Introducción:
Introducidas en la década de 1980 por Yann LeCun, las redes neuronales de convolución (también llamadas CNN o ConvNet) han recorrido un largo camino. Las arquitecturas basadas en CNN, que se emplean para tareas simples de clasificación de dígitos, se están utilizando de manera muy profunda en muchas tareas relacionadas con el aprendizaje profundo y la visión artificial, como la detección de objetos, la segmentación de imágenes, el seguimiento de la mirada, entre otras. Usando el marco PyTorch, este artículo implementará un clasificador de imágenes basado en CNN en el popular conjunto de datos CIFAR-10.
Antes de continuar con el código y la instalación, se espera que el lector comprenda cómo funcionan teóricamente las CNN y con varias operaciones relacionadas como convolución, agrupación, etc. El artículo también asume una familiaridad básica con el flujo de trabajo de PyTorch y sus diversas utilidades, como Dataloaders, Conjuntos de datos, transformaciones de tensor y operaciones CUDA. Para un repaso rápido de estos conceptos, se anima al lector a leer los siguientes artículos:
- Introducción a la red neuronal convolucional
- Entrenamiento de Redes Neuronales con Validación usando PyTorch
- ¿Cómo configurar y ejecutar operaciones CUDA en Pytorch?
Instalación
Para la implementación de la CNN y la descarga del conjunto de datos CIFAR-10, necesitaremos los módulos torch y torchvision . Aparte de eso, usaremos numpy y matplotlib para el análisis y trazado de datos. Las bibliotecas requeridas se pueden instalar usando el administrador de paquetes pip a través del siguiente comando:
pip instalar antorcha torchvision torchaudio numpy matplotlib
Implementación paso a paso
Paso 1: descarga de datos e impresión de algunas imágenes de muestra del conjunto de entrenamiento.
- Antes de comenzar nuestro viaje para implementar CNN, primero debemos descargar el conjunto de datos en nuestra máquina local, sobre la cual entrenaremos nuestro modelo. Usaremos la utilidad torchvision para este propósito y descargaremos el conjunto de datos CIFAR-10 en conjuntos de entrenamiento y prueba en los directorios “./CIFAR10/train” y “./CIFAR10/test ” , respectivamente. También aplicamos una transformación normalizada donde el procedimiento se realiza sobre los tres canales para todas las imágenes.
- Ahora, tenemos un conjunto de datos de entrenamiento y un conjunto de datos de prueba con 50000 y 10000 imágenes, respectivamente, de una dimensión de 32x32x3. Después de eso, convertimos estos conjuntos de datos en cargadores de datos de un tamaño de lote de 128 para una mejor generalización y un proceso de entrenamiento más rápido.
- Finalmente, trazamos algunas imágenes de muestra del primer lote de entrenamiento para tener una idea de las imágenes con las que estamos trabajando usando la utilidad make_grid de torchvision .
