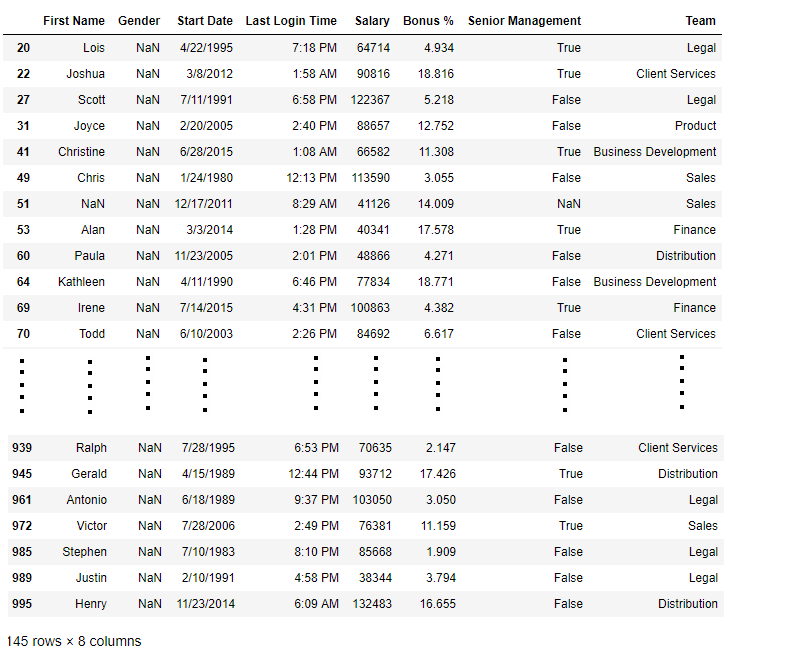
Comprobación de valores faltantes usando notnull()
Para verificar los valores nulos en Pandas Dataframe, usamos la función notnull(), esta función devuelve el marco de datos de valores booleanos que son falsos para los valores NaN. Código #3:
Python
# importing pandas as pd
import pandas as pd
# importing numpy as np
import numpy as np
# dictionary of lists
dict = {'First Score':[100, 90, np.nan, 95],
'Second Score': [30, 45, 56, np.nan],
'Third Score':[np.nan, 40, 80, 98]}
# creating a dataframe using dictionary
df = pd.DataFrame(dict)
# using notnull() function
df.notnull()
Salida: 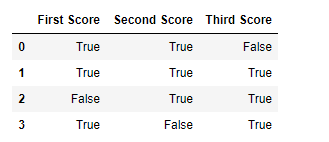 Código #4:
Código #4:
Python
# importing pandas package
import pandas as pd
# making data frame from csv file
data = pd.read_csv("employees.csv")
# creating bool series True for NaN values
bool_series = pd.notnull(data["Gender"])
# filtering data
# displaying data only with Gender = Not NaN
data[bool_series]
Salida: como se muestra en la imagen de salida, solo se muestran las filas que tienen Sexo = NO NULO.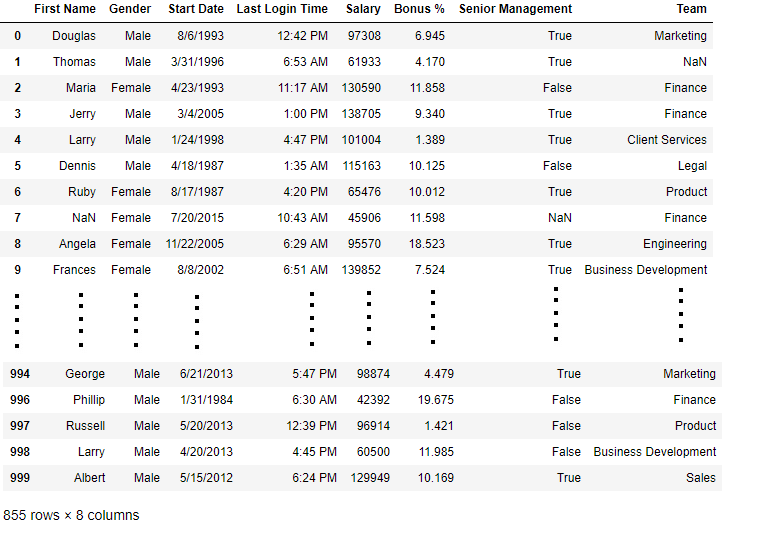
Rellenar valores faltantes usando fillna(), replace() e interpolate()
Para completar los valores nulos en un conjunto de datos, usamos las funciones fillna(), replace() e interpolate(). Estas funciones reemplazan los valores NaN con algún valor propio. Todas estas funciones ayudan a llenar valores nulos en conjuntos de datos de un DataFrame. La función Interpolate() se usa básicamente para completar los valores NA en el marco de datos, pero utiliza varias técnicas de interpolación para completar los valores faltantes en lugar de codificar el valor. Código #1: Llenar valores nulos con un solo valor
