Este tutorial le proporcionará un recorrido por la biblioteca Gensim .
Gensim : Es una biblioteca de código abierto en python escrita por Radim Rehurek que se utiliza en el modelado de temas no supervisados y procesamiento de lenguaje natural . Está diseñado para extraer temas semánticos de los documentos. Puede manejar grandes colecciones de texto. Por lo tanto, lo hace diferente de otros paquetes de software de aprendizaje automático que se enfocan en el procesamiento de la memoria. Gensim también proporciona implementaciones multinúcleo eficientes para varios algoritmos para aumentar la velocidad de procesamiento. Proporciona instalaciones más convenientes para el procesamiento de texto que otros paquetes como Scikit-learn, R, etc.
Este tutorial cubrirá estos conceptos:
- Crear un Corpus a partir de un conjunto de datos dado
- Crear una array TFIDF en Gensim
- Crea bigramas y trigramas con Gensim
- Crear modelo de Word2Vec usando Gensim
- Crear modelo Doc2Vec usando Gensim
- Crear modelo de tema con LDA
- Crear modelo de tema con LSI
- Calcular arrays de similitud
- Resumir documentos de texto
Entendamos qué significan algunos de los términos mencionados a continuación antes de seguir adelante.
- Corpus: Una colección de documentos de texto.
- Vector: Forma de representar texto.
- Modelo: Algoritmo utilizado para generar la representación de datos.
- Modelado de temas: es una herramienta de minería de información que se utiliza para extraer temas semánticos de los documentos.
- Tema: Un grupo repetitivo de palabras que ocurren juntas con frecuencia.
For example:
You have a document which consists of words like -
bat, car, racquet, score, glass, drive, cup, keys, water, game, steering, liquid
These can be grouped into different topics as-
| Tema 1 | Tema 2 | Tema 3 |
|---|---|---|
| vidrio | murciélago | coche |
| taza | raqueta | conducir |
| agua | puntaje | llaves |
| líquido | juego | direccion |
Algunas de las técnicas de modelado de temas son:
- Indexación semántica latente (LSI)
- Asignación latente de Dirichlet (LDA)
Ahora que tenemos la idea básica de la terminología, comencemos con el uso del paquete Gensim.
Primero instale la biblioteca usando los comandos-
#for linux #for anaconda prompt
Paso 1: crear un corpus a partir de un conjunto de datos determinado Debe
seguir estos pasos para crear su corpus:
- Cargue su conjunto de datos
- Preprocesar el conjunto de datos
- Crear un Diccionario
- Crear Bolsa de Corpus de Palabras
1.1 Cargue su conjunto de datos:
puede tener un archivo .txt como su conjunto de datos o también puede cargar conjuntos de datos utilizando la API de descarga de Gensim . Código:
python3
import os
# open the text file as an object
doc = open('sample_data.txt', encoding ='utf-8')
- Gensim Downloader API: este es un módulo disponible en la biblioteca Gensim que es una API para descargar, obtener información y cargar conjuntos de datos/modelos.
Código:
python3
import gensim.downloader as api
# check available models and datasets
info_datasets = api.info()
print(info_datasets)
#>{'corpora':
#> {'semeval-2016-2017-task3-subtaskBC':
#> {'num_records': -1, 'record_format': 'dict', 'file_size': 6344358, ....}
# information of a particular dataset
dataset_info = api.info("text8")
# load the "text8" dataset
dataset = api.load("text8")
# load a pre-trained model
word2vec_model = api.load('word2vec-google-news-300')
Aquí vamos a considerar un archivo de texto como un conjunto de datos sin procesar que consiste en datos de una página de wikipedia.
1.2 Preprocesamiento del conjunto de datos Preprocesamiento de
texto: en el preprocesamiento de lenguaje natural, el preprocesamiento de texto es la práctica de limpiar y preparar datos de texto. Para este propósito usaremos la función simple_preprocess(). Esta función devuelve una lista de tokens después de tokenizarlos y normalizarlos.
Código:
python3
import gensim
import os
from gensim.utils import simple_preprocess
# open the text file as an object
doc = open('sample_data.txt', encoding ='utf-8')
# preprocess the file to get a list of tokens
tokenized =[]
for sentence in doc.read().split('.'):
# the simple_preprocess function returns a list of each sentence
tokenized.append(simple_preprocess(sentence, deacc = True))
print(tokenized)
Producción:
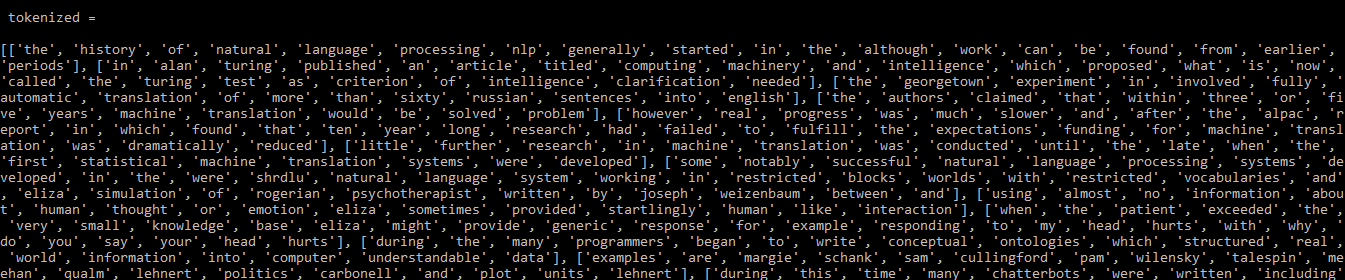
Salida: tokenizada
1.3 Crear un diccionario
Ahora tenemos nuestros datos preprocesados que se pueden convertir en un diccionario usando la función corpora.Dictionary(). Este diccionario es un mapa para tokens únicos.
Código:
python3
from gensim import corpora # storing the extracted tokens into the dictionary my_dictionary = corpora.Dictionary(tokenized) print(my_dictionary)
Producción:

mi diccionario
1.3.1 Guardar diccionario en disco o como archivo de texto
Puede guardar/cargar su diccionario en el disco , así como un archivo de texto, como se menciona a continuación:
Código:
python3
# save your dictionary to disk
my_dictionary.save('my_dictionary.dict')
# load back
load_dict = corpora.Dictionary.load(my_dictionary.dict')
# save your dictionary as text file
from gensim.test.utils import get_tmpfile
tmp_fname = get_tmpfile("dictionary")
my_dictionary.save_as_text(tmp_fname)
# load your dictionary text file
load_dict = corpora.Dictionary.load_from_text(tmp_fname)
1.4 Crear una bolsa de corpus de palabras
Una vez que tenemos el diccionario, podemos crear una bolsa de corpus de palabras usando la función doc2bow(). Esta función cuenta el número de ocurrencias de cada palabra distinta, convierte la palabra a su ID de palabra entera y luego el resultado se devuelve como un vector disperso.
Código:
python3
# converting to a bag of word corpus BoW_corpus =[my_dictionary.doc2bow(doc, allow_update = True) for doc in tokenized] print(BoW_corpus)
Producción:
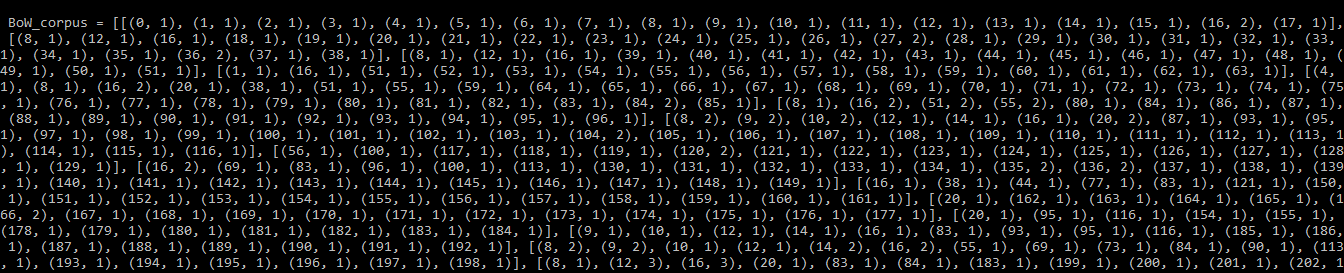
BoW_corpus
1.4.1 Guardando Corpus en Disco:
Código: Para guardar/cargar su corpus
python3
from gensim.corpora import MmCorpus
from gensim.test.utils import get_tmpfile
output_fname = get_tmpfile("BoW_corpus.mm")
# save corpus to disk
MmCorpus.serialize(output_fname, BoW_corpus)
# load corpus
load_corpus = MmCorpus(output_fname)
Paso 2: Cree una array TFIDF en Gensim
TFIDF: significa Frecuencia de término – Frecuencia de documento inversa . Es un modelo de procesamiento de lenguaje natural de uso común que lo ayuda a determinar las palabras más importantes en cada documento de un corpus. Esto fue diseñado para un corpus de tamaño modesto.
Algunas palabras pueden no ser palabras vacías, pero pueden aparecer con más frecuencia en los documentos y pueden tener menos importancia. Por lo tanto, estas palabras deben eliminarse o restarse importancia. El modelo TFIDF toma el texto que comparte un idioma común y garantiza que las palabras más comunes en todo el corpus no se muestren como palabras clave. Puede construir un modelo TFIDF utilizando Gensim y el corpus que desarrolló anteriormente como:
Código:
python3
from gensim import models import numpy as np # Word weight in Bag of Words corpus word_weight =[] for doc in BoW_corpus: for id, freq in doc: word_weight.append([my_dictionary[id], freq]) print(word_weight)
Producción:

Peso de la palabra antes de aplicar el modelo TFIDF
Código: aplicando el modelo TFIDF
python3
# create TF-IDF model tfIdf = models.TfidfModel(BoW_corpus, smartirs ='ntc') # TF-IDF Word Weight weight_tfidf =[] for doc in tfIdf[BoW_corpus]: for id, freq in doc: weight_tfidf.append([my_dictionary[id], np.around(freq, decimals = 3)]) print(weight_tfidf)
Producción:

pesos de las palabras después de aplicar el modelo TFIDF
Puede ver que las palabras que aparecen con frecuencia en los documentos ahora tienen un peso menor asignado.
Paso 3: Creación de bigramas y trigramas con genismo
Muchas palabras tienden a aparecer juntas en el contenido. Las palabras cuando aparecen juntas tienen un significado diferente que cuando aparecen individualmente.
for example:
Beatboxing --> the word beat and boxing individually have meanings of their own
but these together have a different meaning.
Bigramas: Grupo de dos palabras
Trigramas: Grupo de tres palabras
Aquí usaremos el conjunto de datos text8 que se puede descargar usando el código API del descargador de Gensim
: Creación de bigramas y trigramas
python3
import gensim.downloader as api
from gensim.models.phrases import Phrases
# load the text8 dataset
dataset = api.load("text8")
# extract a list of words from the dataset
data =[]
for word in dataset:
data.append(word)
# Bigram using Phraser Model
bigram_model = Phrases(data, min_count = 3, threshold = 10)
print(bigram_model[data[0]])

modelo de bigrama
Para crear un Trigrama simplemente pasamos el modelo de bigrama obtenido arriba a la misma función.
Código:
python3
# Trigram using Phraser Model trigram_model = Phrases(bigram_model[data], threshold = 10) # trigram print(trigram_model[bigram_model[data[0]]])
Producción:

trigrama
Paso 4: Cree el modelo Word2Vec usando Gensim
Los algoritmos ML/DL no pueden acceder al texto directamente, por lo que necesitamos alguna representación numérica para que estos algoritmos puedan procesar los datos. En aplicaciones simples de aprendizaje automático, se utilizan CountVectorizer y TFIDF que no conservan la relación entre las palabras.
Word2Vec:
Método para representar texto para generar incrustaciones de palabras que mapean todas las palabras presentes en un idioma en un espacio vectorial de una dimensión dada. Podemos realizar operaciones matemáticas en estos vectores que ayudan a preservar la relación entre las palabras.

Los modelos de incrustación de palabras preconstruidos como word2vec, GloVe, fasttext, etc. se pueden descargar usando el
API de descarga de Gensim.
A veces, es posible que no encuentre incrustaciones de palabras para ciertas palabras en su documento. Para que puedas entrenar a tu modelo.
4.1) Entrenar el modelo
Código:
python3
import gensim.downloader as api
from multiprocessing import cpu_count
from gensim.models.word2vec import Word2Vec
# load the text8 dataset
dataset = api.load("text8")
# extract a list of words from the dataset
data =[]
for word in dataset:
data.append(word)
# We will split the data into two parts
data_1 = data[:1200] # this is used to train the model
data_2 = data[1200:] # this part will be used to update the model
# Training the Word2Vec model
w2v_model = Word2Vec(data_1, min_count = 0, workers = cpu_count())
# word vector for the word "time"
print(w2v_model['time'])
Producción:
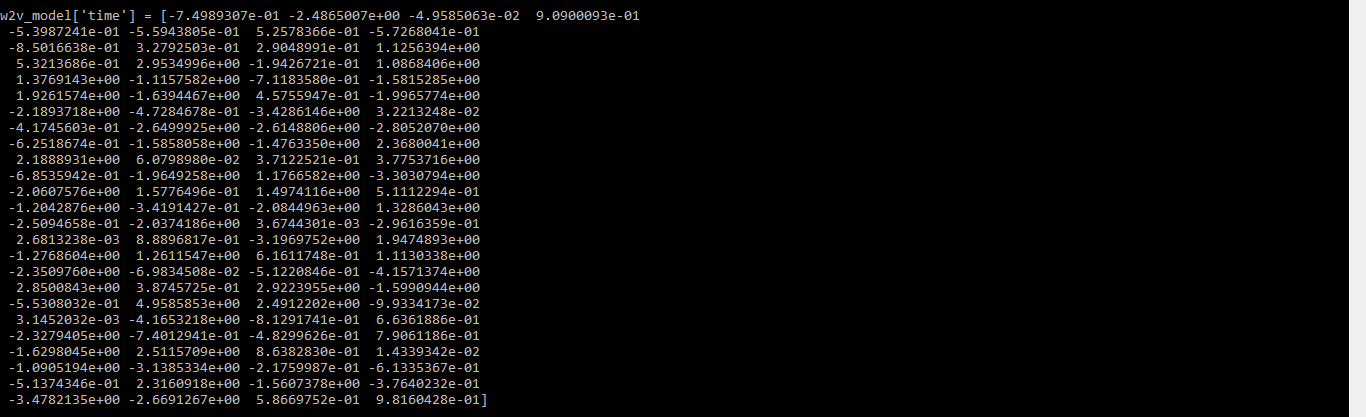
vector de palabra para la palabra tiempo
También puede usar la función most_similar() para encontrar palabras similares a una palabra dada.
Código:
python3
# similar words to the word "time"
print(w2v_model.most_similar('time'))
# save your model
w2v_model.save('Word2VecModel')
# load your model
model = Word2Vec.load('Word2VecModel')
Producción:

palabras más parecidas a ‘tiempo’
4.2) Actualizar el
código del modelo:
python3
# build model vocabulary from a sequence of sentences w2v_model.build_vocab(data_2, update = True) # train word vectors w2v_model.train(data_2, total_examples = w2v_model.corpus_count, epochs = w2v_model.iter) print(w2v_model['time'])
Producción:
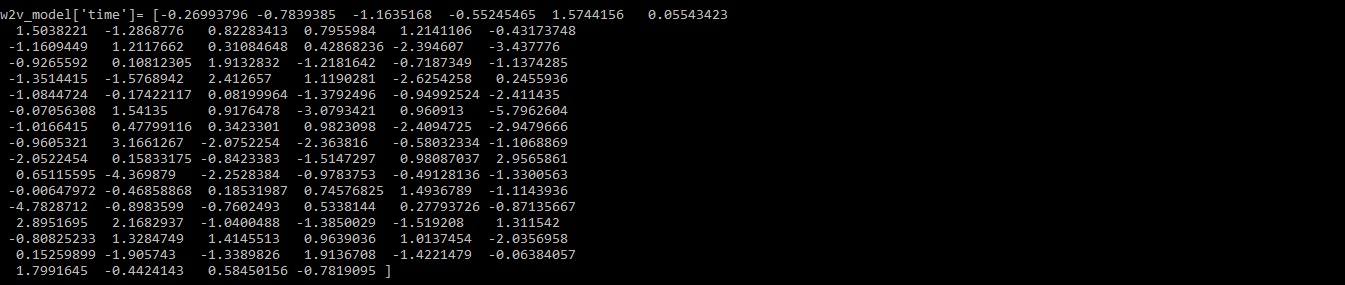
Paso 5: Cree el modelo Doc2Vec usando Gensim
A diferencia del modelo Word2Vec, el modelo Doc2Vec brinda la representación vectorial para un documento completo o un grupo de palabras. Con la ayuda de este modelo, podemos encontrar la relación entre diferentes documentos, tales como:
If we train the model for literature such as "Through the Looking Glass".We can say that-

5.1) Train the model
Code:
python3
import gensim
import gensim.downloader as api
from gensim.models import doc2vec
# get dataset
dataset = api.load("text8")
data =[]
for w in dataset:
data.append(w)
# To train the model we need a list of tagged documents
def tagged_document(list_of_ListOfWords):
for x, ListOfWords in enumerate(list_of_ListOfWords):
yield doc2vec.TaggedDocument(ListOfWords, [x])
# training data
data_train = list(tagged_document(data))
# print trained dataset
print(data_train[:1])
Producción:

SALIDA: conjunto de datos entrenado
5.2) Actualice el código del modelo:
python3
# Initialize the model d2v_model = doc2vec.Doc2Vec(vector_size = 40, min_count = 2, epochs = 30) # build the vocabulary d2v_model.build_vocab(data_train) # Train Doc2Vec model d2v_model.train(data_train, total_examples = d2v_model.corpus_count, epochs = d2v_model.epochs) # Analyzing the output Analyze = d2v_model.infer_vector(['violent', 'means', 'to', 'destroy']) print(Analyze)
Producción:

Salida del modelo actualizado
Paso 6: Crear un modelo de tema con LDA
LDA es un método popular para el modelado de temas que considera cada documento como una colección de temas en cierta proporción. Necesitamos eliminar la buena calidad de los temas, como cuán segregados y significativos son. Los temas de buena calidad dependen de-
- la calidad del procesamiento de texto
- encontrar el número óptimo de temas
- Parámetros de ajuste del algoritmo
NOTE: If you run this code on python3.7 version you might get a StopIteration Error.
It is advisable to use python3.6 version for this.
Siga los pasos a continuación para crear el modelo:
6.1 Prepare los datos
Esto se hace eliminando las palabras vacías y luego lematizándolas. Para lematizar usando Gensim, primero debemos descargar el paquete de patrones y las palabras vacías.
#download pattern package
pip install pattern
#run in python console
>> import nltk
>> nltk.download('stopwords')
Código:
python3
import gensim
from gensim import corpora
from gensim.models import LdaModel, LdaMulticore
import gensim.downloader as api
from gensim.utils import simple_preprocess, lemmatize
# from pattern.en import lemma
import nltk
# nltk.download('stopwords')
from nltk.corpus import stopwords
import re
import logging
logging.basicConfig(format ='%(asctime)s : %(levelname)s : %(message)s')
logging.root.setLevel(level = logging.INFO)
# import stopwords
stop_words = stopwords.words('english')
# add stopwords
stop_words = stop_words + ['subject', 'com', 'are', 'edu', 'would', 'could']
# import the dataset
dataset = api.load("text8")
data = [w for w in dataset]
# Preparing the data
processed_data = []
for x, doc in enumerate(data[:100]):
doc_out = []
for word in doc:
if word not in stop_words: # to remove stopwords
Lemmatized_Word = lemmatize(word, allowed_tags = re.compile('(NN|JJ|RB)')) # lemmatize
if Lemmatized_Word:
doc_out.append(Lemmatized_Word[0].split(b'/')[0].decode('utf-8'))
else:
continue
processed_data.append(doc_out) # processed_data is a list of list of words
# Print sample
print(processed_data[0][:10])
Producción:

SALIDA – datos_procesados
6.2 Crear diccionario y corpus
Los datos procesados ahora se utilizarán para crear el diccionario y el corpus.
Código:
python3
# create dictionary and corpus dict = corpora.Dictionary(processed_data) Corpus = [dict.doc2bow(l) for l in processed_data]
6.3 Entrenar el modelo LDA
Estaremos entrenando el modelo LDA con 5 temas usando el diccionario y corpus creados previamente. Aquí se usa la función LdaModel( ) pero también puede usar la función LdaMulticore( ) ya que permite el procesamiento paralelo.
Código:
python3
# Training
LDA_model = LdaModel(corpus = LDA_corpus, num_topics = 5)
# save model
LDA_model.save('LDA_model.model')
# show topics
print(LDA_model.print_topics(-1))
Producción:

SALIDA – temas
Las palabras que se pueden ver en más de un tema y son de menor relevancia se pueden agregar a la lista de palabras vacías.
6.4 Interpretar la salida
El modelo LDA nos brinda principalmente información sobre 3 cosas:
- Temas en el documento
- a que tema pertenece cada palabra
- valor phi
Valor de phi: es la probabilidad de que una palabra se encuentre en un tema en particular. Para una palabra dada, la suma de los valores de phi da la cantidad de veces que esa palabra apareció en el documento.
Código:
python3
# probability of a word belonging to a topic
LDA_model.get_term_topics('fire')
bow_list =['time', 'space', 'car']
# convert to bag of words format first
bow = LDA_model.id2word.doc2bow(bow_list)
# interpreting the data
doc_topics, word_topics, phi_values = LDA_model.get_document_topics(bow, per_word_topics = True)
Paso 7: Crear modelo de tema con LSI
Para crear el modelo con LSI, simplemente siga los mismos pasos que con LDA. La única diferencia será durante el entrenamiento del modelo.
Utilice la función LsiModel( ) en lugar de LdaMulticore( ) o LdaModel( ).
Código:
python3
# Training the model with LSI LSI_model = LsiModel(corpus = Corpus, id2word = dct, num_topics = 7, decay = 0.5) # Topics print(LSI_model.print_topics(-1))
Paso 8: Calcular Arrays de Semejanza
Coseno Semejanza: Es una medida de semejanza entre dos vectores distintos de cero de un espacio de producto interno. Se define como igual al coseno del ángulo entre ellos.
Similitud de coseno suave: es similar a la similitud de coseno, pero la diferencia es que la similitud de coseno considera las características del modelo de espacio vectorial (VSM) como independientes, mientras que el coseno suave propone considerar la similitud de las características en VSM.
Necesitamos tomar un modelo de incrustación de palabras para calcular los cosenos blandos.
Aquí estamos usando el modelo word2vec preentrenado.
Note: If you run this code on python3.7 version you might get a StopIteration Error.
It is advisable to use python3.6 version for this.
Código:
python3
import gensim.downloader as api
from gensim.matutils import softcossim
from gensim import corpora
s1 = ' Afghanistan is an Asian country and capital is Kabul'.split()
s2 = 'India is an Asian country and capital is Delhi'.split()
s3 = 'Greece is an European country and capital is Athens'.split()
# load pre-trained model
word2vec_model = api.load('word2vec-google-news-300')
# Prepare the similarity matrix
similarity_matrix = word2vec_model.similarity_matrix(dictionary, tfidf = None, threshold = 0.0, exponent = 2.0, nonzero_limit = 100)
# Prepare a dictionary and a corpus.
docs = [s1, s2, s3]
dictionary = corpora.Dictionary(docs)
# Convert the sentences into bag-of-words vectors.
s1 = dictionary.doc2bow(s1)
s2 = dictionary.doc2bow(s2)
s3 = dictionary.doc2bow(s3)
# Compute soft cosine similarity
print(softcossim(s1, s2, similarity_matrix)) # similarity between s1 &s2
print(softcossim(s1, s3, similarity_matrix)) # similarity between s1 &s3
print(softcossim(s2, s3, similarity_matrix)) # similarity between s2 &s3
Algunas de las métricas de similitud y distancia que se pueden calcular para este modelo de incrustación de palabras se mencionan a continuación:
Código:
python3
# Find Odd one out
print(word2vec_model.doesnt_match(['india', 'bhutan', 'china', 'mango']))
#> mango
# cosine distance between two words.
word2vec_model.distance('man', 'woman')
# cosine distances from given word or vector to other words.
word2vec_model.distances('king', ['queen', 'man', 'woman'])
# Compute cosine similarities
word2vec_model.cosine_similarities(word2vec_model['queen'],
vectors_all =(word2vec_model['king'],
word2vec_model['woman'],
word2vec_model['man'],
word2vec_model['king'] + word2vec_model['woman']))
# king + woman is very similar to queen.
# words closer to w1 than w2
word2vec_model.words_closer_than(w1 ='queen', w2 ='kingdom')
# top-N most similar words.
word2vec_model.most_similar(positive ='king', negative = None, topn = 5, restrict_vocab = None, indexer = None)
# top-N most similar words, using the multiplicative combination objective,
word2vec_model.most_similar_cosmul(positive ='queen', negative = None, topn = 5)
Paso 9: Resumir documentos de texto
La función resume( ) implementa el resumen de clasificación de texto.
No tiene que generar una lista tokenizada dividiendo las oraciones, ya que eso ya lo maneja el módulo gensim.summarization.textcleaner.
Código:
python3
from gensim.summarization import summarize, keywords
import os
text = " ".join((l for l in open('sample_data.txt', encoding ='utf-8')))
# Summarize the paragraph
print(summarize(text, word_count = 25))
Producción:

SALIDA – Resumen
Puede obtener las palabras clave por:
Código:
python3
# Important keywords from the paragraph print(keywords(text))

SALIDA – Palabras clave
Conclusión:
estas son algunas de las características de la biblioteca Gensim. Esto es más útil mientras trabaja en el procesamiento del lenguaje. Puede utilizarlas según sus necesidades.
Para cualquier consulta, no dude en dejar un comentario a continuación.
Publicación traducida automáticamente
Artículo escrito por shristikotaiah y traducido por Barcelona Geeks. The original can be accessed here. Licence: CCBY-SA