Código:
Python3
import torch
import torchvision
import matplotlib.pyplot as plt
import numpy as np
# The below two lines are optional and are just there to avoid any SSL
# related errors while downloading the CIFAR-10 dataset
import ssl
ssl._create_default_https_context = ssl._create_unverified_context
#Defining plotting settings
plt.rcParams['figure.figsize'] = 14, 6
#Initializing normalizing transform for the dataset
normalize_transform = torchvision.transforms.Compose([
torchvision.transforms.ToTensor(),
torchvision.transforms.Normalize(mean = (0.5, 0.5, 0.5),
std = (0.5, 0.5, 0.5))])
#Downloading the CIFAR10 dataset into train and test sets
train_dataset = torchvision.datasets.CIFAR10(
root="./CIFAR10/train", train=True,
transform=normalize_transform,
download=True)
test_dataset = torchvision.datasets.CIFAR10(
root="./CIFAR10/test", train=False,
transform=normalize_transform,
download=True)
#Generating data loaders from the corresponding datasets
batch_size = 128
train_loader = torch.utils.data.DataLoader(train_dataset, batch_size=batch_size)
test_loader = torch.utils.data.DataLoader(test_dataset, batch_size=batch_size)
#Plotting 25 images from the 1st batch
dataiter = iter(train_loader)
images, labels = dataiter.next()
plt.imshow(np.transpose(torchvision.utils.make_grid(
images[:25], normalize=True, padding=1, nrow=5).numpy(), (1, 2, 0)))
plt.axis('off')
Producción:

Figura 1: Algunas imágenes de muestra del conjunto de datos de entrenamiento
Paso 2: Trazar la distribución de clases del conjunto de datos
Por lo general, es una buena idea trazar la distribución de clases del conjunto de entrenamiento. Esto ayuda a comprobar si el conjunto de datos proporcionado está equilibrado o no. Para hacer esto, iteramos sobre todo el conjunto de entrenamiento en lotes y recopilamos las clases respectivas de cada instancia. Finalmente, calculamos los conteos de las clases únicas y las graficamos.
Código:
Python3
#Iterating over the training dataset and storing the target class for each sample
classes = []
for batch_idx, data in enumerate(train_loader, 0):
x, y = data
classes.extend(y.tolist())
#Calculating the unique classes and the respective counts and plotting them
unique, counts = np.unique(classes, return_counts=True)
names = list(test_dataset.class_to_idx.keys())
plt.bar(names, counts)
plt.xlabel("Target Classes")
plt.ylabel("Number of training instances")
Producción:
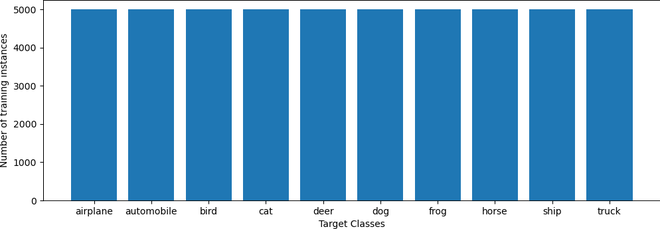
Figura 2: Distribución de clases del conjunto de entrenamiento
Como se muestra en la Figura 2, cada una de las diez clases tiene casi la misma cantidad de muestras de entrenamiento. Por lo tanto, no necesitamos tomar medidas adicionales para reequilibrar el conjunto de datos.
Paso 3: Implementación de la arquitectura CNN
Por el lado de la arquitectura, usaremos un modelo simple que emplea tres capas de convolución con profundidades 32, 64 y 64, respectivamente, seguidas de dos capas completamente conectadas para realizar la clasificación.
- Cada capa convolucional involucra una operación convolucional que involucra un filtro de convolución de 3×3 y es seguida por una operación de activación de ReLU para introducir no linealidad en el sistema y una operación de agrupación máxima con un filtro de 2×2 para reducir la dimensionalidad del mapa de características.
- Después del final de los bloques convolucionales, aplanamos la capa multidimensional en una estructura de baja dimensión para comenzar con nuestros bloques de clasificación. Después de la primera capa lineal, la última capa de salida (también una capa lineal) tiene diez neuronas para cada una de las diez clases únicas de nuestro conjunto de datos.
La arquitectura es la siguiente:

Figura 3: Arquitectura de la CNN
Para construir nuestro modelo, crearemos una clase CNN heredada de la clase torch.nn.Module para aprovechar las utilidades de Pytorch. Aparte de eso, usaremos el contenedor torch.nn.Sequential para combinar nuestras capas una tras otra.
- Las capas Conv2D(), ReLU() y MaxPool2D() realizan las operaciones de convolución, activación y agrupación. Usamos un relleno de 1 para dar suficiente espacio de aprendizaje al núcleo, ya que el relleno le da a la imagen más área de cobertura, especialmente los píxeles en el marco exterior.
