Prerrequisito: Modelo BERT
SpanBERT frente a BERT
SpanBERT es una mejora en el modelo BERT que proporciona una mejor predicción de tramos de texto. A diferencia de BERT, aquí realizamos los siguientes pasos i) enmascarar tramos contiguos aleatorios, en lugar de tokens individuales aleatorios.
ii) entrenar el modelo basado en tokens al principio y al final del límite del tramo (conocido como objetivo de límite de tramo ) para predecir los tramos marcados completos.
Se diferencia del modelo BERT en su esquema de enmascaramiento, ya que BERT solía enmascarar aleatoriamente tokens en una secuencia, pero aquí en SpanBERT enmascaramos tramos de texto contiguos aleatorios.
Otra diferencia es la del objetivo de entrenamiento. BERT fue entrenado en dos objetivos (2 funciones de pérdida):
- Modelado de lenguaje enmascarado (MLM) : predicción del token de máscara en la salida
- Predicción de la siguiente secuencia (NSP) — Predecir si 2 secuencias de textos se suceden entre sí.
Pero en SpanBERT , lo único en lo que se entrena el modelo es el objetivo de límite de tramo, que luego contribuye a la función de pérdida.
SpanBERT: Implementación
Para implementar SpanBERT, construimos una réplica del modelo BERT pero le hacemos ciertos cambios para que pueda funcionar mejor que el modelo BERT original. Se observa que el modelo BERT funciona mucho mejor cuando solo se entrena solo con ‘Modelado de lenguaje enmascarado’ en lugar de con ‘Predicción de siguiente secuencia’. Por lo tanto, ignoramos NSP y ajustamos el modelo en la línea de base de secuencia única mientras construimos la réplica del modelo BERT, mejorando así su precisión de predicción.
SpanBERT: Intuición
Figura 1: Entrenamiento SpanBERT
La figura 1 muestra el entrenamiento del modelo SpanBERT. En la oración dada, el lapso de palabras ‘ un campeonato de fútbol ‘ está enmascarado. El objetivo de límite de tramo está definido por x 4 y x 9 resaltados en azul. Esto se usa para predecir cada token en el intervalo enmascarado.
Aquí, en la figura 1, se crea una secuencia de palabras » un torneo de campeonato de fútbol » y toda la secuencia se pasa a través del bloque codificador y obtiene la predicción de los tokens enmascarados como salida. (x 5 a x 8 )
Por ejemplo, si tuviéramos que predecir para la ficha x 6 (es decir, fútbol), a continuación se muestra la pérdida equivalente (como se muestra en la ecuación (1) ) que obtendríamos.
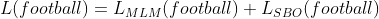
Ecuación-(1)
Esta pérdida es la suma de las pérdidas dadas por las pérdidas de MLM y SBO.
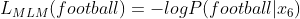
Ecuación-(2)
Ahora, la pérdida de MLM es lo mismo que ‘-ve logaritmo de probabilidad’ o en términos más simples, ¿cuáles son las posibilidades de que x 6 sea fútbol?
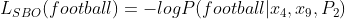
Ecuación-(3)
Then, the SBO loss is depends on three parameters. x4 - the start of the span boundary x6 - the end of the span boundary P2 - the position of x6 (football) from the starting point (x4) So given these three parameters, we see how good the model is at predicting the token 'football'.
Usando las dos funciones de pérdida anteriores, el modelo BERT se ajusta y se llama SpanBERT.
Objetivo de límite de tramo:
Aquí, obtenemos la salida como un vector que codifica los tokens en la secuencia representada como ( x 1 , ….., x n ). El lapso enmascarado de tokens está representado por ( x s , …., x e ), donde x s denota el inicio y x e denota el final del lapso enmascarado de tokens. La función SBO se representa como:
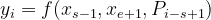
Ecuación-(4)
where P1, P2, ... are relative positions w.r.t the left boundary token xs-1.
La función SBO ‘ f’ es una red feed-forward de 2 capas con activación GeLU . Esta red de 2 capas se representa como:
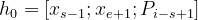
Ecuación-(5)
where, h0 = first hidden representation xs-1 = starting boundary word xe+1 = ending boundary word Pi-s+1 = positional embedding of the word
Pasamos h 0 a la primera capa oculta con peso W 1 .
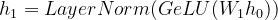
Ecuación-(6)
where, GeLU (Gaussian Error Linear Units) = non-linear activation function h1 = second hidden representation W1 = weight of first hidden layer LayerNorm = a normalization technique used to prevent interactions within the batches
Ahora, pasamos esto a través de otra capa con peso W 2 para obtener la salida y i .
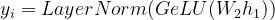
Ecuación-(7)
where, yi = vector representation for all the toxens xi W2 = weight of second hidden layer
Para generalizar, la pérdida equivalente de SpanBERT de un token en particular en un lapso de palabras se calcula mediante:
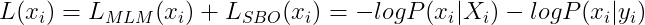
Ecuación-(8)
where, Xi = final representation of tokens xi= original sequence of tokens yi = output obtained by passing xi through 2-layer feed forward network.
Esta fue una intuición y comprensión básicas del modelo SpanBERT y cómo predice un lapso de palabras en lugar del token individual, lo que lo hace más poderoso que el modelo BERT. Para cualquier duda/consulta, comenta abajo.
Publicación traducida automáticamente
Artículo escrito por prakharr0y y traducido por Barcelona Geeks. The original can be accessed here. Licence: CCBY-SA