En este artículo, aprenderá varios conceptos de web scraping y se familiarizará con el scraping de varios tipos de sitios web y sus datos. El objetivo es raspar datos de la página de inicio de Wikipedia y analizarlos a través de varias técnicas de raspado web. Se familiarizará con varias técnicas de web scraping, módulos de python para web scraping y procesos de extracción y procesamiento de datos. El web scraping es un proceso automático de extracción de información de la web. Este artículo le dará una idea detallada del raspado web, su comparación con el rastreo web y por qué debería optar por el raspado web.
Introducción al web scraping y Python
Básicamente es una técnica o un proceso en el que grandes cantidades de datos de una gran cantidad de sitios web se pasan a través de un software de web scraping codificado en un lenguaje de programación y, como resultado, se extraen datos estructurados que se pueden guardar localmente en nuestros dispositivos preferiblemente. en hojas de Excel, JSON u hojas de cálculo. Ahora, no tenemos que copiar y pegar manualmente los datos de los sitios web, pero un raspador puede realizar esa tarea por nosotros en un par de segundos.
El web scraping también se conoce como Screen Scraping, Web Data Extraction, Web Harvesting, etc.
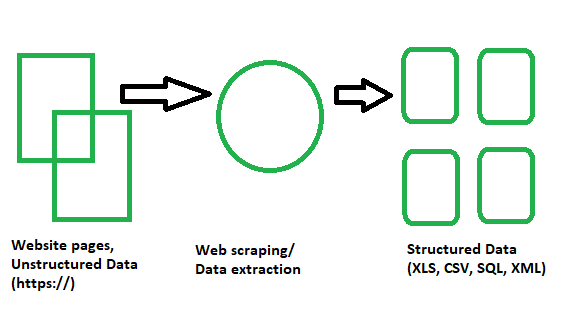
Proceso de web scraping
Esto ayuda a los programadores a escribir código claro y lógico para proyectos de pequeña y gran escala. Python es conocido principalmente como el mejor lenguaje web scraper . Es más como un todo terreno y puede manejar la mayoría de los procesos relacionados con el rastreo web sin problemas. Scrapy y Beautiful Soup se encuentran entre los marcos ampliamente utilizados basados en Python que hacen que raspar usando este lenguaje sea una ruta tan fácil de tomar.
Una breve lista de las bibliotecas de Python utilizadas para el web scraping
¡Veamos las bibliotecas de web scraping en Python!
- Requests (HTTP para humanos) Biblioteca para Web Scraping : se utiliza para realizar varios tipos de requests HTTP como GET, POST, etc. Es la más básica pero la más esencial de todas las bibliotecas.
- Biblioteca lxml para Web Scraping : la biblioteca lxml proporciona un análisis sintáctico súper rápido y de alto rendimiento de contenido HTML y XML de sitios web. Si planea raspar grandes conjuntos de datos, este es el que debe elegir.
- Beautiful Soup Library for Web Scraping : su trabajo consiste en crear un árbol de análisis para analizar el contenido. Una biblioteca de inicio perfecta para principiantes y muy fácil de trabajar.
- Selenium Library for Web Scraping : originalmente creada para pruebas automatizadas de aplicaciones web, esta biblioteca supera el problema al que se enfrentan todas las bibliotecas anteriores, es decir, extraer contenido de sitios web poblados dinámicamente. Esto lo hace más lento y no apto para proyectos de nivel industrial.
- Scrapy para Web Scraping : el BOSS de todas las bibliotecas, un marco completo de web scraping que es asíncrono en su uso. Esto lo hace increíblemente rápido y aumenta la eficiencia.
Implementación práctica – Scraping de Wikipedia

Pasos del web scraping
Paso 1: ¿Cómo usar python para web scraping?
- Necesitamos Python IDE y debemos estar familiarizados con su uso.
- Virtualenv es una herramienta para crear entornos Python aislados. Con la ayuda de virtualenv , podemos crear una carpeta que contenga todos los ejecutables necesarios para usar los paquetes que requiere nuestro proyecto de Python. Aquí podemos agregar y modificar módulos de python sin afectar ninguna instalación global.
