Requisito previo: visualización de datos en Python
Visualización es ver los datos a lo largo de varias dimensiones. En python, podemos visualizar los datos usando varios gráficos disponibles en diferentes módulos.
En este artículo, vamos a visualizar y predecir los datos de producción de cultivos para diferentes años utilizando varias ilustraciones y bibliotecas de Python.
conjunto de datos
El conjunto de datos contiene diferentes cultivos y su producción desde el año 2013 hasta el 2020.
Requisitos
Hay muchas bibliotecas de Python que podrían usarse para crear visualizaciones como matplotlib, vispy, bokeh, seaborn, pygal, folium, plotly, cufflinks y networkx . De los muchos, matplotlib y seaborn parecen ser muy utilizados para visualizaciones de nivel básico a intermedio.
Sin embargo, dos de los anteriores son ampliamente utilizados para la visualización, es decir
- Matplotlib: es una biblioteca de visualización increíble en Python para gráficos 2D de arrays. Es una biblioteca de visualización de datos multiplataforma construida en arrays NumPy y diseñada para trabajar con la pila SciPy más amplia. Use el siguiente comando para instalar esta biblioteca:
pip install matplotlib
- Seaborn: esta biblioteca se encuentra encima de matplotlib . En cierto sentido, tiene algunos sabores de matplotlib mientras que, desde el punto de vista de la visualización, es mucho mejor que matplotlib y también tiene funciones adicionales. Use el siguiente comando para instalar esta biblioteca:
pip install seaborn
Enfoque paso a paso
- Importar módulos requeridos
- Cargue el conjunto de datos.
- Muestra los datos y las restricciones del conjunto de datos cargado.
- Use diferentes métodos para visualizar varias ilustraciones de los datos.
visualizaciones
A continuación se muestran algunos programas que indican los datos e ilustran varias visualizaciones de esos datos:
Ejemplo 1:
Python3
# importing pandas module
import pandas as pd
# load the dataset
data = pd.read_csv('crop.csv')
# display top 5 values
data.head()
Producción:
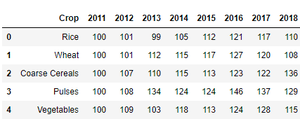
Estas son las 5 filas principales del conjunto de datos utilizado.
Ejemplo 2:
Python3
# data description data.info()
Producción:
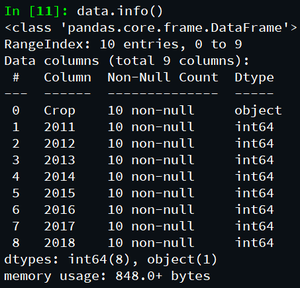
Estas son las restricciones de datos del conjunto de datos.
Ejemplo 3:
Python3
# 2011 crop data in histogram analysis data['2011'].hist()
Producción:
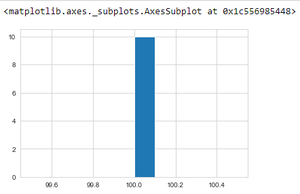
El programa anterior muestra los datos de producción de cultivos en el año 2011 usando un histograma.
Ejemplo 4:
Python3
# 2012 crop data in histogram analysis data['2012'].hist()
Producción:
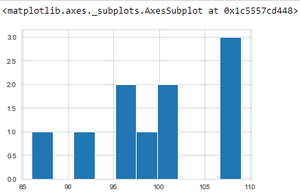
El programa anterior muestra los datos de producción de cultivos en el año 2012 usando un histograma.
Ejemplo 4:
Python3
# 2013 crop data in histogram analysis data['2013'].hist()
Producción:
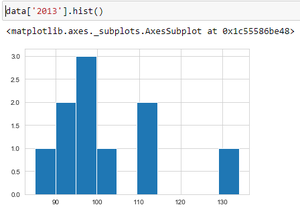
El programa anterior muestra los datos de producción de cultivos en el año 2013 usando un histograma.
