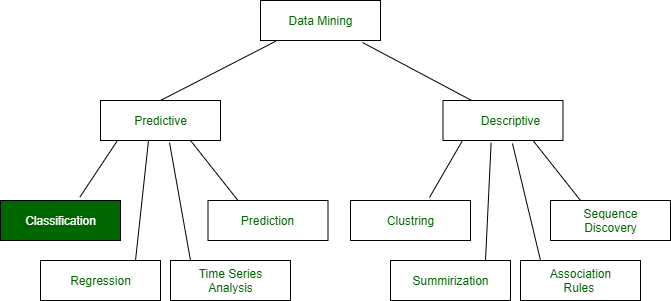
Minería de datos : la minería de datos en términos generales significa extraer o profundizar en datos que se encuentran en diferentes formas para obtener patrones y obtener conocimiento sobre ese patrón. En el proceso de minería de datos, primero se clasifican grandes conjuntos de datos, luego se identifican patrones y se establecen relaciones para realizar análisis de datos y resolver problemas.
Clasificación : Es una tarea de análisis de datos, es decir, el proceso de encontrar un modelo que describa y distinga clases de datos y conceptos. La clasificación es el problema de identificar a cuál de un conjunto de categorías (subpoblaciones) pertenece una nueva observación, sobre la base de un conjunto de datos de entrenamiento que contiene observaciones y cuyas categorías se conocen.
Ejemplo : Antes de iniciar cualquier proyecto, debemos comprobar su viabilidad. En este caso, se requiere un clasificador para predecir etiquetas de clase como ‘Seguro’ y ‘Riesgo’ para adoptar el Proyecto y aprobarlo. Es un proceso de dos pasos como:
- Paso de aprendizaje (fase de entrenamiento) : construcción del modelo de clasificación
Se utilizan diferentes algoritmos para construir un clasificador haciendo que el modelo aprenda usando el conjunto de entrenamiento disponible. El modelo tiene que ser entrenado para la predicción de resultados precisos. - Paso de clasificación : modelo utilizado para predecir etiquetas de clase y probar el modelo construido en datos de prueba y, por lo tanto, estimar la precisión de las reglas de clasificación.
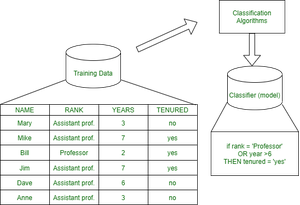
Los datos de prueba se utilizan para estimar la precisión de la regla de clasificación.
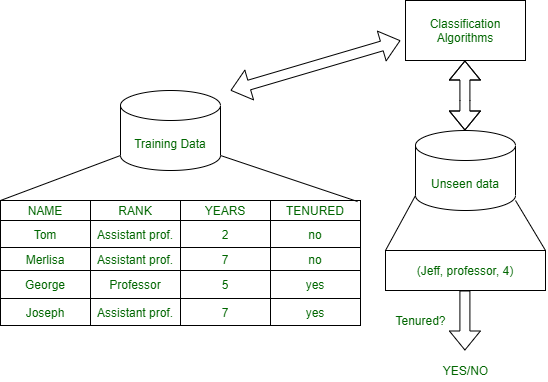
Los datos de prueba se utilizan para estimar la precisión de la regla de clasificación.
Entrenamiento y prueba:
Supongamos que hay una persona que está sentada debajo de un ventilador y el ventilador comienza a caer sobre él, debe hacerse a un lado para no lastimarse. Entonces, esta es su parte de entrenamiento para alejarse. Durante la prueba, si la persona ve que algún objeto pesado se le acerca o le cae encima y se hace a un lado, el sistema se prueba positivamente y, si la persona no se mueve a un lado, el sistema se prueba negativamente.
Lo mismo ocurre con los datos, deben ser entrenados para obtener los mejores y más precisos resultados.
Hay ciertos tipos de datos asociados con la minería de datos que realmente nos dicen el formato del archivo (ya sea en formato de texto o en formato numérico).
Atributos: representa diferentes características de un objeto. Los diferentes tipos de atributos son:
- Binario : Posee solo dos valores, es decir, Verdadero o Falso
. Ejemplo: Supongamos que hay una encuesta que evalúa algunos productos. Tenemos que comprobar si es útil o no. Por lo tanto, el Cliente debe responder Sí o No.
Utilidad del producto: Sí / No- Simétrico : Ambos valores son igualmente importantes en todos los aspectos.
- Asimétrico : cuando ambos valores pueden no ser importantes.
- Nominal : Cuando son posibles más de dos resultados. Está en forma alfabética en lugar de estar en forma entera.
Ejemplo : Hay que elegir algún material pero de diferentes colores. Entonces, el color puede ser amarillo, verde, negro, rojo.
Diferentes colores: rojo, verde, negro, amarillo.- Ordinal : Valores que deben tener algún orden significativo.
Ejemplo: suponga que hay hojas de calificaciones de algunos estudiantes que pueden contener diferentes calificaciones según su desempeño, como A, B, C, D
Calificaciones: A, B, C, D - Continuo : puede tener un número infinito de valores, es de tipo flotante
Ejemplo: medir el peso de unos pocos estudiantes en una secuencia u orden, es decir, 50, 51, 52, 53
Peso: 50, 51, 52, 53 - Discreto : Número finito de valores.
Ejemplo: Notas de un alumno en algunas materias: 65, 70, 75, 80, 90
Notas: 65, 70, 75, 80, 90
- Ordinal : Valores que deben tener algún orden significativo.
Sintaxis:
- Notación matemática: la clasificación se basa en construir una función tomando el vector de características de entrada «X» y prediciendo su resultado «Y» (Respuesta cualitativa tomando valores en el conjunto C)
- Aquí se utiliza el clasificador (o modelo), que es una función supervisada, se puede diseñar manualmente en función del conocimiento de los expertos. Ha sido construido para predecir etiquetas de clase (Ejemplo: Etiqueta – “Sí” o “No” para la aprobación de algún evento).
Los clasificadores se pueden clasificar en dos tipos principales:
- Discriminativo : es un clasificador muy básico y determina solo una clase para cada fila de datos. Intenta modelar simplemente dependiendo de los datos observados, depende en gran medida de la calidad de los datos más que de las distribuciones.
Ejemplo : Regresión logística
Aceptación de un estudiante en una universidad (se deben considerar la prueba y las calificaciones)
Suponga que hay pocos estudiantes y el resultado de ellos es el siguiente: - Generativo : modela la distribución de clases individuales e intenta aprender el modelo que genera los datos detrás de escena al estimar suposiciones y distribuciones del modelo. Se utiliza para predecir los datos no vistos.
Ejemplo : clasificador Naive Bayes
que detecta correos electrónicos no deseados al observar los datos anteriores. Supongamos 100 correos electrónicos y eso también dividido en 1:4, es decir, Clase A: 25 % (correos electrónicos no deseados) y Clase B: 75 % (correos electrónicos que no son correo no deseado). Ahora, si un usuario quiere verificar que si un correo electrónico contiene la palabra barato, entonces eso puede denominarse Spam.
Parece ser que en la Clase A (es decir, en el 25% de los datos), 20 de los 25 correos electrónicos son spam y el resto no.
Y en la Clase B (es decir, en el 75 % de los datos), 70 de 75 correos electrónicos no son spam y el resto es spam.
Entonces, si el correo electrónico contiene la palabra barato, ¿cuál es la probabilidad de que sea spam? (= 80%)
Clasificadores de aprendizaje automático:
- Árboles de decisión
- Clasificadores bayesianos
- Redes neuronales
- K-vecino más cercano
- Máquinas de vectores de soporte
- Regresión lineal
- Regresión logística
Herramientas e idiomas asociados: se utilizan para extraer/extraer información útil de los datos sin procesar.
- Idiomas principales utilizados : R, SAS, Python, SQL
- Principales herramientas utilizadas : RapidMiner, Orange, KNIME, Spark, Weka
- Bibliotecas utilizadas : Jupyter, NumPy, Matplotlib, Pandas, ScikitLearn, NLTK, TensorFlow, Seaborn, Basemap, etc.
Ejemplos de la vida real :
- Análisis de la canasta de mercado:
es una técnica de modelado que se ha asociado con transacciones frecuentes de compra de alguna combinación de artículos.
Ejemplo : Amazon y muchos otros minoristas utilizan esta técnica. Al ver algunos productos, se muestran ciertas sugerencias de productos básicos que algunas personas compraron en el pasado. - Pronóstico del tiempo:
es necesario observar los patrones cambiantes en las condiciones climáticas en función de parámetros como la temperatura, la humedad y la dirección del viento. Esta aguda observación también requiere el uso de registros previos para poder predecirla con precisión.
ventajas:
- Los métodos basados en minería son rentables y eficientes
- Ayuda en la identificación de sospechosos criminales.
- Ayuda a predecir el riesgo de enfermedades.
- Ayuda a Bancos e Instituciones Financieras a identificar morosos para que puedan aprobar Tarjetas, Préstamo, etc.
Desventajas:
Privacidad: cuando los datos son posibles, una empresa puede proporcionar información sobre sus clientes a otros proveedores o usar esta información para su beneficio.
Problema de precisión: la selección del modelo preciso debe estar ahí para obtener la mejor precisión y resultado.
APLICACIONES:
- Marketing y venta al por menor
- Fabricación
- Industria de las telecomunicaciones
- Detección de intrusos
- Sistema educativo
- Detección de fraude
ESENCIA DE LA MINERÍA DE DATOS:
- Elegir el método de clasificación correcto, como árboles de decisión, redes bayesianas o redes neuronales.
- Necesita una muestra de datos, donde se conocen todos los valores de clase. Luego, los datos se dividirán en dos partes, un conjunto de entrenamiento y un conjunto de prueba.
Ahora, el conjunto de entrenamiento se entrega a un algoritmo de aprendizaje, que deriva un clasificador. Luego, el clasificador se prueba con el conjunto de prueba, donde todos los valores de clase están ocultos.
Si el clasificador clasifica la mayoría de los casos en el conjunto de prueba correctamente, se puede suponer que también funciona con precisión en los datos futuros, de lo contrario, puede ser un modelo incorrecto elegido.
Publicación traducida automáticamente
Artículo escrito por saumyasaxena2730 y traducido por Barcelona Geeks. The original can be accessed here. Licence: CCBY-SA