- Necesitamos instalar varios módulos y bibliotecas de Python usando el comando pip para nuestro propósito. Pero siempre debemos tener en cuenta si el sitio web que estamos raspando es legal o no.
Requisitos:
- Requests: es una biblioteca HTTP eficiente utilizada para acceder a páginas web.
- Urlib3: se utiliza para recuperar datos de URL.
- Selenium: es un conjunto de pruebas automatizadas de código abierto para aplicaciones web en diferentes navegadores y plataformas.
Instalación:
pip install virtualenv python -m pip install selenium python -m pip install requests python -m pip install urllib3

Imagen de muestra durante la instalación
Paso 2: Introducción a la biblioteca de requests
- Aquí, aprenderemos varios módulos de Python para obtener datos de la web.
- La biblioteca de requests de python se usa para descargar la página web que estamos tratando de raspar.
Requisitos:
- IDE de Python
- Módulos de Python
- Biblioteca de requests
Tutorial de código:
URL: https://en.wikipedia.org/wiki/Main_Page
Python3
# import required modules
import requests
# get URL
page = requests.get("https://en.wikipedia.org/wiki/Main_Page")
# display status code
print(page.status_code)
# display scrapped data
print(page.content)
Producción:
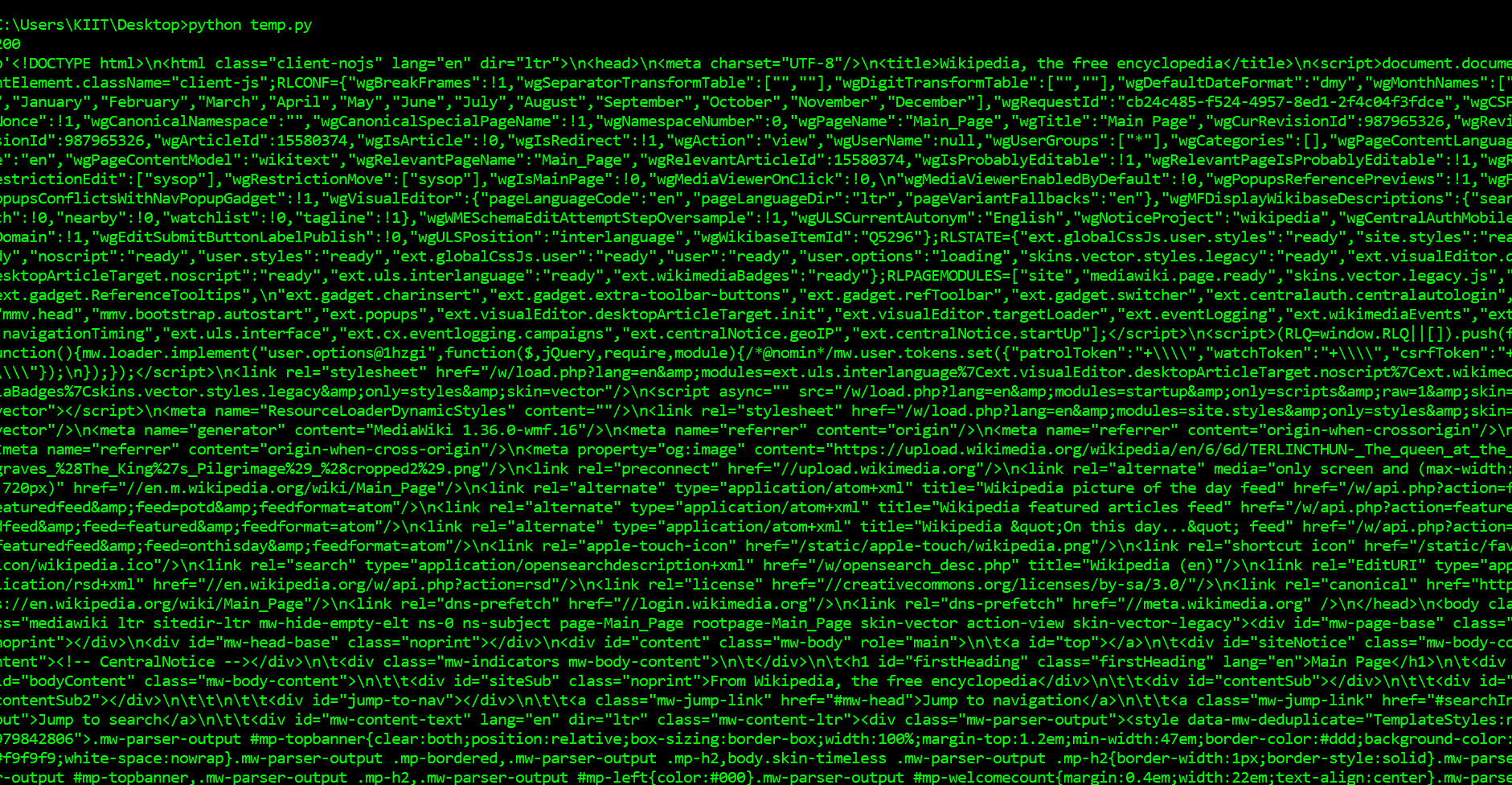
Lo primero que tendremos que hacer para raspar una página web es descargar la página. Podemos descargar páginas usando la biblioteca de requests de Python. La biblioteca de requests realizará una solicitud GET a un servidor web, que descargará el contenido HTML de una página web determinada para nosotros. Hay varios tipos