Python
# importing pandas as pd
import pandas as pd
# importing numpy as np
import numpy as np
# dictionary of lists
dict = {'First Score':[100, 90, np.nan, 95],
'Second Score': [30, 45, 56, np.nan],
'Third Score':[np.nan, 40, 80, 98]}
# creating a dataframe from dictionary
df = pd.DataFrame(dict)
# filling missing value using fillna()
df.fillna(0)
Salida: 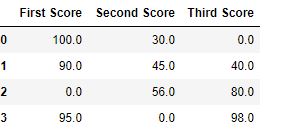 Código #2: Llenar valores nulos con los anteriores
Código #2: Llenar valores nulos con los anteriores
Python
# importing pandas as pd
import pandas as pd
# importing numpy as np
import numpy as np
# dictionary of lists
dict = {'First Score':[100, 90, np.nan, 95],
'Second Score': [30, 45, 56, np.nan],
'Third Score':[np.nan, 40, 80, 98]}
# creating a dataframe from dictionary
df = pd.DataFrame(dict)
# filling a missing value with
# previous ones
df.fillna(method ='pad')
Salida: 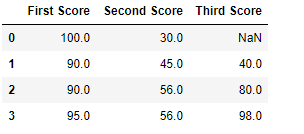 Código #3: Relleno de valor nulo con los siguientes
Código #3: Relleno de valor nulo con los siguientes
Python
# importing pandas as pd
import pandas as pd
# importing numpy as np
import numpy as np
# dictionary of lists
dict = {'First Score':[100, 90, np.nan, 95],
'Second Score': [30, 45, 56, np.nan],
'Third Score':[np.nan, 40, 80, 98]}
# creating a dataframe from dictionary
df = pd.DataFrame(dict)
# filling null value using fillna() function
df.fillna(method ='bfill')
Salida: 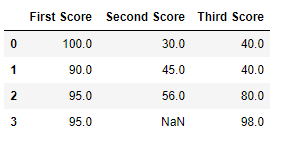 Código #4: Relleno de valores nulos en el archivo CSV
Código #4: Relleno de valores nulos en el archivo CSV
Python
# importing pandas package
import pandas as pd
