La visualización de datos es la presentación de datos en formato gráfico. Ayuda a las personas a comprender la importancia de los datos al resumir y presentar una gran cantidad de datos en un formato simple y fácil de entender y ayuda a comunicar la información de manera clara y efectiva.
¡En este tutorial, aprenderemos sobre las capacidades integradas de pandas para la visualización de datos! Está construido a partir de matplotlib, ¡pero se horneó en pandas para un uso más fácil!
¡Vamos a ver!
Instalación La
forma más fácil de instalar pandas es usar pip:
pip install pandas
o Descárgala desde aquí
Este artículo muestra una ilustración del uso de la función de visualización de datos integrada en pandas al trazar diferentes tipos de gráficos.
Importación de bibliotecas y archivos de datos necesarios:
Los archivos csv de muestra df1 y df2 utilizados en este tutorial se pueden descargar desde aquí .
import numpy as np
import pandas as pd
# There are some fake data csv files
# you can read in as dataframes
df1 = pd.read_csv('df1', index_col = 0)
df2 = pd.read_csv('df2')
Hojas de estilo –
Matplotlib tiene hojas de estilo que se pueden usar para hacer que los gráficos se vean un poco mejor. Estas hojas de estilo incluyen plot_bmh, plot_fivethirtyeighty plot_ggplot más. Básicamente crean un conjunto de reglas de estilo que siguen tus tramas. Recomendamos usarlos, hacen que todas tus parcelas tengan el mismo aspecto y se sientan más profesionales. Incluso podemos crear los nuestros propios si queremos que todos los gráficos de la empresa tengan el mismo aspecto (aunque es un poco tedioso crearlos).
Aquí está cómo usarlos.
Antes de plt.style.use()que las parcelas se vean así:
df1['A'].hist()
Producción :
Llama al estilo:
Ahora, las tramas se ven así después de llamar al ggplotestilo:
import matplotlib.pyplot as plt
plt.style.use('ggplot')
df1['A'].hist()
Producción :
Las parcelas se ven así después de llamar al bmhestilo:
plt.style.use('bmh')
df1['A'].hist()
Producción :
Las parcelas se ven así después de llamar al dark_backgroundestilo:
plt.style.use('dark_background')
df1['A'].hist()
Producción :
Las parcelas se ven así después de llamar al fivethirtyeightestilo:
plt.style.use('fivethirtyeight')
df1['A'].hist()
Producción :
Tipos de parcelas –
Hay varios tipos de gráficos integrados en pandas, la mayoría de ellos gráficos estadísticos por naturaleza:
También puede llamar df.plot(kind='hist') o reemplazar ese tipo de argumento con cualquiera de los términos clave que se muestran en la lista anterior (por ejemplo, ‘box’, ‘barh’, etc.). ¡Empecemos a repasarlos!
1.) Área
Un gráfico de área o un gráfico de área muestra gráficamente datos cuantitativos. Se basa en el gráfico de líneas. El área entre el eje y la línea se suele enfatizar con colores, texturas y sombreados. Comúnmente uno compara dos o más cantidades con un gráfico de área.
df2.plot.area(alpha = 0.4)
Producción :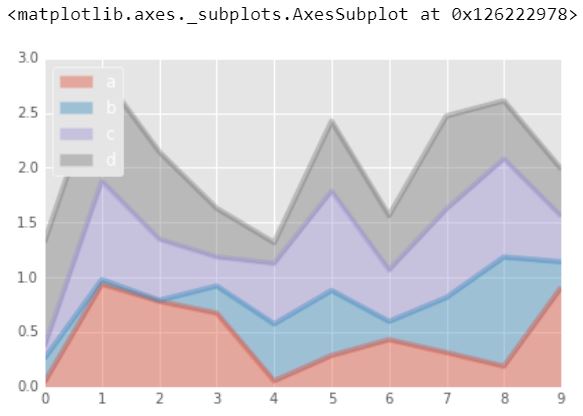
2.) Diagramas de barras
Un diagrama de barras o gráfico de barras es un cuadro o gráfico que presenta datos categóricos con barras rectangulares con alturas o longitudes proporcionales a los valores que representan. Las barras se pueden trazar vertical u horizontalmente. Un gráfico de barras verticales a veces se denomina gráfico de líneas.
