La visión por computadora significa la extracción de información de imágenes, texto, videos, etc. A veces, la visión por computadora intenta imitar la visión humana. Es un subconjunto de inteligencia basada en computadora o inteligencia artificial que recopila información de imágenes o videos digitales y los analiza para definir los atributos.
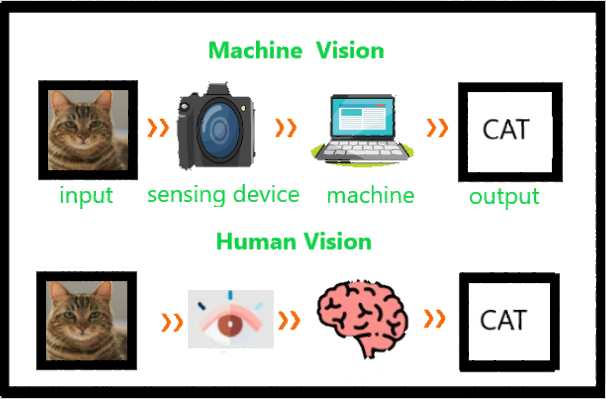
Todo el proceso implica la adquisición de imágenes, la detección, el análisis, la identificación y la extracción de información. Este extenso procesamiento ayuda a las computadoras a comprender cualquier contenido visual y actuar en consecuencia. Los proyectos de visión artificial traducen el contenido visual digital en descripciones precisas para recopilar datos multidimensionales. Estos datos luego se convierten en un lenguaje legible por computadora para ayudar en el proceso de toma de decisiones. El principal objetivo de esta rama de la Inteligencia Artificial es enseñar a las máquinas a recopilar información a partir de imágenes.
Aplicaciones de la Visión por Computador
- Imágenes médicas: la visión por computadora ayuda en la reconstrucción de MRI, patología automática, diagnóstico y cirugías asistidas por computadora y más.
- AR/VR: oclusión de objetos, seguimiento de afuera hacia adentro y de adentro hacia afuera para realidad virtual y aumentada.
- Teléfonos inteligentes: todos los filtros de fotos (incluidos los filtros de animación en las redes sociales), los escáneres de códigos QR, la construcción de panoramas, la fotografía computacional, los detectores de rostros, los detectores de imágenes como (Google Lens, Night Sight) que usamos son aplicaciones de visión por computadora.
- Internet: búsqueda de imágenes, mapeo, subtítulos de fotos, imágenes Ariel para mapas, categorización de videos y más.
Visión artificial con OpenCV
OpenCV (Open Source Computer Vision) , una biblioteca de funciones multiplataforma y de uso gratuito se basa en Computer Vision en tiempo real que admite marcos de aprendizaje profundo que ayudan en el procesamiento de imágenes y videos. En Computer Vision, el elemento principal es extraer los píxeles de la imagen para estudiar los objetos y así entender lo que contiene. A continuación se presentan algunos aspectos clave que Computer Vision busca reconocer en las fotografías:
- Detección de objetos: la ubicación del objeto.
- Reconocimiento de objetos: los objetos en la imagen y sus posiciones.
- Clasificación de objetos: la amplia categoría en la que se encuentra el objeto.
- Segmentación de objetos: los píxeles que pertenecen a ese objeto.
Necesidad de visión artificial
Desde selfies hasta imágenes de paisajes, hoy en día estamos inundados con todo tipo de fotos. Un informe de Tendencias de Internet dice que las personas cargan más de 1.800 millones de fotos al día, y esa es solo la cantidad de imágenes cargadas. Considere cuál sería el número si cuenta las imágenes almacenadas en los teléfonos. Consumimos más de 4, 146, 600 videos en YouTube y enviamos 103, 447, 520 correos no deseados diariamente. Nuevamente, eso es solo una parte: la comunicación, los medios y el entretenimiento, el IoT, todos contribuyen activamente a este número. Este abundante contenido visual disponible exige análisis y comprensión, y la visión por computadora ayuda a hacerlo al enseñar a las máquinas a «ver» estas imágenes y videos.
Publicación traducida automáticamente
Artículo escrito por muhammadfaizantanveer786 y traducido por Barcelona Geeks. The original can be accessed here. Licence: CCBY-SA