# making data frame from csv file
data = pd.read_csv("employees.csv")
# Printing the first 10 to 24 rows of
# the data frame for visualization
data[10:25]
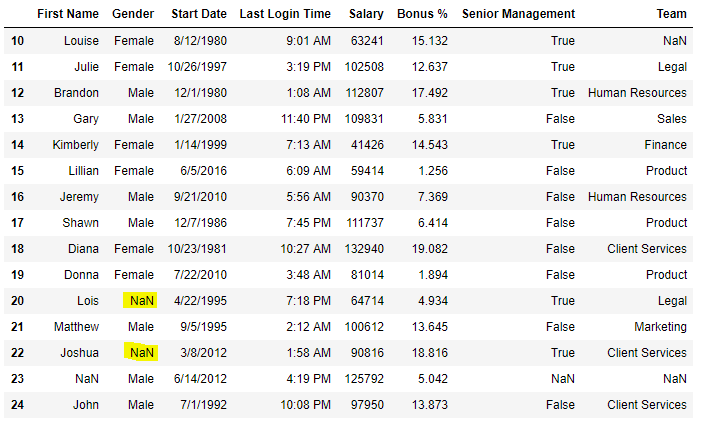 Now we are going to fill all the null values in Gender column with “No Gender”
Now we are going to fill all the null values in Gender column with “No Gender”
Python
# importing pandas package
import pandas as pd
# making data frame from csv file
data = pd.read_csv("employees.csv")
# filling a null values using fillna()
data["Gender"].fillna("No Gender", inplace = True)
data
Salida: 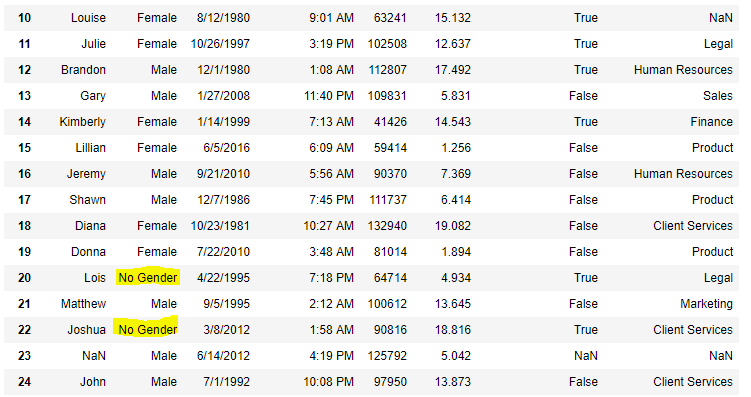 Código #5: Llenar valores nulos usando el método replace()
Código #5: Llenar valores nulos usando el método replace()
Python
# importing pandas package
import pandas as pd
# making data frame from csv file
data = pd.read_csv("employees.csv")
# Printing the first 10 to 24 rows of
# the data frame for visualization
data[10:25]
Salida: 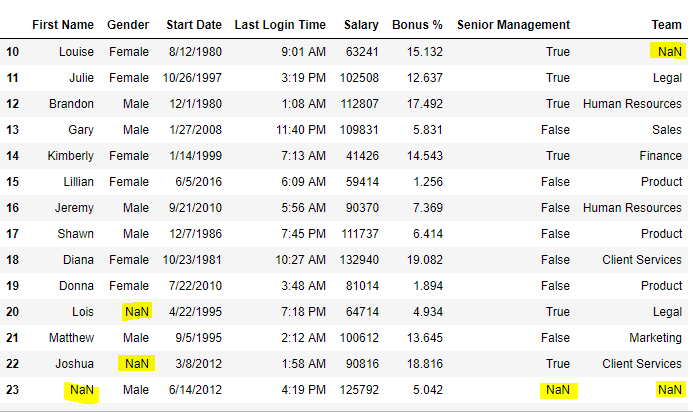 ahora vamos a reemplazar todo el valor de Nan en el marco de datos con un valor de -99.
ahora vamos a reemplazar todo el valor de Nan en el marco de datos con un valor de -99.
Python
# importing pandas package
import pandas as pd
# making data frame from csv file
data = pd.read_csv("employees.csv")
# will replace Nan value in dataframe with value -99
data.replace(to_replace = np.nan, value = -99)
Salida: 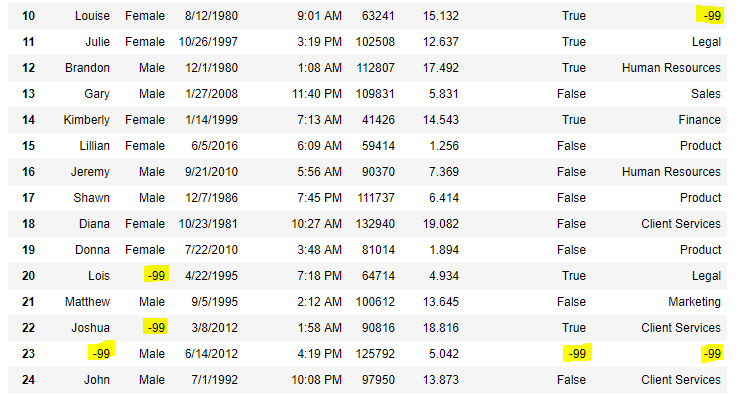 Código #6: Usar la función interpolar() para llenar los valores que faltan usando el método lineal.
Código #6: Usar la función interpolar() para llenar los valores que faltan usando el método lineal.
Python
# importing pandas as pd
import pandas as pd
# Creating the dataframe
df = pd.DataFrame({"A":[12, 4, 5, None, 1],
"B":[None, 2, 54, 3, None],
"C":[20, 16, None, 3, 8],
"D":[14, 3, None, None, 6]})
# Print the dataframe
df
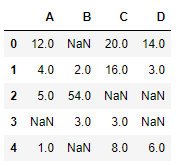 Let’s interpolate the missing values using Linear method. Note that Linear method ignore the index and treat the values as equally spaced.
Let’s interpolate the missing values using Linear method. Note that Linear method ignore the index and treat the values as equally spaced.
Python
# to interpolate the missing values df.interpolate(method ='linear', limit_direction ='forward')
Salida: 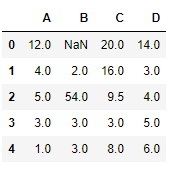 como podemos ver en la salida, los valores de la primera fila no se pudieron completar porque la dirección de llenado de los valores es hacia adelante y no hay un valor anterior que se haya podido usar en la interpolación.
como podemos ver en la salida, los valores de la primera fila no se pudieron completar porque la dirección de llenado de los valores es hacia adelante y no hay un valor anterior que se haya podido usar en la interpolación.
Descartar valores perdidos usando dropna()
Para eliminar valores nulos de un marco de datos, utilizamos la función dropna(), esta función elimina filas/columnas de conjuntos de datos con valores nulos de diferentes maneras. Código n. ° 1: eliminar filas con al menos 1 valor nulo.
Python
# importing pandas as pd
import pandas as pd
# importing numpy as np
import numpy as np
# dictionary of lists
dict = {'First Score':[100, 90, np.nan, 95],
'Second Score': [30, np.nan, 45, 56],
'Third Score':[52, 40, 80, 98],
'Fourth Score':[np.nan, np.nan, np.nan, 65]}
# creating a dataframe from dictionary
df = pd.DataFrame(dict)
df
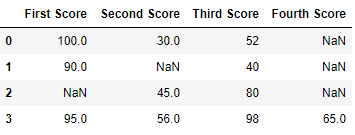 Now we drop rows with at least one Nan value (Null value)
Now we drop rows with at least one Nan value (Null value)
Python
# importing pandas as pd
import pandas as pd
# importing numpy as np
import numpy as np
# dictionary of lists
dict = {'First Score':[100, 90, np.nan, 95],
'Second Score': [30, np.nan, 45, 56],
'Third Score':[52, 40, 80, 98],
'Fourth Score':[np.nan, np.nan, np.nan, 65]}
# creating a dataframe from dictionary
df = pd.DataFrame(dict)
# using dropna() function
df.dropna()
Salida:  Código #2: Eliminar filas si faltan todos los valores en esa fila.
Código #2: Eliminar filas si faltan todos los valores en esa fila.
Python
# importing pandas as pd
import pandas as pd
# importing numpy as np
import numpy as np
# dictionary of lists
dict = {'First Score':[100, np.nan, np.nan, 95],
'Second Score': [30, np.nan, 45, 56],
'Third Score':[52, np.nan, 80, 98],
'Fourth Score':[np.nan, np.nan, np.nan, 65]}
# creating a dataframe from dictionary
df = pd.DataFrame(dict)
df
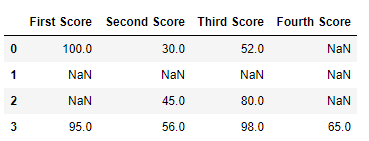 Now we drop a rows whose all data is missing or contain null values(NaN)
Now we drop a rows whose all data is missing or contain null values(NaN)
Python
# importing pandas as pd
import pandas as pd
# importing numpy as np
import numpy as np
# dictionary of lists
dict = {'First Score':[100, np.nan, np.nan, 95],
'Second Score': [30, np.nan, 45, 56],
'Third Score':[52, np.nan, 80, 98],
'Fourth Score':[np.nan, np.nan, np.nan, 65]}
df = pd.DataFrame(dict)
# using dropna() function
df.dropna(how = 'all')
Salida: 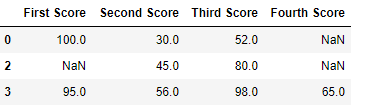 Código #3: Eliminación de columnas con al menos 1 valor nulo.
