Trabajar con datos a veces puede ser un poco aburrido. Transformar datos sin procesar en un formato comprensible es una de las partes más esenciales de todo el proceso, entonces, ¿por qué quedarse con los números, cuando podemos visualizar nuestros datos en gráficos alucinantes que están disponibles en python? Este artículo se centrará en explorar tramas que podrían hacer que su viaje de preprocesamiento sea intrigante.
Seaborn y Matplotlib nos brindan numerosos gráficos atractivos a través de los cuales uno puede analizar fácilmente los puntos débiles, explorar datos con una comprensión más profunda y, finalmente, obtener una gran comprensión de los datos y obtener la mayor precisión después de entrenarlos a través de diferentes algoritmos.
Echemos un vistazo a nuestro conjunto de datos : el conjunto de datos (36 filas) contiene 6 características y 2 clases (supervivientes = 1, no supervivientes = 0) en base a las cuales trazaremos ciertos gráficos. Enlace del conjunto de datos: haga clic aquí para obtener el conjunto de datos completo
1. GRÁFICO DE KDE: Bien Entonces, después de echar un vistazo al conjunto de datos, podemos tener una pregunta. ¿Qué grupo de edad tiene el número máximo de personas? Para responder a esta pregunta, necesitamos elementos visuales donde Our KDE Plot entre en escena, es simplemente un gráfico de densidad. Entonces, comencemos importando las bibliotecas requeridas y usemos sus funciones para trazar el gráfico.
Python3
# importing the modules and dataset
import pandas as pd
import matplotlib.pyplot as plt
import seaborn as sns
dataset = pd.read_csv("Survival.csv")
# KDE plot
sns.kdeplot(dataset["Age"], color = "green",
shade = True)
plt.show()
plt.figure()
Producción :
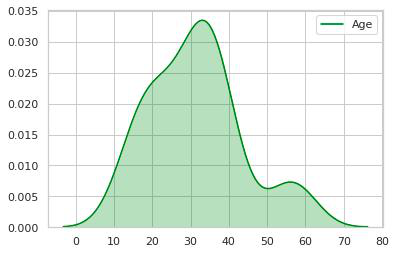
2. Así que ahora tenemos una imagen clara de cómo se distribuye el recuento de personas frente al grupo de edad, aquí podemos ver que el grupo de edad 20-40 tiene un recuento máximo, así que vamos a comprobarlo.
Python3
# importing the modules and dataset
import pandas as pd
import matplotlib.pyplot as plt
import seaborn as sns
dataset = pd.read_csv("Survival.csv")
# Checking the count of Age Group 20-40
dataset.Age[(dataset["Age"] >= 20) & (dataset["Age"] <= 40)].count()
Producción :
26
3. Profundizando en las imágenes, para conocer la variación en Fair Vs Age, cuál es la relación entre ellos, echemos un vistazo usando un tipo diferente de kdeplot simplemente ahora habrá densidades bivariadas, solo agregaremos la variable Y (Justa).
Python3
# importing the modules and dataset
import pandas as pd
import matplotlib.pyplot as plt
import seaborn as sns
dataset = pd.read_csv("Survival.csv")
sns.kdeplot(dataset["Age"], dataset["Fare"], shade = True)
plt.show()
plt.figure()
Producción :
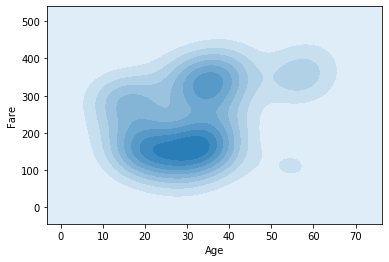
4. Después de estudiar un poco esta trama, vemos que la intensidad del color es máxima entre el grupo de edad 20-30 y precisamente estos tienen un justo entre 100-200, vamos a comprobarlo.
