BERT significa Representación bidireccional para transformadores . Fue propuesto por investigadores de Google Research en 2018. Aunque el objetivo principal era mejorar la comprensión del significado de las consultas relacionadas con la Búsqueda de Google. Un estudio muestra que Google encontró el 15% de las consultas nuevas todos los días. Por lo tanto, requiere que el motor de búsqueda de Google comprenda mucho mejor el idioma para comprender la consulta de búsqueda.
Para mejorar la comprensión del lenguaje del modelo. BERT está capacitado y probado para diferentes tareas en una arquitectura diferente. Algunas de estas tareas con la arquitectura se analizan a continuación.
Modelo de lenguaje enmascarado:
en esta tarea de PNL, reemplazamos el 15 % de las palabras del texto con el token [MASK]. Luego, el modelo predice las palabras originales que se reemplazan por el token [MASK]. Más allá del enmascaramiento, el enmascaramiento también mezcla un poco las cosas para mejorar la forma en que el modelo se ajusta más tarde porque el token [MASK] creó una falta de coincidencia entre el entrenamiento y el ajuste fino. En este modelo, agregamos una capa de clasificación en la parte superior de la entrada del codificador. También calculamos la probabilidad de la salida utilizando una capa totalmente conectada y una capa softmax. Modelo de lenguaje enmascarado: la función de pérdida BERT al calcularla considera solo la predicción de valores enmascarados e ignora la predicción de valores no enmascarados. Esto ayuda a calcular la pérdida solo para ese 15% de palabras enmascaradas. Predicción de la siguiente oración:
En esta tarea de PNL, se nos proporcionan dos oraciones, nuestro objetivo es predecir si la segunda oración es la siguiente oración posterior a la primera oración en el texto original. Durante el entrenamiento del BERT, tomamos el 50 % de los datos que es la siguiente oración subsiguiente (etiquetada como isNext) de la oración original y el 50 % del tiempo tomamos la oración aleatoria que no es la siguiente oración en el texto original (etiquetada como como NotNext). Dado que esta es una tarea de clasificación, el primer token es el token [CLS]. Este modelo también usa un token [SEP] para separar las dos oraciones que pasamos al modelo.
El modelo BERT obtuvo una precisión del 97%-98% en esta tarea. La ventaja de entrenar al modelo con la tarea es que ayuda al modelo a comprender la relación entre oraciones.
Ajuste BERT para diferentes tareas:
- BERT para tareas de clasificación de pares de oraciones:
- MNLI: la inferencia de lenguaje natural multigénero es una tarea de clasificación a gran escala. En esta tarea, hemos dado un par de oraciones. El objetivo es identificar si la segunda oración es vinculación, contradicción o neutral con respecto a la primera oración.
- QQP : pares de preguntas de Quora. En este conjunto de datos, el objetivo es determinar si dos preguntas son semánticamente iguales.
- QNLI : inferencia de lenguaje natural de preguntas. En esta tarea, el modelo debe determinar si la segunda oración es la respuesta a la pregunta formulada en la primera oración.
- SWAG : El conjunto de datos Situaciones con generaciones antagónicas contiene 113.000 clasificaciones de oraciones. La tarea es determinar si la segunda oración es la continuación de la primera o no.
BERT ha perfeccionado su arquitectura para varias tareas de clasificación de pares de oraciones, como:

- Tarea de clasificación de oraciones individuales:
- SST-2: Stanford Sentiment Treebank es una tarea de clasificación de oraciones binarias que consta de oraciones extraídas de reseñas de películas con anotaciones de su sentimiento representado en la oración. BERT generó resultados de última generación en SST-2.
- CoLA: El Corpus de Aceptabilidad Lingüística es la tarea de clasificación binaria. El objetivo de esta tarea es predecir si una oración en inglés proporcionada es lingüísticamente aceptable o no.

- Tarea de pregunta y respuesta: BERT también ha generado tareas de respuesta a preguntas con resultados de última generación, como los conjuntos de datos de preguntas y respuestas de Stanford (SQuAD v1.1 y SQuAD v2.0). En esta tarea de respuesta a preguntas, el modelo toma una pregunta y un pasaje. El objetivo es marcar el intervalo de texto de la respuesta en la pregunta.
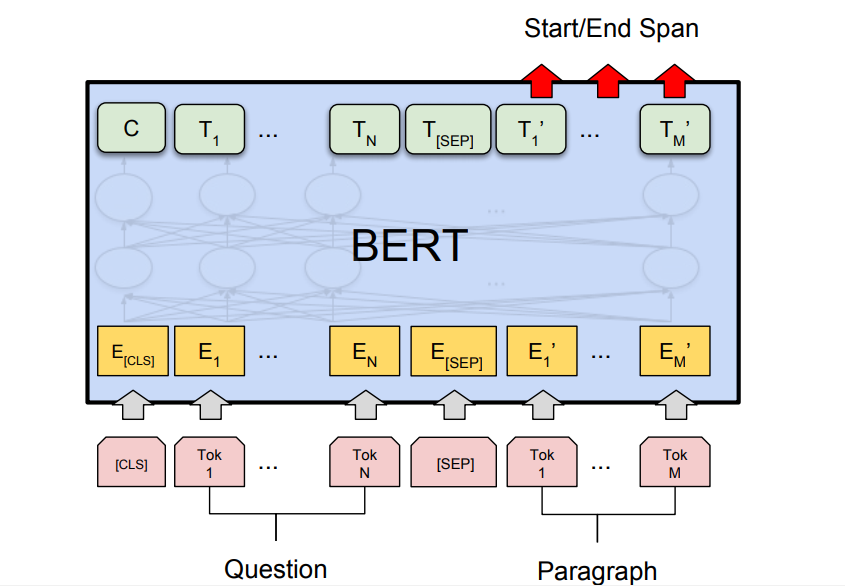
BERT para la búsqueda de Google:
como mencionamos anteriormente, BERT está capacitado y genera resultados de última generación en la tarea de preguntas y respuestas. Este fue el resultado particularmente de los modelos de transformadores que usamos en la arquitectura BERT. Estos modelos toman oraciones completas como entrada en lugar de entrada palabra por palabra. Esto ayuda a generar incrustaciones contextuales completas de una palabra y ayuda a comprender mejor el idioma. Este método es muy útil para comprender la intención real detrás de la consulta de búsqueda para obtener los mejores resultados. Consulta de búsqueda BERT En la imagen de arriba, podemos ver que después de aplicar el modelo BERT, Google entiende mejor la consulta de búsqueda y, por lo tanto, produce un resultado más preciso.
Conclusión:
BERT ha demostrado ser un gran avance en el campo del procesamiento del lenguaje natural y la comprensión del lenguaje similar al que AlexNet ha proporcionado en el campo de la visión artificial. Ha logrado resultados de vanguardia en diferentes tareas, por lo que puede usarse para muchas tareas de PNL. También se usa en la Búsqueda de Google en 70 idiomas desde diciembre de 2019. Referencias: