Desde la disponibilidad de cantidades asombrosas de datos en Internet, los investigadores y científicos de la industria y la academia continúan tratando de desarrollar modos de transferencia de datos más eficientes y confiables que los métodos actuales de vanguardia. Los autocodificadores son uno de los elementos clave encontrados en los últimos tiempos utilizados para tal tarea con su arquitectura simple e intuitiva.
En términos generales, una vez que se entrena un codificador automático, los pesos del codificador se pueden enviar al lado del transmisor y los pesos del decodificador al lado del receptor. De esta manera, el lado del transmisor puede enviar datos en un formato codificado (ahorrándoles así tiempo y dinero) mientras que el lado del receptor puede recibir los datos con mucha menos revisión. Este artículo explorará una aplicación interesante de autoencoder, que se puede usar para la reconstrucción de imágenes en el famoso conjunto de datos de dígitos MNIST usando el marco Pytorch en Python.
Codificadores automáticos
Como se muestra en la siguiente figura, un codificador automático muy básico consta de dos partes principales:
- Un codificador y,
- un decodificador
A través de una serie de capas, el codificador toma la entrada y lleva los datos de mayor dimensión a la representación latente de menor dimensión de los mismos valores. El decodificador toma esta representación latente y genera los datos reconstruidos.
Para una comprensión más profunda de la teoría, se anima al lector a leer el siguiente artículo: ML | Codificadores automáticos
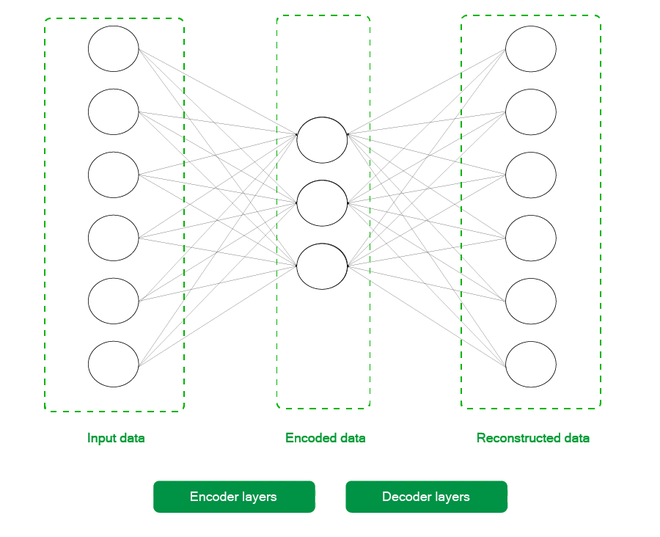
Un Autoencoder básico de 2 capas
Instalación:
Aparte de las bibliotecas habituales como Numpy y Matplotlib , solo necesitamos las bibliotecas torch y torchvision de la string de herramientas de Pytorch para este artículo. Puede usar el siguiente comando para obtener todas estas bibliotecas.
pip3 instalar antorcha torchvision torchaudio numpy matplotlib
Ahora vamos a la parte más interesante, el código. El artículo asume una familiaridad básica con el flujo de trabajo de PyTorch y sus diversas utilidades, como cargadores de datos, conjuntos de datos y transformaciones de tensor. Para un repaso rápido de estos conceptos, se anima al lector a leer los siguientes artículos:
El código se divide en 5 pasos diferentes para un mejor flujo del material y debe ejecutarse secuencialmente para un trabajo adecuado. Cada paso también tiene algunos puntos al comienzo, lo que puede ayudar al lector a comprender mejor el código de ese paso.
Implementación paso a paso:
Paso 1: carga de datos e impresión de algunas imágenes de muestra del conjunto de entrenamiento.
- Inicializando la transformación: en primer lugar, inicializamos la transformación que se aplicaría a cada entrada en el conjunto de datos obtenido. Dado que los tensores son internos al funcionamiento de Pytorch, primero convertimos cada elemento en un tensor y los normalizamos para limitar los valores de píxel entre 0 y 1. Esto se hace para que el proceso de optimización sea más fácil y rápido.
- Descarga del conjunto de datos: Luego, descargamos el conjunto de datos usando la utilidad torchvision.datasets y lo almacenamos en nuestra máquina local en la carpeta ./MNIST/train y ./MNIST/test para los conjuntos de entrenamiento y prueba. También convertimos estos conjuntos de datos en cargadores de datos con tamaños de lote iguales a 256 para un aprendizaje más rápido. Se anima al lector a jugar con estos valores y esperar resultados consistentes.
- Trazado del conjunto de datos: por último, imprimimos aleatoriamente 25 imágenes del conjunto de datos para ver mejor los datos con los que estamos tratando.