Python3
# importing the modules and dataset
import pandas as pd
import matplotlib.pyplot as plt
import seaborn as sns
dataset = pd.read_csv("Survival.csv")
# Checking The Variation Between Fare And Age
dataset.Age[((dataset["Fare"] >= 100) &
(dataset["Fare"]<=200)) &
((dataset["Age"]>=20) &
dataset["Age"]<=40)].count()
Producción :
16
5. También podemos agregar un histograma a kdeplot simplemente usando el módulo distplot() de seaborn:
Python3
# importing the modules and dataset
import pandas as pd
import matplotlib.pyplot as plt
import seaborn as sns
dataset = pd.read_csv("Survival.csv")
# Histogram+Density Plot
sns.distplot(dataset["Age"], color = "green")
plt.show()
plt.figure()
Producción :
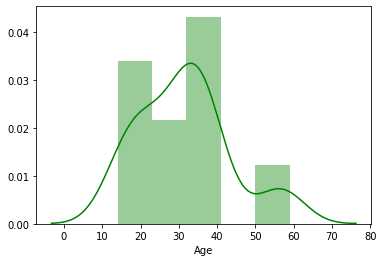
6. Bueno. Si uno quiere saber acerca de la proporción entre hombres y mujeres, podemos trazar lo mismo en KDE:
Python3
# importing the modules and dataset
import pandas as pd
import matplotlib.pyplot as plt
import seaborn as sns
dataset = pd.read_csv("Survival.csv")
# Adding Two Plots In One
sns.kdeplot(dataset[dataset.Gender == 'Female']['Age'],
color = "blue")
sns.kdeplot(dataset[dataset.Gender == 'Male']['Age'],
color = "orange", shade = True)
plt.show()
plt.figure()
Producción :
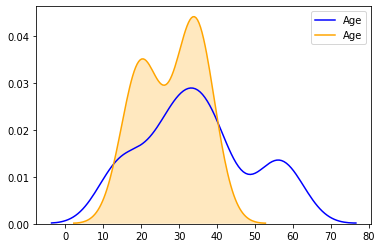
7. Como podemos ver en la gráfica, hay un aumento en el conteo después de los 12 años hasta los 40 años, verifiquemos lo mismo
Python3
# importing the modules and dataset
import pandas as pd
import matplotlib.pyplot as plt
import seaborn as sns
dataset = pd.read_csv("Survival.csv")
# showing that there are more Male's Between Age Of 12-40
dataset.Gender[((dataset["Age"] >= 12) &
(dataset["Age"] <= 40)) &
(dataset["Gender"] == "Male")].count()
dataset.Gender[((dataset["Age"] >= 12) &
(dataset["Age"] <= 40)) &
(dataset["Gender"] == "Female")].count()
Producción :
17 15
8. TRAMA DE VIOLÍN: Hemos hablado mucho sobre las funciones, ahora hablemos sobre la dependencia de la tasa de supervivencia en las funciones. Para esto, usaremos un clásico Violin Plot, como su nombre indica, representa las mismas imágenes que las ondas musicales de un violín. Básicamente, se utiliza A Violin Plot para visualizar la distribución de los datos y su densidad de probabilidad.
¿Cuál es la relación entre la tasa de supervivencia y la edad? Analicémoslo visualmente:
Python3
# importing the modules and dataset
import pandas as pd
import matplotlib.pyplot as plt
import seaborn as sns
dataset = pd.read_csv("Survival.csv")
sns.violinplot(x = 'Survived', y = 'Age', data = dataset,
palette = {0 : "yellow", 1 : "orange"});
plt.show()
plt.figure()
Producción :
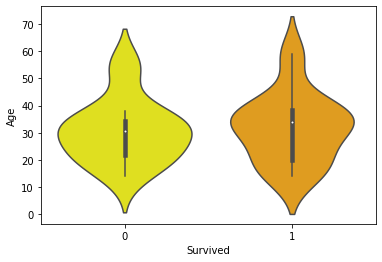
Explicación: el punto blanco que vemos en el gráfico es la mediana y la barra negra gruesa en el centro representa el
rango intercuartílico. La línea negra delgada que se extiende desde ella representa los valores adyacentes superior (máx.) e inferior (mín.) en los datos.
Un vistazo rápido nos muestra que entre la edad [10-20] la tasa de supervivencia es un poco más alta (sobrevivió == 1).
