Uno de los problemas críticos al entrenar una red neuronal en los datos de muestra es el sobreajuste . Cuando la cantidad de épocas utilizadas para entrenar un modelo de red neuronal es más de la necesaria, el modelo de entrenamiento aprende patrones que son específicos de los datos de muestra en gran medida. Esto hace que el modelo no pueda funcionar bien en un nuevo conjunto de datos. Este modelo brinda una alta precisión en el conjunto de entrenamiento (datos de muestra) pero no logra una buena precisión en el conjunto de prueba. En otras palabras, el modelo pierde capacidad de generalización al sobreajustarse a los datos de entrenamiento.
Para mitigar el sobreajuste y aumentar la capacidad de generalización de la red neuronal, el modelo debe entrenarse para un número óptimo de épocas. Una parte de los datos de entrenamiento se dedica a la validación del modelo, para comprobar el rendimiento del modelo después de cada época de entrenamiento. La pérdida y la precisión en el conjunto de entrenamiento, así como en el conjunto de validación, se monitorean para revisar el número de época después del cual el modelo comienza a sobreajustarse.
keras.callbacks.callbacks.EarlyStopping()
Cualquiera de los valores de pérdida/precisión pueden ser monitoreados por la función de devolución de llamada de detención temprana. Si se está monitoreando la pérdida, el entrenamiento se detiene cuando se observa un incremento en los valores de pérdida. O, si se está monitoreando la precisión, el entrenamiento se detiene cuando se observa una disminución en los valores de precisión.
Sintaxis con valores predeterminados:
keras.callbacks.callbacks.EarlyStopping(monitor=’val_loss’, min_delta=0,patient=0, verbose=0, mode=’auto’,lineal=Ninguno, restore_best_weights=False)
Entendiendo algunos argumentos importantes:
- monitor: Se debe asignar el valor a monitorear por la función. Puede ser pérdida de validación o precisión de validación.
- modo: Es el modo en que se debe observar el cambio en la cantidad monitoreada. Esto puede ser ‘min’ o ‘max’ o ‘auto’. Cuando el valor monitoreado es pérdida, su valor es ‘min’. Cuando el valor monitoreado es precisión, su valor es ‘max’. Cuando el modo está configurado en ‘automático’, la función monitorea automáticamente con el modo adecuado.
- min_delta: se debe establecer el valor mínimo para que se considere el cambio, es decir, el cambio en el valor que se está monitoreando debe ser mayor que el valor ‘min_delta’.
- Paciencia: Paciencia es el número de épocas para continuar el entrenamiento después de la primera parada. El modelo espera con paciencia número de épocas para cualquier mejora en el modelo.
- verbose: Verbose es un valor entero-0, 1 o 2. Este valor es para seleccionar la forma en que se muestra el progreso durante el entrenamiento.
- Verbose = 0: modo silencioso: no se muestra nada en este modo.
- Verbose = 1: se muestra una barra que muestra el progreso del entrenamiento.
- Verbose = 2: en este modo, se muestra una línea por época, que muestra el progreso del entrenamiento por época.
- restore_best_weights: este es un valor booleano. El valor verdadero restaura los pesos que son óptimos.
Encontrar el número óptimo de épocas para evitar el sobreajuste en el conjunto de datos MNIST.
Paso 1: carga del conjunto de datos y preprocesamiento
import keras
from keras.utils.np_utils import to_categorical
from keras.datasets import mnist
# Loading data
(train_images, train_labels), (test_images, test_labels)= mnist.load_data()
# Reshaping data-Adding number of channels as 1 (Grayscale images)
train_images = train_images.reshape((train_images.shape[0],
train_images.shape[1],
train_images.shape[2], 1))
test_images = test_images.reshape((test_images.shape[0],
test_images.shape[1],
test_images.shape[2], 1))
# Scaling down pixel values
train_images = train_images.astype('float32')/255
test_images = test_images.astype('float32')/255
# Encoding labels to a binary class matrix
y_train = to_categorical(train_labels)
y_test = to_categorical(test_labels)
Paso 2: construir un modelo de CNN
from keras import models from keras import layers model = models.Sequential() model.add(layers.Conv2D(32, (3, 3), activation ="relu", input_shape =(28, 28, 1))) model.add(layers.MaxPooling2D(2, 2)) model.add(layers.Conv2D(64, (3, 3), activation ="relu")) model.add(layers.MaxPooling2D(2, 2)) model.add(layers.Flatten()) model.add(layers.Dense(64, activation ="relu")) model.add(layers.Dense(10, activation ="softmax")) model.summary()
Salida: Resumen del modelo

Paso 4: Compilación del modelo con el optimizador RMSprop, la función de pérdida de entropía cruzada categórica y la precisión como métrica de éxito
model.compile(optimizer ="rmsprop", loss ="categorical_crossentropy", metrics =['accuracy'])
Paso 5: crear un conjunto de validación y un conjunto de entrenamiento mediante la partición del conjunto de entrenamiento actual
val_images = train_images[:10000] partial_images = train_images[10000:] val_labels = y_train[:10000] partial_labels = y_train[10000:]
Paso 6: inicialización de devolución de llamada de detención anticipada y entrenamiento del modelo
from keras import callbacks earlystopping = callbacks.EarlyStopping(monitor ="val_loss", mode ="min", patience = 5, restore_best_weights = True) history = model.fit(partial_images, partial_labels, batch_size = 128, epochs = 25, validation_data =(val_images, val_labels), callbacks =[earlystopping])
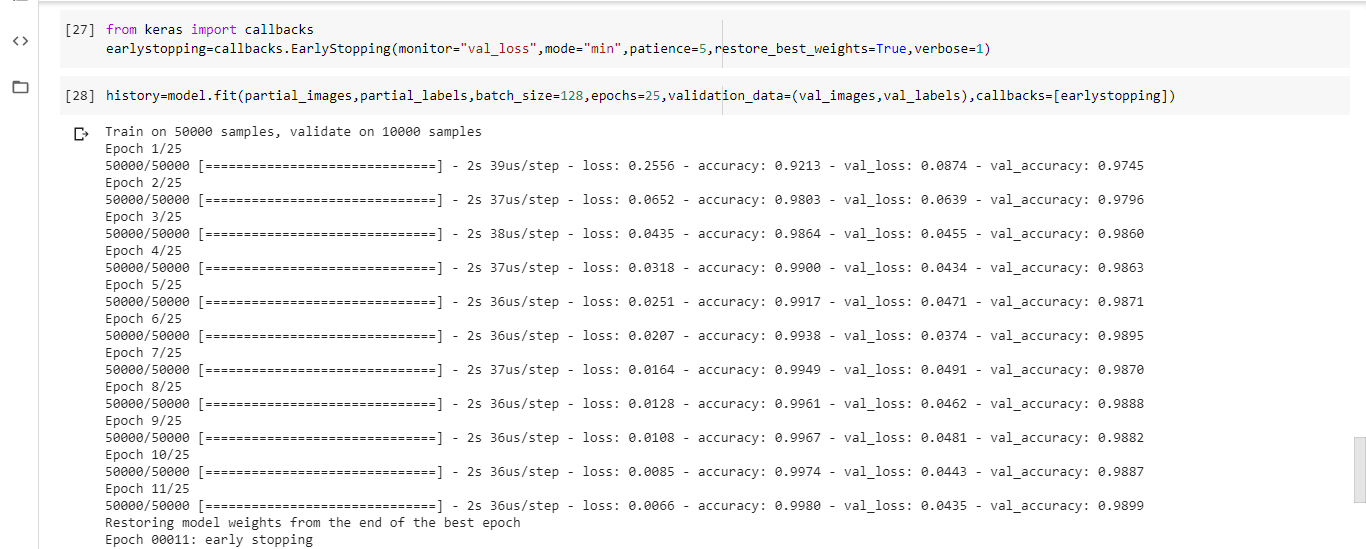
El entrenamiento se detuvo en la época 11, es decir, el modelo comenzará a sobreajustarse a partir de la época 12. Por lo tanto, la cantidad óptima de épocas para entrenar la mayoría de los conjuntos de datos es 11.
Observación de los valores de pérdida sin utilizar la función de devolución de llamada de parada anticipada:
entrene el modelo hasta 25 épocas y trace los valores de pérdida de entrenamiento y los valores de pérdida de validación contra el número de épocas. La trama se parece a:
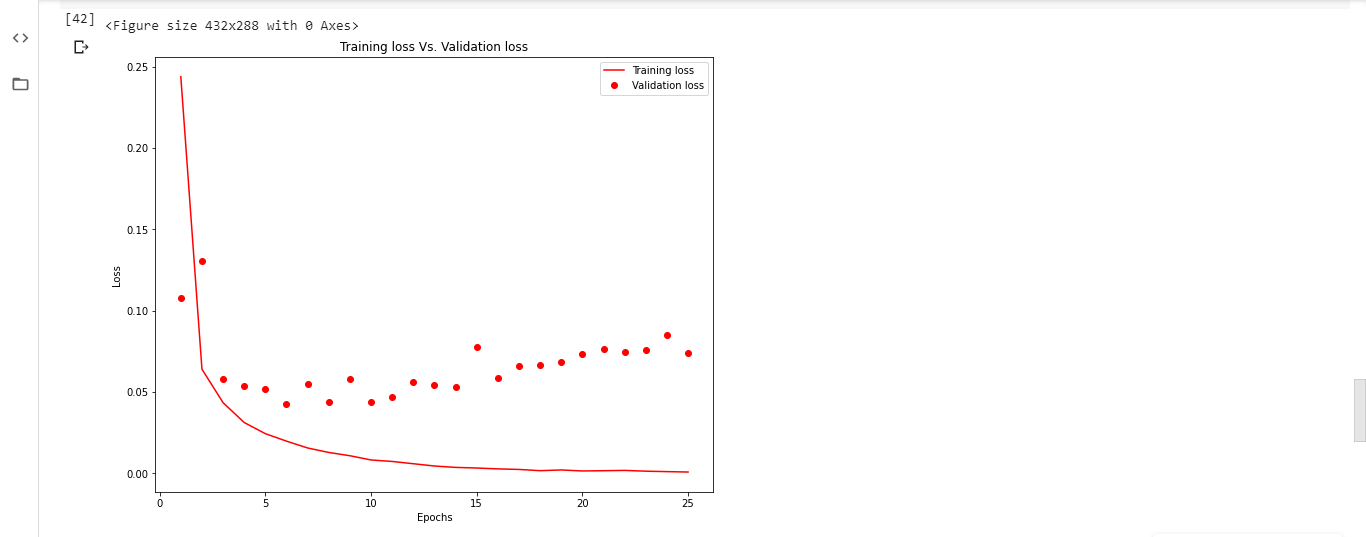
Inferencia:
a medida que el número de épocas aumenta más allá de 11, la pérdida del conjunto de entrenamiento disminuye y se vuelve casi cero. Mientras que la pérdida de validación aumenta, lo que representa el sobreajuste del modelo en los datos de entrenamiento.
Referencias:
- https://keras.io/callbacks/
- https://keras.io/datasets/