El reconocimiento de la actividad humana utilizando sensores de teléfonos inteligentes como el acelerómetro es uno de los temas frenéticos de investigación. HAR es uno de los problemas de clasificación de series temporales. En este proyecto se han trabajado varios modelos de aprendizaje automático y aprendizaje profundo para obtener el mejor resultado final. En la misma secuencia, podemos usar el modelo LSTM (memoria a largo plazo) de la Red Neural Recurrente (RNN) para reconocer diversas actividades de los humanos, como pararse, subir y bajar escaleras, etc.
El modelo LSTM es un tipo de red neuronal recurrente capaz de dependencia del orden de aprendizaje en problemas de predicción de secuencias. Este modelo se utiliza porque ayuda a recordar valores en intervalos arbitrarios.
El conjunto de datos de reconocimiento de actividad humana se puede descargar desde el enlace que figura a continuación: Conjunto de datos HAR
Actividades:
- Caminando
- Piso superior
- Abajo
- Sesión
- De pie
Los acelerómetros detectan la magnitud y la dirección de la aceleración adecuada, como una cantidad vectorial, y pueden usarse para detectar la orientación (porque la dirección del peso cambia). GyroScope mantiene la orientación a lo largo de un eje para que la orientación no se vea afectada por la inclinación o rotación del montaje, de acuerdo con la conservación del momento angular.
Comprender el conjunto de datos:
- Ambos sensores generan datos en el espacio 3D a lo largo del tiempo.
(‘XYZ’ representa señales de 3 ejes en las direcciones X, Y y Z). - Los datos disponibles se procesan previamente mediante la aplicación de filtros de ruido y luego se muestrean en ventanas de ancho fijo, es decir, cada ventana tiene 128 lecturas.
Los datos de entrenamiento y prueba se separaron como
datos de entrenamiento. Las lecturas del 80 % de los voluntarios se tomaron como datos de entrenamiento y los registros del 20 % de los voluntarios restantes se tomaron como datos de prueba. Todos los datos están presentes en la carpeta descargada usando el enlace proporcionado arriba.
Etapas
- Elegir un conjunto de datos
- Cargando el conjunto de datos en la unidad para trabajar en Google colaboratory
- Limpieza de conjuntos de datos y preprocesamiento de datos
- Elegir un modelo y construir un modelo de red de aprendizaje profundo
- Exportando en Android Studio.
El IDE utilizado para este proyecto es Google Colaboratory, que es el mejor de los tiempos para hacer frente a proyectos de aprendizaje profundo. La Fase 1 se explicó anteriormente desde donde se descarga el conjunto de datos. En esta secuencia, para comenzar con el proyecto, abra un nuevo cuaderno en Google Colaboratory, primero importe todas las bibliotecas necesarias.
Código: Importación de bibliotecas
Python3
import pandas as pd import numpy as np import pickle import matplotlib.pyplot as plt from scipy import stats import tensorflow as tf import seaborn as sns from sklearn import metrics from sklearn.model_selection import train_test_split %matplotlib inline
Fase 2:
está cargando el conjunto de datos en la computadora portátil, antes de hacerlo, debemos montar la computadora portátil en el disco para que esta computadora portátil se guarde en nuestro disco y se recupere cuando sea necesario.
Python3
sns.set(style="whitegrid", palette="muted", font_scale=1.5)
RANDOM_SEED = 42
from google.colab import drive
drive.mount('/content/drive')
Producción:
You will see a pop up similar to one shown in the screenshot below, open the link and copy the authorization code and paste it in the authorization code bar and enter the drive will be mounted.

Código: Cargar el conjunto de datos
Python3
from google.colab import files uploaded = files.upload()
Ahora, pasando a la fase de construcción y entrenamiento del modelo, necesitamos buscar diferentes modelos que puedan ayudar a construir un modelo de mejor precisión. Aquí, se elige el modelo LSTM de Recurrent Neural Network. La imagen que se muestra a continuación muestra cómo se ven los datos.