de requests que podemos realizar mediante requests, de las cuales GET es solo una. La URL de nuestro sitio web de muestra es https://en.wikipedia.org/wiki/Main_Page. La tarea es descargarlo usando el método request.get() . Después de ejecutar nuestra solicitud, obtenemos un objeto de Respuesta. Este objeto tiene una propiedad status_code , que indica si la página se descargó correctamente. Y una propiedad de contenido que proporciona el contenido HTML de la página web como salida.
Paso 3: Introducción a Beautiful Soup para el análisis de páginas
Tenemos muchos módulos de Python para la extracción de datos. Vamos a usar BeautifulSoup para nuestro propósito.
- BeautifulSoup es una biblioteca de Python para extraer datos de archivos HTML y XML.
- Necesita una entrada (documento o URL) para crear un objeto de sopa ya que no puede obtener una página web por sí mismo.
- Tenemos otros módulos como expresión regular, lxml para el mismo propósito.
- Luego procesamos los datos en formato CSV o JSON o MySQL.
Requisitos:
- PythonIDE
- Módulos de Python
- Hermosa biblioteca de sopas
pip install bs4
Tutorial de código:
Python3
# import required modules
from bs4 import BeautifulSoup
import requests
# get URL
page = requests.get("https://en.wikipedia.org/wiki/Main_Page")
# scrape webpage
soup = BeautifulSoup(page.content, 'html.parser')
# display scrapped data
print(soup.prettify())
Producción:
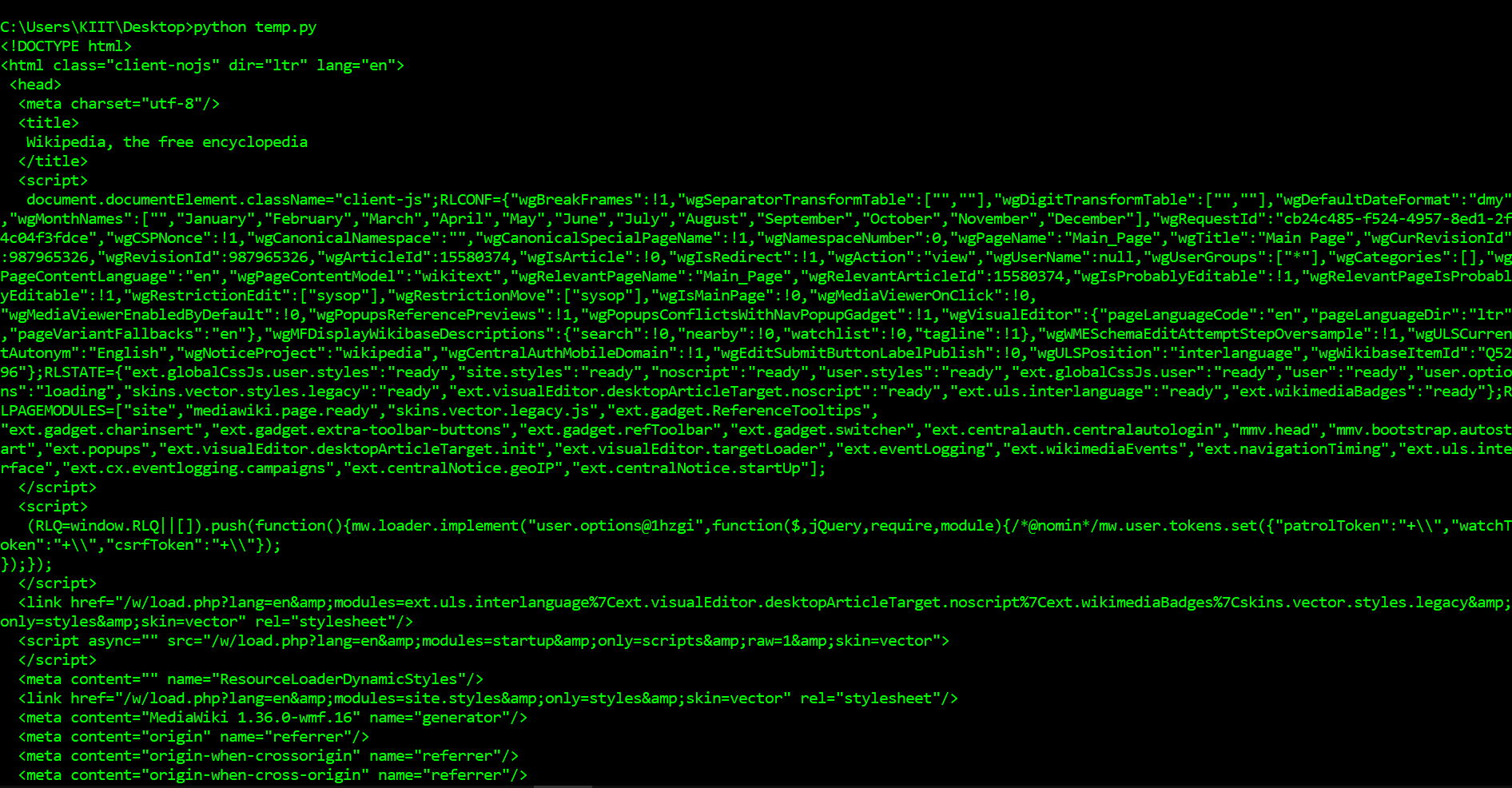