- Después de los bloques convolucionales, las capas completamente conectadas Linear() realizan la clasificación.
Código:
Python3
class CNN(torch.nn.Module): def __init__(self): super().__init__() self.model = torch.nn.Sequential( #Input = 3 x 32 x 32, Output = 32 x 32 x 32 torch.nn.Conv2d(in_channels = 3, out_channels = 32, kernel_size = 3, padding = 1), torch.nn.ReLU(), #Input = 32 x 32 x 32, Output = 32 x 16 x 16 torch.nn.MaxPool2d(kernel_size=2), #Input = 32 x 16 x 16, Output = 64 x 16 x 16 torch.nn.Conv2d(in_channels = 32, out_channels = 64, kernel_size = 3, padding = 1), torch.nn.ReLU(), #Input = 64 x 16 x 16, Output = 64 x 8 x 8 torch.nn.MaxPool2d(kernel_size=2), #Input = 64 x 8 x 8, Output = 64 x 8 x 8 torch.nn.Conv2d(in_channels = 64, out_channels = 64, kernel_size = 3, padding = 1), torch.nn.ReLU(), #Input = 64 x 8 x 8, Output = 64 x 4 x 4 torch.nn.MaxPool2d(kernel_size=2), torch.nn.Flatten(), torch.nn.Linear(64*4*4, 512), torch.nn.ReLU(), torch.nn.Linear(512, 10) ) def forward(self, x): return self.model(x)
Paso 4: Definición de los parámetros de entrenamiento y comienzo del proceso de entrenamiento
Comenzamos el proceso de entrenamiento seleccionando el dispositivo para entrenar nuestro modelo, es decir, CPU o GPU. Luego, definimos los hiperparámetros de nuestro modelo, que son los siguientes:
- Entrenamos nuestros modelos durante 50 épocas , y dado que tenemos un problema multiclase, usamos la pérdida de entropía cruzada como nuestra función objetivo .
- Usamos el popular optimizador Adam con una tasa de aprendizaje de 0.001 y un peso_decaimiento de 0.01 para evitar el sobreajuste a través de la regularización para optimizar la función objetivo.
Finalmente, comenzamos nuestro ciclo de entrenamiento, que consiste en calcular los resultados de cada lote y la pérdida comparando las etiquetas pronosticadas con las etiquetas verdaderas. Al final, trazamos la pérdida de entrenamiento para cada época respectiva para asegurarnos de que el proceso de entrenamiento transcurriera según el plan.
Código:
Python3
#Selecting the appropriate training device
device = 'cuda' if torch.cuda.is_available() else 'cpu'
model = CNN().to(device)
#Defining the model hyper parameters
num_epochs = 50
learning_rate = 0.001
weight_decay = 0.01
criterion = torch.nn.CrossEntropyLoss()
optimizer = torch.optim.Adam(model.parameters(), lr=learning_rate, weight_decay=weight_decay)
#Training process begins
train_loss_list = []
for epoch in range(num_epochs):
print(f'Epoch {epoch+1}/{num_epochs}:', end = ' ')
train_loss = 0
#Iterating over the training dataset in batches
model.train()
for i, (images, labels) in enumerate(train_loader):
#Extracting images and target labels for the batch being iterated
images = images.to(device)
labels = labels.to(device)
#Calculating the model output and the cross entropy loss
outputs = model(images)
loss = criterion(outputs, labels)
#Updating weights according to calculated loss
optimizer.zero_grad()
loss.backward()
optimizer.step()
train_loss += loss.item()
#Printing loss for each epoch
train_loss_list.append(train_loss/len(train_loader))
print(f"Training loss = {train_loss_list[-1]}")
#Plotting loss for all epochs
plt.plot(range(1,num_epochs+1), train_loss_list)
plt.xlabel("Number of epochs")
plt.ylabel("Training loss")
Producción:
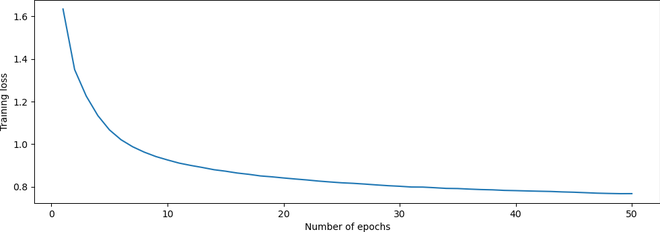
Figura 4: Gráfico de pérdida de entrenamiento frente a número de épocas
En la Figura 4, podemos ver que la pérdida disminuye a medida que aumentan las épocas, lo que indica un procedimiento de entrenamiento exitoso.