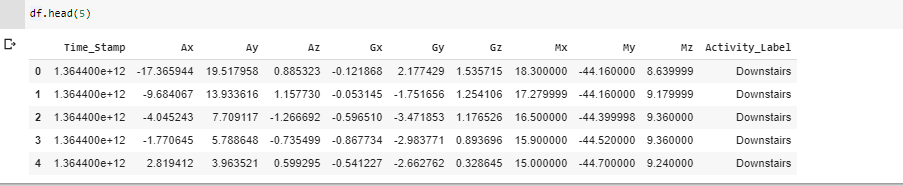
Fase 3:
Comienza con el preprocesamiento de datos. Es la fase en la que ~90 % del tiempo se consume en proyectos reales de ciencia de datos. Aquí, los datos sin procesar se toman y se convierten en algunos formatos útiles y eficientes.
Código: la transformación de datos se realiza para normalizar los datos
Python3
#transforming shape reshaped_segments = np.asarray( segments, dtype = np.float32).reshape( -1 , N_time_steps, N_features) reshaped_segments.shape
Código: dividir el conjunto de datos
Python3
X_train, X_test, Y_train, Y_test = train_test_split( reshaped_segments, labels, test_size = 0.2, random_state = RANDOM_SEED)
El tamaño de la prueba se toma como el 20 %, es decir, del total de registros, el 20 % de los registros se usa para la precisión de la prueba, mientras que el resto se usa para el modelo de entrenamiento.
Número de clases = 6 (Andar, Sentarse, De pie, Correr, Subir y Bajar)
Fase 4: En esta fase el modelo elegido es el modelo LSTM de RNN.
Código: Construcción de modelos
Python3
def create_LSTM_model(inputs):
W = {
'hidden': tf.Variable(tf.random_normal([N_features, N_hidden_units])),
'output': tf.Variable(tf.random_normal([N_hidden_units, N_classes]))
}
biases = {
'hidden': tf.Variable(tf.random_normal([N_hidden_units], mean = 0.1)),
'output': tf.Variable(tf.random_normal([N_classes]))
}
X = tf.transpose(inputs, [1, 0, 2])
X = tf.reshape(X, [-1, N_features])
hidden = tf.nn.relu(tf.matmul(X, W['hidden']) + biases['hidden'])
hidden = tf.split(hidden, N_time_steps, 0)
lstm_layers = [tf.contrib.rnn.BasicLSTMCell(
N_hidden_units, forget_bias = 1.0) for _ in range(2)]
lstm_layers = tf.contrib.rnn.MultiRNNCell(lstm_layers)
outputs, _ = tf.contrib.rnn.static_rnn(lstm_layers,
hidden, dtype = tf.float32)
lstm_last_output = outputs[-1]
return tf.matmul(lstm_last_output, W['output']) + biases['output']
Código: realizar la optimización con AdamOptimizer para modificar los valores de pérdida y escribir las variables para mejorar la precisión y reducir la pérdida.
Python3
L2_LOSS = 0.0015 l2 = L2_LOSS * \ sum(tf.nn.l2_loss(tf_var) for tf_var in tf.trainable_variables()) loss = tf.reduce_mean(tf.nn.softmax_cross_entropy_with_logits( logits = pred_y, labels = Y)) + l2 Learning_rate = 0.0025 optimizer = tf.train.AdamOptimizer(learning_rate = Learning_rate).minimize(loss) correct_pred = tf.equal(tf.argmax(pred_softmax , 1), tf.argmax(Y,1)) accuracy = tf.reduce_mean(tf.cast(correct_pred, dtype = tf.float32))
Código: Realización de 50 iteraciones de entrenamiento del modelo para obtener la mayor precisión y reducir las pérdidas