Como puede ver arriba, ahora hemos descargado un documento HTML. Podemos usar la biblioteca BeautifulSoup para analizar este documento y extraer el texto de la etiqueta p . Primero tenemos que importar la biblioteca y crear una instancia de la clase BeautifulSoup para analizar nuestro documento. Ahora podemos imprimir el contenido HTML de la página, con un buen formato, usando el método embellecer en el objeto BeautifulSoup . Como todas las etiquetas están anidadas, podemos movernos por la estructura un nivel a la vez. Primero podemos seleccionar todos los elementos en el nivel superior de la página usando la propiedad de los niños de la sopa. Tenga en cuenta que los niños devuelven un generador de listas, por lo que debemos llamar a la función de lista en él.
Paso 4: profundizar más en Beautiful Soup
Tres características que hacen que Beautiful Soup sea tan poderosa:
- Beautiful Soup proporciona algunos métodos simples y modismos Pythonic para navegar, buscar y modificar un árbol de análisis: un conjunto de herramientas para diseccionar un documento y extraer lo que necesita. No se necesita mucho código para escribir una aplicación.
- Beautiful Soup convierte automáticamente los documentos entrantes a Unicode y los documentos salientes a UTF-8. No tiene que pensar en codificaciones a menos que el documento no especifique una codificación y Beautiful Soup no pueda detectar ninguna. Entonces solo tienes que especificar la codificación original.
- Beautiful Soup se encuentra encima de los populares analizadores de Python como lxml y html5lib, lo que le permite probar diferentes estrategias de análisis o intercambiar velocidad por flexibilidad. Luego, solo tenemos que procesar nuestros datos en un formato adecuado, como CSV, JSON o MySQL.
Requisitos:
- PythonIDE
- Módulos de Python
- Hermosa biblioteca de sopas
Tutorial de código:
Python3
# import required modules
from bs4 import BeautifulSoup
import requests
# get URL
page = requests.get("https://en.wikipedia.org/wiki/Main_Page")
# scrape webpage
soup = BeautifulSoup(page.content, 'html.parser')
list(soup.children)
# find all occurrence of p in HTML
# includes HTML tags
print(soup.find_all('p'))
print('\n\n')
# return only text
# does not include HTML tags
print(soup.find_all('p')[0].get_text())
Producción:

Lo que hicimos anteriormente fue útil para descubrir cómo navegar por una página, pero se necesitaron muchos comandos para hacer algo bastante simple. Si queremos extraer una sola etiqueta, podemos usar el método find_all() , que encontrará todas las instancias de una etiqueta en una página. Tenga en cuenta que find_all() devuelve una lista, por lo que tendremos que recorrer o usar la indexación de listas para extraer texto. Si, en cambio, solo desea encontrar la primera instancia de una etiqueta, puede usar el método de búsqueda, que devolverá un solo objeto BeautifulSoup .
Paso 5: Explorar la estructura de la página con las herramientas de Chrome Dev y extraer información
Lo primero que deberemos hacer es inspeccionar la página usando Chrome Devtools . Si está utilizando otro navegador, Firefox y Safari tienen equivalentes. Sin embargo, se recomienda usar Chrome.
Puede iniciar las herramientas para desarrolladores en Chrome haciendo clic en Ver -> Desarrollador -> Herramientas para desarrolladores . Deberías terminar con un panel en la parte inferior del navegador como el que ves a continuación. Asegúrese de que el panel Elementos esté resaltado. El panel de elementos le mostrará todas las etiquetas HTML en la página y le permitirá navegar a través de ellas. ¡Es una función realmente útil! Al hacer clic con el botón derecho en la página cerca de donde dice Pronóstico extendido y luego hacer clic en Inspeccionar , abriremos la etiqueta que contiene el texto Pronóstico extendido en el panel de elementos.

Analizando con las herramientas de Chrome Dev
Tutorial de código:
Python3
# import required modules
from bs4 import BeautifulSoup
import requests
# get URL
page = requests.get("https://en.wikipedia.org/wiki/Main_Page")
# scrape webpage
soup = BeautifulSoup(page.content, 'html.parser')
# create object
object = soup.find(id="mp-left")
# find tags
items = object.find_all(class_="mp-h2")
result = items[0]
# display tags
print(result.prettify())
Producción:

Aquí tenemos que seleccionar ese elemento que tiene una identificación y contiene niños que tienen la misma clase. Por ejemplo, el elemento con id mp-left es el elemento principal y sus elementos secundarios anidados tienen la clase mp-h2 . Así que imprimiremos la información con el primer hijo anidado y la embelleceremos usando la función embellecer() .
Conclusión y profundizando en Web scraping
Aprendimos varios conceptos de raspado web y datos raspados de la página de inicio de Wikipedia y los analizamos a través de varias técnicas de raspado web. El artículo nos ayudó a obtener una idea detallada del raspado web, su comparación con el rastreo web y por qué debería optar por el raspado web. También aprendimos sobre los componentes y el funcionamiento de un web scraper.
Si bien el web scraping abre muchas puertas para fines éticos, puede haber un raspado de datos no intencionado por parte de profesionales poco éticos, lo que crea un riesgo moral para muchas empresas y organizaciones donde pueden recuperar los datos fácilmente y usarlos para sus propios fines egoístas. El raspado de datos en combinación con big data puede proporcionar la inteligencia de mercado de la empresa y ayudarla a identificar tendencias y patrones críticos e identificar las mejores oportunidades y soluciones. Por lo tanto, es bastante exacto predecir que el raspado de datos se puede actualizar pronto.

Usos del web scraping
Publicación traducida automáticamente
Artículo escrito por garingh128 y traducido por Barcelona Geeks. The original can be accessed here. Licence: CCBY-SA