Este artículo habla sobre los problemas de los RNN convencionales, es decir, los gradientes que se desvanecen y explotan, y proporciona una solución conveniente a estos problemas en forma de memoria a largo plazo (LSTM). Long Short-Term Memory es una versión avanzada de la arquitectura de red neuronal recurrente (RNN) que fue diseñada para modelar secuencias cronológicas y sus dependencias de largo alcance con mayor precisión que las RNN convencionales. Los aspectos más destacados incluyen el diseño interior de una celda LSTM básica, las variaciones introducidas en la arquitectura LSTM y algunas aplicaciones de LSTM que tienen una gran demanda. También hace una comparación entre LSTM y GRU. El artículo concluye con una lista de desventajas de la red LSTM y una breve introducción de los próximos modelos basados en la atención que están reemplazando rápidamente a los LSTM en el mundo real.
Introducción:
Las redes LSTM son una extensión de las redes neuronales recurrentes (RNN) introducidas principalmente para manejar situaciones en las que fallan las RNN. Hablando de RNN, es una red que funciona en la entrada presente tomando en consideración la salida anterior (retroalimentación) y almacenándola en su memoria por un corto período de tiempo (memoria a corto plazo). De sus diversas aplicaciones, las más populares se encuentran en los campos del procesamiento del habla, el control no markoviano y la composición musical. Sin embargo, existen inconvenientes para los RNN. Primero, no puede almacenar información durante un período de tiempo más largo. A veces, se requiere una referencia a cierta información almacenada hace mucho tiempo para predecir la salida actual. Pero los RNN son absolutamente incapaces de manejar tales «dependencias a largo plazo». Segundo, no existe un control más preciso sobre qué parte del contexto debe llevarse adelante y cuánto del pasado debe «olvidarse». Otros problemas con los RNN son los gradientes de explosión y desaparición (explicados más adelante) que ocurren durante el proceso de entrenamiento de una red a través del retroceso. Por lo tanto, la memoria a corto plazo (LSTM) entró en escena. Ha sido diseñado de tal manera que el problema del gradiente de fuga se elimina casi por completo, mientras que el modelo de entrenamiento permanece inalterado. Los retrasos de tiempo prolongados en ciertos problemas se superan mediante LSTM, donde también manejan el ruido, las representaciones distribuidas y los valores continuos. Con los LSTM, no es necesario mantener un número finito de estados de antemano como se requiere en el modelo oculto de Markov (HMM). Los LSTM nos brindan una amplia gama de parámetros, como tasas de aprendizaje y sesgos de entrada y salida. Por lo tanto, no hay necesidad de ajustes finos. La complejidad para actualizar cada peso se reduce a O(1) con LSTM, similar a la de Back Propagation Through Time (BPTT), lo cual es una ventaja.
Gradientes explosivos y que desaparecen:
Durante el proceso de entrenamiento de una red, el objetivo principal es minimizar la pérdida (en términos de error o costo) observada en la salida cuando se envían datos de entrenamiento a través de ella. Calculamos el gradiente, es decir, la pérdida con respecto a un conjunto particular de pesos, ajustamos los pesos en consecuencia y repetimos este proceso hasta obtener un conjunto óptimo de pesos para el cual la pérdida es mínima. Este es el concepto de retroceso. A veces, sucede que el gradiente es casi insignificante. Cabe señalar que el gradiente de una capa depende de ciertos componentes en las capas sucesivas. Si alguna de estas componentes es pequeña (menos de 1), el resultado obtenido, que es el gradiente, será aún menor. Esto se conoce como el efecto de escala. Cuando este gradiente se multiplica por la tasa de aprendizaje, que en sí misma es un valor pequeño que oscila entre 0,1 y 0,001, resulta en un valor más pequeño. Como consecuencia, la alteración en los pesos es bastante pequeña, produciendo casi la misma salida que antes. De manera similar, si los gradientes tienen un valor bastante grande debido a los grandes valores de los componentes, los pesos se actualizan a un valor más allá del valor óptimo. Esto se conoce como el problema de la explosión de gradientes. Para evitar este efecto de escala, la unidad de red neuronal se reconstruyó de tal manera que el factor de escala se fijó en uno. Luego, la celda se enriqueció con varias unidades de activación y se denominó LSTM. Esto se conoce como el problema de la explosión de gradientes. Para evitar este efecto de escala, la unidad de red neuronal se reconstruyó de tal manera que el factor de escala se fijó en uno. Luego, la celda se enriqueció con varias unidades de activación y se denominó LSTM. Esto se conoce como el problema de la explosión de gradientes. Para evitar este efecto de escala, la unidad de red neuronal se reconstruyó de tal manera que el factor de escala se fijó en uno. Luego, la celda se enriqueció con varias unidades de activación y se denominó LSTM.