df2.head()
Producción :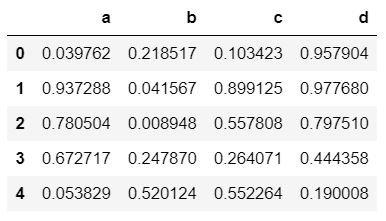
df2.plot.bar()
Producción :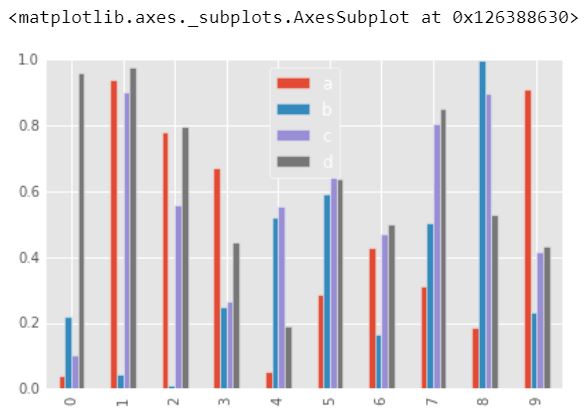
df2.plot.bar(stacked = True)
Producción :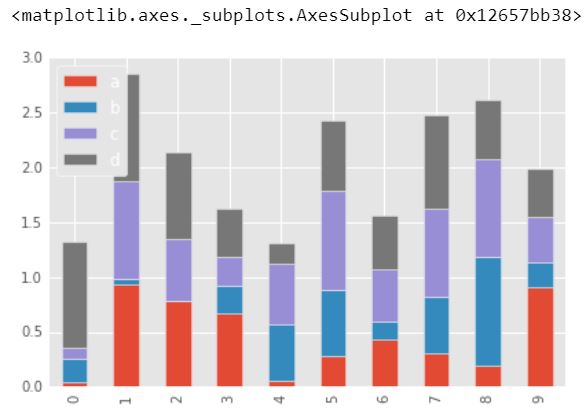
3.) Histogramas
Un histograma es un gráfico que le permite descubrir y mostrar la distribución de frecuencia subyacente (forma) de un conjunto de datos continuos. Esto permite la inspección de los datos para su distribución subyacente (p. ej., distribución normal), valores atípicos, asimetría, etc.
df1['A'].plot.hist(bins = 50)
Producción :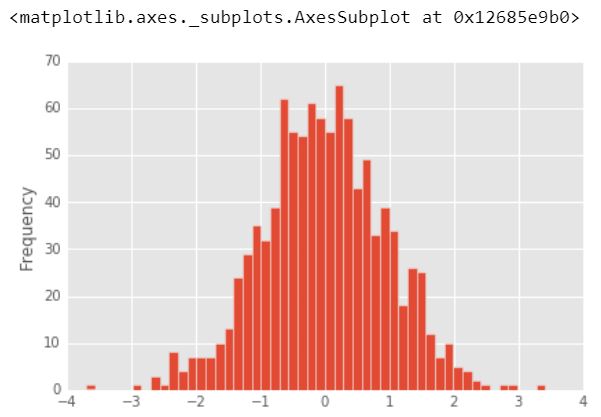
4.) Gráficos de línea
Un gráfico de líneas es un gráfico que muestra la frecuencia de los datos a lo largo de una recta numérica. Es mejor usar un gráfico de líneas cuando los datos son series de tiempo. Es una forma rápida y sencilla de organizar los datos.
df1.plot.line(x = df1.index, y ='B', figsize =(12, 3), lw = 1)
Producción :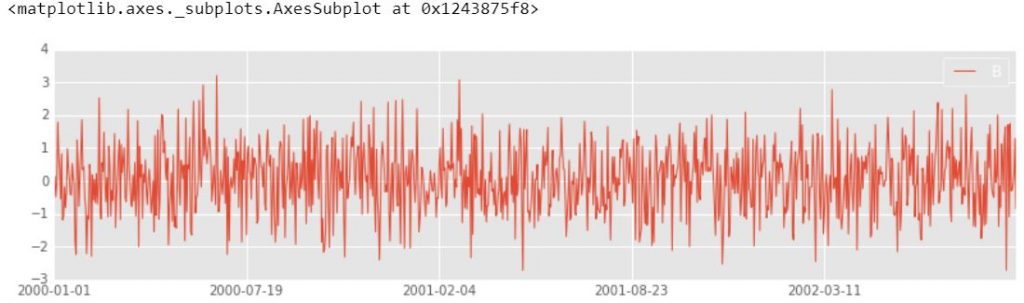
5.) Gráficos de dispersión
Los diagramas de dispersión se utilizan cuando desea mostrar la relación entre dos variables. Los diagramas de dispersión a veces se denominan diagramas de correlación porque muestran cómo se correlacionan dos variables.
df1.plot.scatter(x ='A', y ='B')
Producción :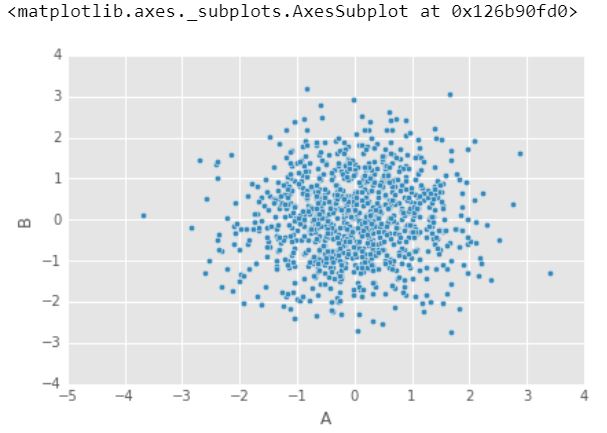
Puede usar c para colorear en función de otro valor de columna. Use cmap para indicar el mapa de colores que se usará. Para todos los mapas de colores, consulte: http://matplotlib.org/users/colormaps.html
df1.plot.scatter(x ='A', y ='B', c ='C', cmap ='coolwarm')
Producción :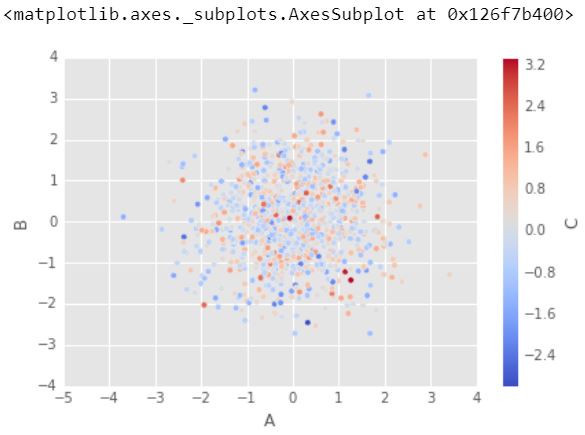
O use s para indicar el tamaño basado en otra columna. El parámetro s debe ser una array, no solo el nombre de una columna:
df1.plot.scatter(x ='A', y ='B', s = df1['C']*200)
Producción :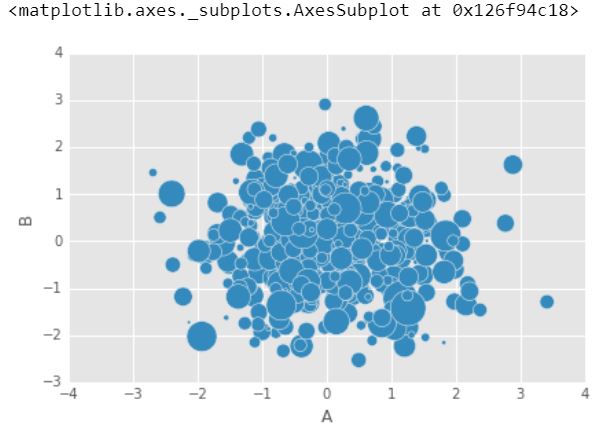
6.) Diagramas de caja
Es una gráfica en la que se dibuja un rectángulo para representar el segundo y tercer cuartiles, generalmente con una línea vertical adentro para indicar el valor de la mediana. Los cuartiles inferior y superior se muestran como líneas horizontales a ambos lados del rectángulo.
