La regresión logística es un algoritmo de clasificación que se utiliza para encontrar la probabilidad de éxito y falla del evento. Se utiliza cuando la variable dependiente es de naturaleza binaria (0/1, Verdadero/Falso, Sí/No). Admite la categorización de datos en clases discretas al estudiar la relación de un conjunto dado de datos etiquetados. Aprende una relación lineal del conjunto de datos dado y luego introduce una no linealidad en forma de función sigmoidea.
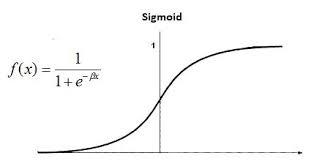
La regresión logística también se conoce como regresión logística binomial . Se basa en la función sigmoidea donde la salida es probabilidad y la entrada puede ser de -infinito a +infinito. Analicemos algunas ventajas y desventajas de la regresión lineal.
| Ventajas | Desventajas |
|---|---|
| La regresión logística es más fácil de implementar, interpretar y muy eficiente de entrenar. | Si el número de observaciones es menor que el número de características, no se debe utilizar la regresión logística, de lo contrario, puede provocar un sobreajuste. |
| No hace suposiciones acerca de las distribuciones de clases en el espacio de características. | Construye límites lineales. |
| Puede extenderse fácilmente a múltiples clases (regresión multinomial) y una vista probabilística natural de las predicciones de clase. | La principal limitación de la regresión logística es la suposición de linealidad entre la variable dependiente y las variables independientes. |
| No solo proporciona una medida de cuán apropiado es un predictor (tamaño del coeficiente), sino también su dirección de asociación (positiva o negativa). | Solo se puede usar para predecir funciones discretas. Por lo tanto, la variable dependiente de la regresión logística está ligada al conjunto de números discretos. |
| Es muy rápido en la clasificación de registros desconocidos. | Los problemas no lineales no se pueden resolver con regresión logística porque tiene una superficie de decisión lineal. Los datos linealmente separables rara vez se encuentran en escenarios del mundo real. |
| Buena precisión para muchos conjuntos de datos simples y funciona bien cuando el conjunto de datos es linealmente separable. | La regresión logística requiere multicolinealidad media o nula entre variables independientes. |
| Puede interpretar los coeficientes del modelo como indicadores de la importancia de las características. | Es difícil obtener relaciones complejas utilizando la regresión logística. Los algoritmos más potentes y compactos, como las redes neuronales, pueden superar fácilmente a este algoritmo. |
| La regresión logística es menos propensa al sobreajuste, pero puede hacerlo en conjuntos de datos de gran dimensión. Se pueden considerar técnicas de regularización (L1 y L2) para evitar el sobreajuste en estos escenarios. | En la regresión lineal, las variables independientes y dependientes se relacionan linealmente. Pero la regresión logística necesita que las variables independientes se relacionen linealmente con las probabilidades logarítmicas (log(p/(1-p)). |
Publicación traducida automáticamente
Artículo escrito por AmiyaRanjanRout y traducido por Barcelona Geeks. The original can be accessed here. Licence: CCBY-SA