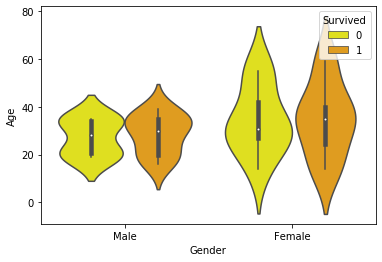
9. Grafiquemos uno más para la tasa de supervivencia frente al género y la edad
Python3
# importing the modules and dataset
import pandas as pd
import matplotlib.pyplot as plt
import seaborn as sns
dataset = pd.read_csv("Survival.csv")
sns.violinplot(x = "Gender", y = "Age", hue = "Survived",
data = dataset,
palette = {0 : "yellow", 1 : "orange"})
plt.show()
plt.figure()
Aquí, un atributo adicional es el matiz, que se refiere al valor binario de Survived.
Producción :
10. CATPLOT: En términos simples, catplot muestra frecuencias (u opcionalmente fracciones o porcentajes) de las categorías de una, dos o tres variables categóricas.
Python3
# importing the modules and dataset
import pandas as pd
import matplotlib.pyplot as plt
import seaborn as sns
dataset = pd.read_csv("Survival.csv")
# Plot a nested barplot to show survival for Siblings and Gender
g = sns.catplot(x = "Siblings", y = "Survived", hue = "Gender", data = dataset,
height = 6, kind = "bar", palette = "muted")
g.despine(lef t= True)
g.set_ylabels("Survival Probability")
plt.show()
Aquí sns.despine se usa para eliminar las espinas superior y derecha de la trama, echemos un vistazo.
Producción :
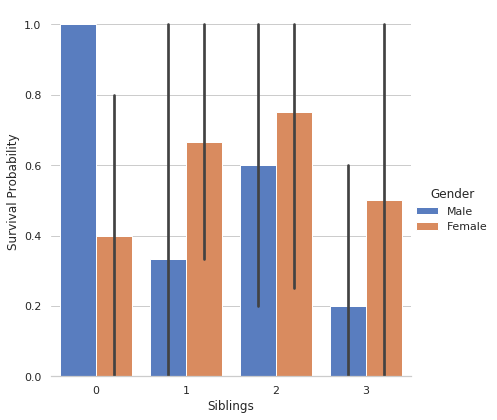
Aquí obtenemos una imagen clara de la probabilidad de supervivencia sabia de género con el número de hermanos.
11 _ Ahora, en el conjunto de datos, vemos que hay tres categorías en el boleto, que se basan en la tarifa, averigüémoslo (refiriéndose a este gráfico, agregué una columna de categoría para los boletos)
Python3
# importing the modules and dataset
import pandas as pd
import matplotlib.pyplot as plt
import seaborn as sns
dataset = pd.read_csv("Survival.csv")
# Based On Fare There Are 3 Types Of Tickets
sns.catplot(x = "PassType", y = "Fare", data = dataset)
plt.show()
plt.figure()
Producción :
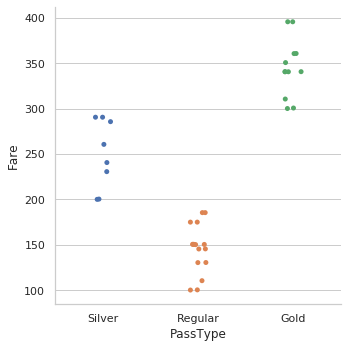
Con esto llegamos a la conclusión de que las categorías deben definirse para los boletos.
12. Relación de la misma con Tasa de Supervivencia:
Python3
# importing the modules and dataset
import pandas as pd
import matplotlib.pyplot as plt
import seaborn as sns
dataset = pd.read_csv("Survival.csv")
sns.catplot(x="PassType", y="Fare", hue="Survived",kind="swarm",data=dataset)
plt.show()
plt.figure()
Producción :
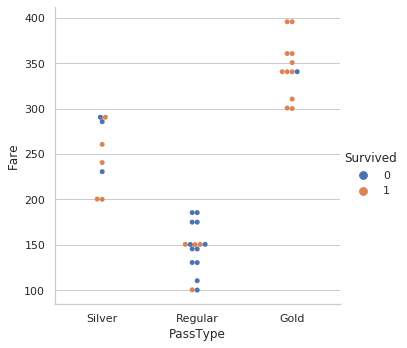
A partir de esto, obtenemos una idea clara de la tasa de supervivencia frente a la categoría de boletos.
Publicación traducida automáticamente
Artículo escrito por absking786 y traducido por Barcelona Geeks. The original can be accessed here. Licence: CCBY-SA