Arquitectura:
La diferencia básica entre las arquitecturas de RNN y LSTM es que la capa oculta de LSTM es una unidad cerrada o celda cerrada. Consta de cuatro capas que interactúan entre sí para producir la salida de esa celda junto con el estado de la celda. Estas dos cosas luego se pasan a la siguiente capa oculta. A diferencia de los RNN que tienen la única capa de red neuronal única de tanh, los LSTM se componen de tres puertas sigmoideas logísticas y una capa de tanh. Se han introducido puertas para limitar la información que pasa a través de la celda. Determinan qué parte de la información necesitará la siguiente celda y qué parte se descartará. La salida suele estar en el rango de 0-1, donde ‘0’ significa ‘rechazar todo’ y ‘1’ significa ‘incluir todo’.
Capas ocultas de LSTM:
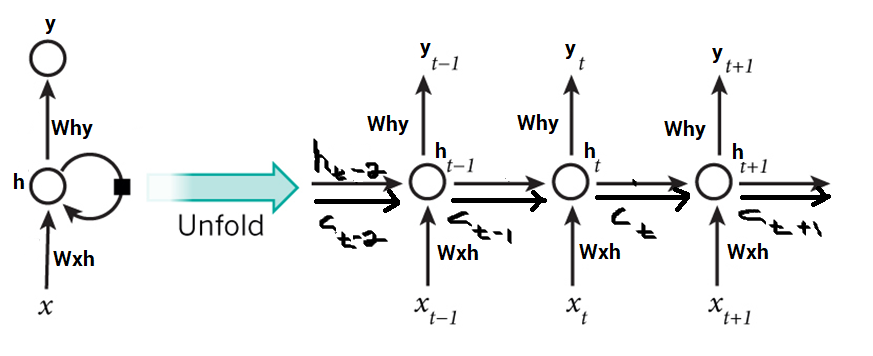
Cada celda LSTM tiene tres entradas y  dos salidas
dos salidas  y . Para un tiempo dado t, es el estado oculto, es el estado de la celda o memoria, es el punto de datos o entrada actual. La primera capa sigmoidea tiene dos entradas, y dónde está el estado oculto de la celda anterior. Se conoce como la puerta de olvido ya que su salida selecciona la cantidad de información de la celda anterior que se incluirá. La salida es un número en [0,1] que se multiplica (punto a punto) con el estado de celda anterior .
y . Para un tiempo dado t, es el estado oculto, es el estado de la celda o memoria, es el punto de datos o entrada actual. La primera capa sigmoidea tiene dos entradas, y dónde está el estado oculto de la celda anterior. Se conoce como la puerta de olvido ya que su salida selecciona la cantidad de información de la celda anterior que se incluirá. La salida es un número en [0,1] que se multiplica (punto a punto) con el estado de celda anterior . 