Un diagrama de caja es una forma estandarizada de mostrar la distribución de datos basada en un resumen de cinco números («mínimo», primer cuartil (Q1), mediana, tercer cuartil (Q3) y «máximo»). Puede informarle sobre sus valores atípicos y cuáles son sus valores. También puede decirle si sus datos son simétricos, qué tan estrechamente se agrupan sus datos y si sus datos están sesgados y cómo.
df2.plot.box() # Can also pass a by = argument for groupby
Producción :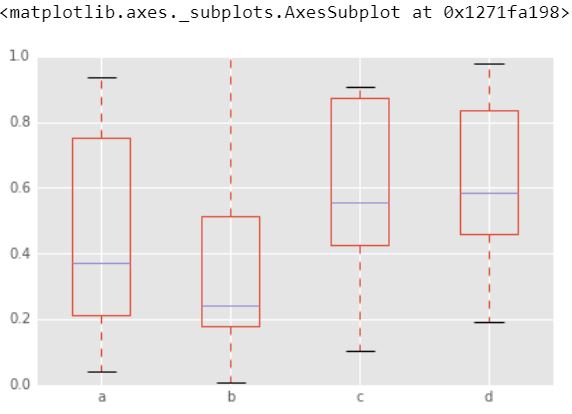
7.) Gráficos de contenedores hexagonales
El agrupamiento hexagonal es otra forma de manejar el problema de tener muchos puntos que comienzan a superponerse. El binning hexagonal traza la densidad, en lugar de los puntos. Los puntos se agrupan en hexágonos cuadriculados y la distribución (el número de puntos por hexágono) se muestra usando el color o el área de los hexágonos.
Útil para datos bivariados, alternativa al diagrama de dispersión:
df = pd.DataFrame(np.random.randn(1000, 2), columns =['a', 'b']) df.plot.hexbin(x ='a', y ='b', gridsize = 25, cmap ='Oranges')
Producción :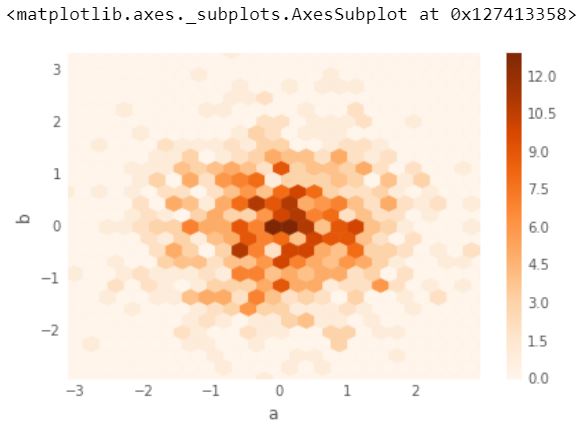
8.) Gráfica de estimación de la densidad del núcleo (KDE)
KDE es una técnica que le permite crear una curva suave dado un conjunto de datos.
Esto puede ser útil si desea visualizar solo la «forma» de algunos datos, como una especie de reemplazo continuo del histograma discreto. También se puede usar para generar puntos que parecen provenir de un determinado conjunto de datos: este comportamiento puede impulsar simulaciones simples, donde los objetos simulados se modelan a partir de datos reales.
df2['a'].plot.kde()
Producción :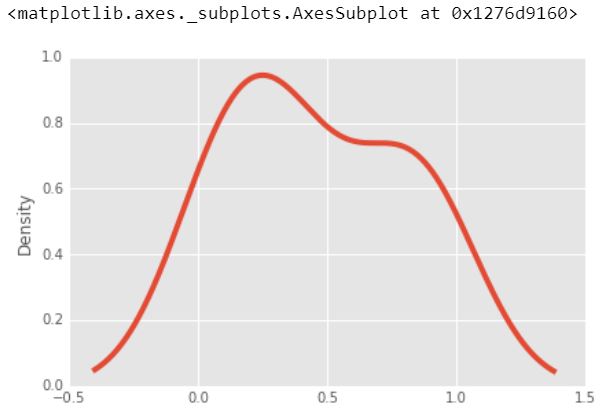
df2.plot.density()
Producción :
¡Eso es todo! Con suerte, puede ver por qué este método de trazado será mucho más fácil de usar que matplotlib completo, equilibra la facilidad de uso con el control sobre la figura. Muchas de las llamadas de trama también aceptan argumentos adicionales de su padre matplotlib plt. llamar.
Publicación traducida automáticamente
Artículo escrito por tyagikartik4282 y traducido por Barcelona Geeks. The original can be accessed here. Licence: CCBY-SA