Paso 5: Cálculo de la precisión del modelo en el conjunto de prueba
Ahora que nuestro modelo está entrenado, debemos verificar su rendimiento en el conjunto de prueba. Para hacer eso, iteramos sobre todo el conjunto de pruebas en lotes y calculamos el puntaje de precisión comparando las etiquetas verdaderas y predichas para cada lote.
Código:
Python3
test_acc=0
model.eval()
with torch.no_grad():
#Iterating over the training dataset in batches
for i, (images, labels) in enumerate(test_loader):
images = images.to(device)
y_true = labels.to(device)
#Calculating outputs for the batch being iterated
outputs = model(images)
#Calculated prediction labels from models
_, y_pred = torch.max(outputs.data, 1)
#Comparing predicted and true labels
test_acc += (y_pred == y_true).sum().item()
print(f"Test set accuracy = {100 * test_acc / len(test_dataset)} %")
Producción:

Figura 5: Precisión en el equipo de prueba
Paso 6: Generación de predicciones para imágenes de muestra en el conjunto de prueba
Como se muestra en la Figura 5, nuestro modelo ha logrado una precisión de casi el 72 %. Para validar su rendimiento, podemos generar algunas predicciones para algunas imágenes de muestra. Para hacer eso, tomamos las primeras cinco imágenes del último lote del conjunto de prueba y las trazamos usando la utilidad make_grid de torchvision . Luego recopilamos sus verdaderas etiquetas y predicciones del modelo y las mostramos en el título de la trama.
Código:
Python3
#Generating predictions for 'num_images' amount of images from the last batch of test set
num_images = 5
y_true_name = [names[y_true[idx]] for idx in range(num_images)]
y_pred_name = [names[y_pred[idx]] for idx in range(num_images)]
#Generating the title for the plot
title = f"Actual labels: {y_true_name}, Predicted labels: {y_pred_name}"
#Finally plotting the images with their actual and predicted labels in the title
plt.imshow(np.transpose(torchvision.utils.make_grid(images[:num_images].cpu(), normalize=True, padding=1).numpy(), (1, 2, 0)))
plt.title(title)
plt.axis("off")
Producción:

Figura 6: Etiquetas reales frente a previstas para 5 imágenes de muestra del conjunto de prueba. Tenga en cuenta que las etiquetas están en el mismo orden que las imágenes respectivas, de izquierda a derecha.
Como se puede ver en la Figura 6, el modelo produce predicciones correctas para todas las imágenes, excepto la segunda, ¡ya que clasifica erróneamente al perro como un gato!
Conclusión:
Este artículo cubrió la implementación PyTorch de una CNN simple en el popular conjunto de datos CIFAR-10. Se anima al lector a jugar con la arquitectura de la red y los hiperparámetros del modelo para aumentar aún más la precisión del modelo.
Referencias
- https://cs231n.github.io/redes-convolucionales/
- https://pytorch.org/docs/stable/index.html
- https://pytorch.org/tutorials/beginner/blitz/cifar10_tutorial.html
Publicación traducida automáticamente
Artículo escrito por adityasaini70 y traducido por Barcelona Geeks. The original can be accessed here. Licence: CCBY-SA