Ejemplo 5:
Python3
# display all year data data.hist()
Producción:
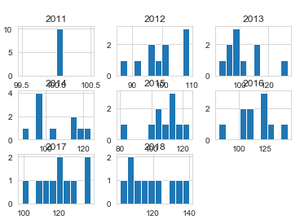
El programa anterior muestra los datos de producción de cultivos de todos los períodos de tiempo disponibles (año) usando múltiples histogramas.
Ejemplo 6:
Python3
# import seaborn module
import seaborn as sns
# setting style
sns.set_style("whitegrid")
# plotting data using boxplot for 2013 - 2014
sns.boxplot(x='2013', y='2014', data=data)
Producción:
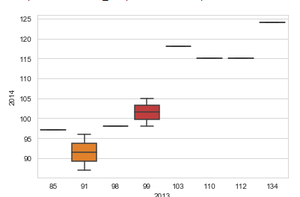
Comparación de producciones de cultivos en el año 2013 y 2014 usando diagrama de caja.
Ejemplo 7:
Python3
# scatter plot 2013 data vs 2014 data plt.scatter(data['2013'],data['2014']) plt.show()
Producción:
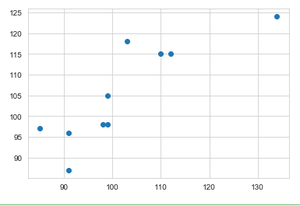
Comparación de la producción de cultivos en el año 2013 y 2014 mediante diagrama de dispersión.
Ejemplo 8:
Python3
# line plot 2013 data vs 2014 data plt.plot(data['2013'],data['2014']) plt.show()
Producción:
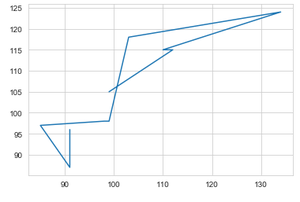
Comparación de las producciones de cultivos en el año 2013 y 2014 utilizando un gráfico de líneas.
Ejemplo 9:
Python3
# import required modules import matplotlib.pyplot as plt from scipy import stats # assign data x = data['2017'] y = data['2018'] # linear regression 2017 data vs 2018 data slope, intercept, r, p, std_err = stats.linregress(x, y) # function to return slope def myfunc(x): return slope * x + intercept mymodel = list(map(myfunc, x)) # scatter plt.scatter(x, y) # plotting the data plt.plot(x, mymodel) # display the figure plt.show()
Producción:
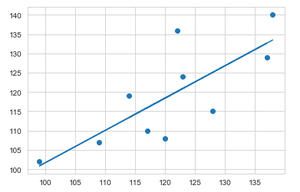
Aplicación de regresión lineal para visualizar y comparar datos de producción de cultivos previstos entre el año 2017 y 2018.
Ejemplo 10:
Python3
# import required modules import matplotlib.pyplot as plt from scipy import stats # assign data x = data['2016'] y = data['2017'] # linear regression 2017 data vs 2018 data slope, intercept, r, p, std_err = stats.linregress(x, y) # function to return slope def myfunc(x): return slope * x + intercept mymodel = list(map(myfunc, x)) # scatter plt.scatter(x, y) # plotting the data plt.plot(x, mymodel) # display the figure plt.show()
Producción:
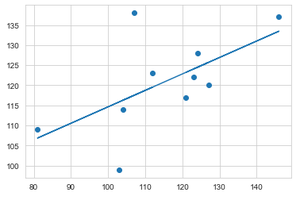
Aplicación de regresión lineal para visualizar y comparar datos de producción de cultivos previstos entre el año 2016 y 2017.
Vídeo de demostración
Este video muestra cómo representar la visualización de datos anterior y predecir datos, utilizando Jupyter Notebook desde cero.
De esta manera, se pueden calcular varias visualizaciones de datos y predicciones.
Publicación traducida automáticamente
Artículo escrito por sravankumar8128 y traducido por Barcelona Geeks. The original can be accessed here. Licence: CCBY-SA