LSTM convencional:
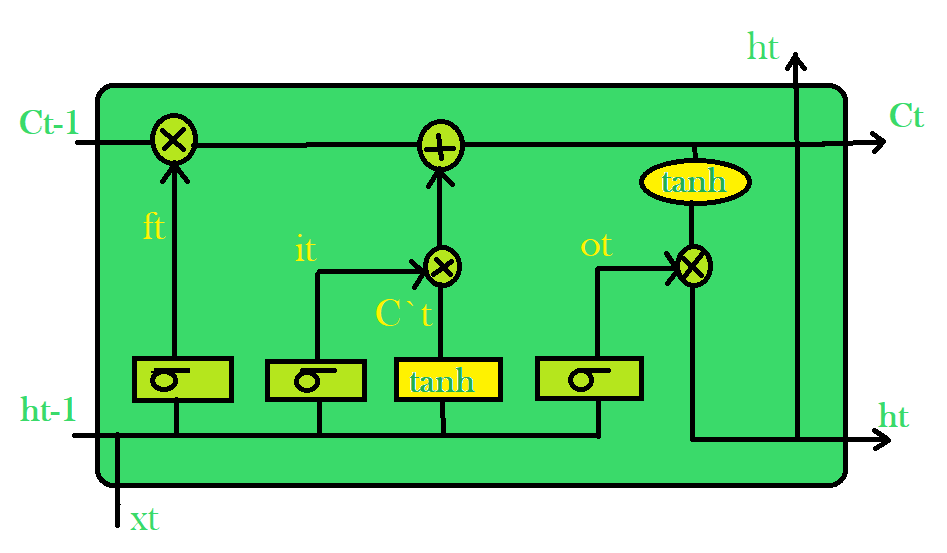
La segunda capa sigmoidea es la puerta de entrada que decide qué nueva información se agregará a la celda. Se necesitan dos entradas y . La capa tanh crea un vector de los nuevos valores candidatos. Juntas, estas dos capas determinan la información que se almacenará en el estado de la celda. Su multiplicación por puntos  nos dice la cantidad de información que se agregará al estado de la celda. Luego, el resultado se suma con el resultado de la puerta de olvido multiplicado con el estado de celda anterior
nos dice la cantidad de información que se agregará al estado de la celda. Luego, el resultado se suma con el resultado de la puerta de olvido multiplicado con el estado de celda anterior  para producir el estado de celda actual . A continuación, la salida de la celda se calcula utilizando un sigmoide y una capa tanh. La capa sigmoidea decide qué parte del estado de la celda estará presente en la salida, mientras que la capa tanh cambia la salida en el rango de [-1,1]. Los resultados de las dos capas se multiplican por puntos para producir la salida ht de la celda.
para producir el estado de celda actual . A continuación, la salida de la celda se calcula utilizando un sigmoide y una capa tanh. La capa sigmoidea decide qué parte del estado de la celda estará presente en la salida, mientras que la capa tanh cambia la salida en el rango de [-1,1]. Los resultados de las dos capas se multiplican por puntos para producir la salida ht de la celda.
Variaciones:
Con la creciente popularidad de los LSTM, se han intentado varias modificaciones en la arquitectura LSTM convencional para simplificar el diseño interno de las celdas para que funcionen de una manera más eficiente y para reducir la complejidad computacional. Gers y Schmidhuber introdujeron conexiones de mirilla que permitían a las capas de puerta tener conocimiento sobre el estado de la celda en cada instante. Algunos LSTM también utilizaron una entrada acoplada y una puerta de olvido en lugar de dos puertas separadas que ayudaron a tomar ambas decisiones simultáneamente. Otra variación fue el uso de Gated Recurrent Unit (GRU) que mejoró la complejidad del diseño al reducir el número de puertas. Utiliza una combinación del estado de la celda y el estado oculto y también una puerta de actualización que se ha olvidado y las puertas de entrada se fusionaron en ella.