Python3
# epochs is number of iterations performed in model training.
N_epochs = 50
batch_size = 1024
saver = tf.train.Saver()
history = dict(train_loss=[], train_acc=[], test_loss=[], test_acc=[])
sess = tf.InteractiveSession()
sess.run(tf.global_variables_initializer())
train_count = len(X_train)
for i in range(1, N_epochs + 1):
for start, end in zip(range(0, train_count, batch_size),
range(batch_size, train_count + 1, batch_size)):
sess.run(optimizer, feed_dict={X: X_train[start:end],
Y: Y_train[start:end]})
_, acc_train, loss_train = sess.run([pred_softmax, accuracy, loss], feed_dict={
X: X_train, Y: Y_train})
_, acc_test, loss_test = sess.run([pred_softmax, accuracy, loss], feed_dict={
X: X_test, Y: Y_test})
history['train_loss'].append(loss_train)
history['train_acc'].append(acc_train)
history['test_loss'].append(loss_test)
history['test_acc'].append(acc_test)
if (i != 1 and i % 10 != 0):
print(f'epoch: {i} test_accuracy:{acc_test} loss:{loss_test}')
predictions, acc_final, loss_final = sess.run([pred_softmax, accuracy, loss],
feed_dict={X: X_test, Y: Y_test})
print()
print(f'final results : accuracy : {acc_final} loss : {loss_final}')
Producción:

Entonces, con este enfoque, la precisión alcanza casi ~1 en la iteración 50. Esto indica que la mayoría de las etiquetas se identifican claramente con este enfoque. Para obtener el recuento exacto de actividades correctamente identificadas, se crea una array de confusión.
Código: gráfico de precisión
Python3
plt.figure(figsize=(12,8))
plt.plot(np.array(history['train_loss']), "r--", label="Train loss")
plt.plot(np.array(history['train_acc']), "g--", label="Train accuracy")
plt.plot(np.array(history['test_loss']), "r--", label="Test loss")
plt.plot(np.array(history['test_acc']), "g--", label="Test accuracy")
plt.title("Training session's progress over iteration")
plt.legend(loc = 'upper right', shadow = True)
plt.ylabel('Training Progress(Loss or Accuracy values)')
plt.xlabel('Training Epoch')
plt.ylim(0)
plt.show()
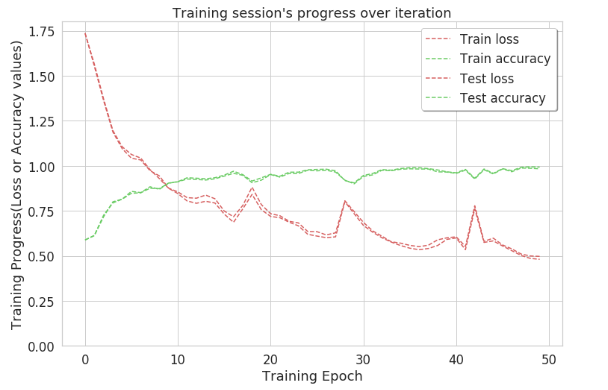
Array de confusión: una array de confusión no es menos que una array 2D, a diferencia de lo que ayuda a calcular el recuento exacto de actividades identificadas correctamente. En otras palabras, describe el rendimiento del modelo de clasificación en el conjunto de datos de prueba.
Código: Array de confusión
Python3
max_test = np.argmax(Y_test, axis=1)
max_predictions = np.argmax(predictions, axis = 1)
confusion_matrix = metrics.confusion_matrix(max_test, max_predictions)
plt.figure(figsize=(16,14))
sns.heatmap(confusion_matrix, xticklabels = LABELS, yticklabels = LABELS, annot =True, fmt = "d")
plt.title("Confusion Matrix")
plt.xlabel('Predicted_label')
plt.ylabel('True Label')
plt.show()
Esta es la descripción completa del proyecto hasta el momento. Se puede construir usando otros modelos como CNN o modelos de aprendizaje automático como KNN.
Publicación traducida automáticamente
Artículo escrito por TanviAgarwal y traducido por Barcelona Geeks. The original can be accessed here. Licence: CCBY-SA