Código #3: Eliminación de columnas con al menos 1 valor nulo.
Python
# importing pandas as pd
import pandas as pd
# importing numpy as np
import numpy as np
# dictionary of lists
dict = {'First Score':[100, np.nan, np.nan, 95],
'Second Score': [30, np.nan, 45, 56],
'Third Score':[52, np.nan, 80, 98],
'Fourth Score':[60, 67, 68, 65]}
# creating a dataframe from dictionary
df = pd.DataFrame(dict)
df
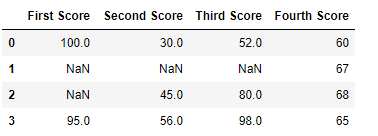 Now we drop a columns which have at least 1 missing values
Now we drop a columns which have at least 1 missing values
Python
# importing pandas as pd
import pandas as pd
# importing numpy as np
import numpy as np
# dictionary of lists
dict = {'First Score':[100, np.nan, np.nan, 95],
'Second Score': [30, np.nan, 45, 56],
'Third Score':[52, np.nan, 80, 98],
'Fourth Score':[60, 67, 68, 65]}
# creating a dataframe from dictionary
df = pd.DataFrame(dict)
# using dropna() function
df.dropna(axis = 1)
Salida: 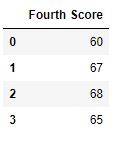 Código n. ° 4: filas descartadas con al menos 1 valor nulo en el archivo CSV
Código n. ° 4: filas descartadas con al menos 1 valor nulo en el archivo CSV
Python
# importing pandas module
import pandas as pd
# making data frame from csv file
data = pd.read_csv("employees.csv")
# making new data frame with dropped NA values
new_data = data.dropna(axis = 0, how ='any')
new_data
Salida: 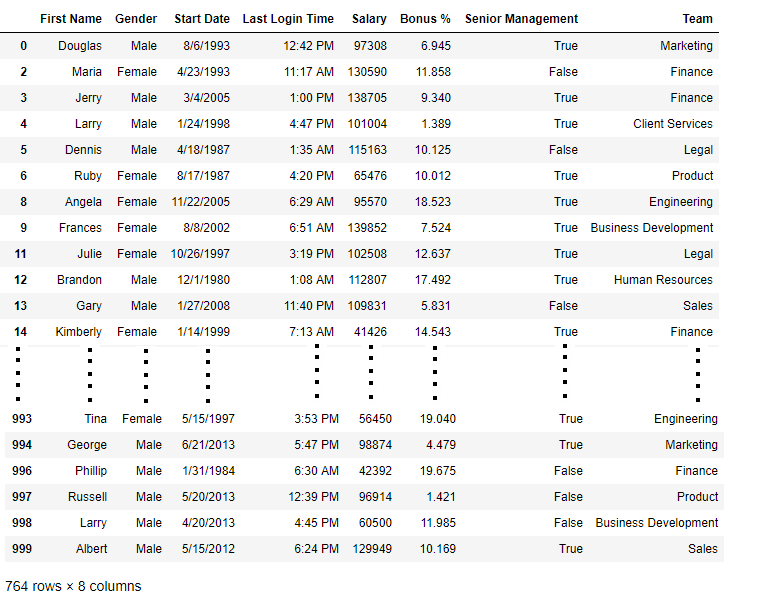 ahora comparamos los tamaños de los marcos de datos para que podamos saber cuántas filas tenían al menos 1 valor nulo
ahora comparamos los tamaños de los marcos de datos para que podamos saber cuántas filas tenían al menos 1 valor nulo
Python
print("Old data frame length:", len(data))
print("New data frame length:", len(new_data))
print("Number of rows with at least 1 NA value: ", (len(data)-len(new_data)))
Producción :
Old data frame length: 1000 New data frame length: 764 Number of rows with at least 1 NA value: 236
Dado que la diferencia es 236, había 236 filas que tenían al menos 1 valor nulo en cualquier columna.
Publicación traducida automáticamente
Artículo escrito por GeeksforGeeks-1 y traducido por Barcelona Geeks. The original can be accessed here. Licence: CCBY-SA