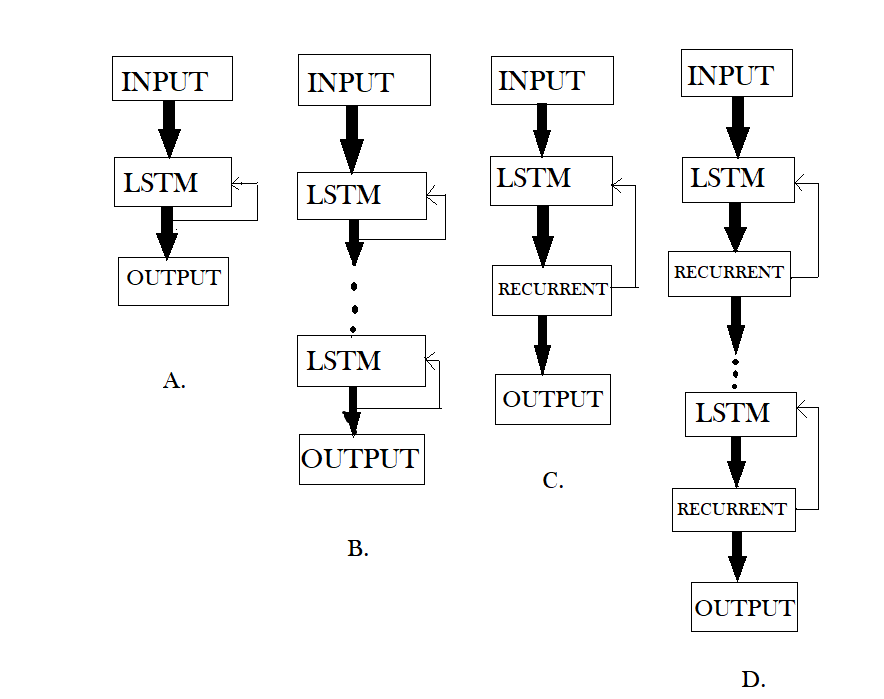
LSTM (Figura-A), DLSTM (Figura-B), LSTMP (Figura-C) y DLSTMP (Figura-D)
- La figura A representa el aspecto de una red LSTM básica. Aquí solo se muestra una capa de LSTM entre una capa de entrada y una de salida.
- La Figura-B representa Deep LSTM que incluye varias capas LSTM entre la entrada y la salida. La ventaja es que los valores de entrada alimentados a la red no solo pasan por varias capas LSTM, sino que también se propagan a lo largo del tiempo dentro de una celda LSTM. Por lo tanto, los parámetros están bien distribuidos dentro de múltiples capas. Esto da como resultado un proceso completo de entradas en cada paso de tiempo.
- La Figura-C representa LSTM con la capa de proyección recurrente donde las conexiones recurrentes se toman de la capa de proyección a la entrada de la capa LSTM. Esta arquitectura fue diseñada para reducir la alta complejidad computacional de aprendizaje (O(N)) para cada paso de tiempo) del estándar LSTM RNN.
- La Figura-D representa Deep LSTM con una capa de proyección recurrente que consta de varias capas LSTM donde cada capa tiene su propia capa de proyección. La mayor profundidad es bastante útil en el caso de que el tamaño de la memoria sea demasiado grande. Tener mayor profundidad evita el sobreajuste en los modelos, ya que las entradas a la red deben pasar por muchas funciones no lineales.
GRU frente a LSTM
A pesar de ser bastante similares a los LSTM, los GRU nunca han sido tan populares. Pero, ¿qué son las GRU? GRU significa Unidades Recurrentes Cerradas. Como sugiere el nombre, estas unidades recurrentes, propuestas por Cho, también cuentan con un mecanismo cerrado para capturar dependencias de diferentes escalas de tiempo de manera efectiva y adaptativa. Tienen una puerta de actualización y una puerta de reinicio. El primero es responsable de seleccionar qué parte del conocimiento se llevará adelante, mientras que el segundo se encuentra entre dos unidades recurrentes sucesivas y decide cuánta información debe olvidarse.
Activación en el tiempo t : 
Puerta de actualización:

Activación de candidatos:

Restablecer puerta:

Otro aspecto sorprendente de las GRU es que no almacenan el estado de la celda de ninguna manera, por lo tanto, no pueden regular la cantidad de contenido de memoria a la que está expuesta la siguiente unidad. En cambio, los LSTM regulan la cantidad de información nueva que se incluye en la celda. Por otro lado, la GRU controla el flujo de información de la activación anterior al calcular la nueva activación candidata, pero no controla de forma independiente la cantidad de activación candidata que se agrega (el control está vinculado a través de la puerta de actualización).
Aplicaciones:
Los modelos LSTM deben entrenarse con un conjunto de datos de entrenamiento antes de su empleo en aplicaciones del mundo real. Algunas de las aplicaciones más exigentes se analizan a continuación:
- Modelado de lenguaje o generación de texto, que implica el cálculo de palabras cuando se alimenta una secuencia de palabras como entrada. Los modelos de lenguaje se pueden operar a nivel de carácter, nivel de n-grama, nivel de oración o incluso nivel de párrafo.
- Procesamiento de imágenes, que implica realizar el análisis de una imagen y concluir su resultado en una oración. Para ello, es necesario disponer de un conjunto de datos compuesto por una buena cantidad de fotografías con sus correspondientes leyendas descriptivas. Se utiliza un modelo que ya ha sido entrenado para predecir las características de las imágenes presentes en el conjunto de datos. Estos son datos de fotos. Luego, el conjunto de datos se procesa de tal manera que solo las palabras que son más sugerentes están presentes en él. Estos son datos de texto. Usando estos dos tipos de datos, tratamos de ajustar el modelo. El trabajo del modelo es generar una oración descriptiva para la imagen, una palabra a la vez, tomando palabras de entrada que fueron predichas previamente por el modelo y también por la imagen.
- Reconocimiento de voz y escritura a mano
- Generación de música que es bastante similar a la generación de texto donde los LSTM predicen notas musicales en lugar de texto mediante el análisis de una combinación de notas dadas como entrada.
- La traducción de idiomas implica mapear una secuencia en un idioma a una secuencia en otro idioma. De manera similar al procesamiento de imágenes, primero se limpia un conjunto de datos que contiene frases y sus traducciones y solo una parte se usa para entrenar el modelo. Se utiliza un modelo LSTM de codificador-decodificador que primero convierte la secuencia de entrada a su representación vectorial (codificación) y luego la envía a su versión traducida.
Inconvenientes:
Como se dice, todo en este mundo viene con sus propias ventajas y desventajas, los LSTM también tienen algunos inconvenientes que se analizan a continuación:
- Los LSTM se hicieron populares porque podían resolver el problema de la desaparición de los gradientes. Pero resulta que no logran eliminarlo por completo. El problema radica en el hecho de que los datos todavía tienen que moverse de celda en celda para su evaluación. Además, la celda se ha vuelto bastante compleja ahora con las características adicionales (como las puertas de olvido) que se han incluido en la imagen.
- Requieren muchos recursos y tiempo para capacitarse y estar listos para las aplicaciones del mundo real. En términos técnicos, necesitan un alto ancho de banda de memoria debido a las capas lineales presentes en cada celda que el sistema generalmente no proporciona. Por lo tanto, en cuanto al hardware, los LSTM se vuelven bastante ineficientes.
- Con el auge de la minería de datos, los desarrolladores buscan un modelo que pueda recordar información pasada durante más tiempo que los LSTM. La fuente de inspiración para este tipo de modelo es el hábito humano de dividir una determinada información en partes pequeñas para facilitar su recuerdo.
- Los LSTM se ven afectados por la inicialización de diferentes pesos aleatorios y, por lo tanto, se comportan de manera bastante similar a la de una red neuronal de avance. Prefieren la inicialización de peso pequeño en su lugar.
- Los LSTM son propensos al sobreajuste y es difícil aplicar el algoritmo de abandono para frenar este problema. Dropout es un método de regularización en el que las conexiones recurrentes y de entrada a las unidades LSTM se excluyen probabilísticamente de las actualizaciones de activación y peso mientras se entrena una red.
Publicación traducida automáticamente
Artículo escrito por aditianu1998 y traducido por Barcelona Geeks. The original can be accessed here. Licence: CCBY-SA