Código:
Python
# Importing the necessary libraries
import numpy as np
import matplotlib.pyplot as plt
import torchvision
import torch
plt.rcParams['figure.figsize'] = 15, 10
# Initializing the transform for the dataset
transform = torchvision.transforms.Compose([
torchvision.transforms.ToTensor(),
torchvision.transforms.Normalize((0.5), (0.5))
])
# Downloading the MNIST dataset
train_dataset = torchvision.datasets.MNIST(
root="./MNIST/train", train=True,
transform=torchvision.transforms.ToTensor(),
download=True)
test_dataset = torchvision.datasets.MNIST(
root="./MNIST/test", train=False,
transform=torchvision.transforms.ToTensor(),
download=True)
# Creating Dataloaders from the
# training and testing dataset
train_loader = torch.utils.data.DataLoader(
train_dataset, batch_size=256)
test_loader = torch.utils.data.DataLoader(
test_dataset, batch_size=256)
# Printing 25 random images from the training dataset
random_samples = np.random.randint(
1, len(train_dataset), (25))
for idx in range(random_samples.shape[0]):
plt.subplot(5, 5, idx + 1)
plt.imshow(train_dataset[idx][0][0].numpy(), cmap='gray')
plt.title(train_dataset[idx][1])
plt.axis('off')
plt.tight_layout()
plt.show()
Producción:

Muestras aleatorias del conjunto de entrenamiento
Paso 2: inicialización del modelo Deep Autoencoder y otros hiperparámetros
En este paso, inicializamos nuestra clase DeepAutoencoder , una clase secundaria de torch.nn.Module . Esto abstrae una gran cantidad de código repetitivo para nosotros, y ahora podemos centrarnos en construir nuestra arquitectura modelo , que es la siguiente:
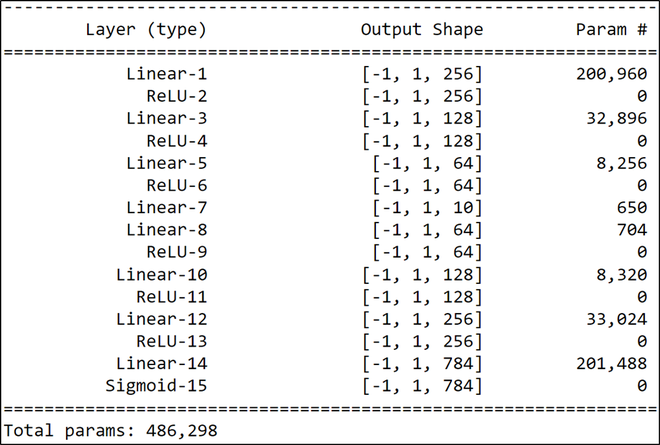
Arquitectura modelo
Como se describió anteriormente, las capas del codificador forman la primera mitad de la red, es decir, de Linear-1 a Linear-7 , y el decodificador forma la otra mitad de Linear-10 a Sigmoid-15. Hemos utilizado la utilidad torch.nn.Sequential para separar el codificador y el decodificador. Esto se hizo para dar una mejor comprensión de la arquitectura del modelo. Después de eso, inicializamos algunos hiperparámetros del modelo, de modo que el entrenamiento se realiza durante 100 épocas utilizando la pérdida de error cuadrático medio y el optimizador de Adam para el proceso de aprendizaje.
Python
# Creating a DeepAutoencoder class class DeepAutoencoder(torch.nn.Module): def __init__(self): super().__init__() self.encoder = torch.nn.Sequential( torch.nn.Linear(28 * 28, 256), torch.nn.ReLU(), torch.nn.Linear(256, 128), torch.nn.ReLU(), torch.nn.Linear(128, 64), torch.nn.ReLU(), torch.nn.Linear(64, 10) ) self.decoder = torch.nn.Sequential( torch.nn.Linear(10, 64), torch.nn.ReLU(), torch.nn.Linear(64, 128), torch.nn.ReLU(), torch.nn.Linear(128, 256), torch.nn.ReLU(), torch.nn.Linear(256, 28 * 28), torch.nn.Sigmoid() ) def forward(self, x): encoded = self.encoder(x) decoded = self.decoder(encoded) return decoded # Instantiating the model and hyperparameters model = DeepAutoencoder() criterion = torch.nn.MSELoss() num_epochs = 100 optimizer = torch.optim.Adam(model.parameters(), lr=1e-3)
Paso 3: Ciclo de entrenamiento
El ciclo de entrenamiento itera por las 100 épocas y hace lo siguiente:
- Itera sobre cada lote y calcula la pérdida entre la imagen de salida y la imagen original (que es la salida).
- Promedia la pérdida de cada lote y almacena las imágenes y sus salidas para cada época.
Una vez que finaliza el ciclo, trazamos la pérdida de entrenamiento para comprender mejor el proceso de entrenamiento. Como podemos ver, la pérdida disminuye para cada época consecutiva y, por lo tanto, el entrenamiento puede considerarse exitoso.
Python
# List that will store the training loss
train_loss = []
# Dictionary that will store the
# different images and outputs for
# various epochs
outputs = {}
batch_size = len(train_loader)
# Training loop starts
for epoch in range(num_epochs):
# Initializing variable for storing
# loss
running_loss = 0
# Iterating over the training dataset
for batch in train_loader:
# Loading image(s) and
# reshaping it into a 1-d vector
img, _ = batch
img = img.reshape(-1, 28*28)
# Generating output
out = model(img)
# Calculating loss
loss = criterion(out, img)
# Updating weights according
# to the calculated loss
optimizer.zero_grad()
loss.backward()
optimizer.step()
# Incrementing loss
running_loss += loss.item()
# Averaging out loss over entire batch
running_loss /= batch_size
train_loss.append(running_loss)
# Storing useful images and
# reconstructed outputs for the last batch
outputs[epoch+1] = {'img': img, 'out': out}
# Plotting the training loss
plt.plot(range(1,num_epochs+1),train_loss)
plt.xlabel("Number of epochs")
plt.ylabel("Training Loss")
plt.show()
Producción:
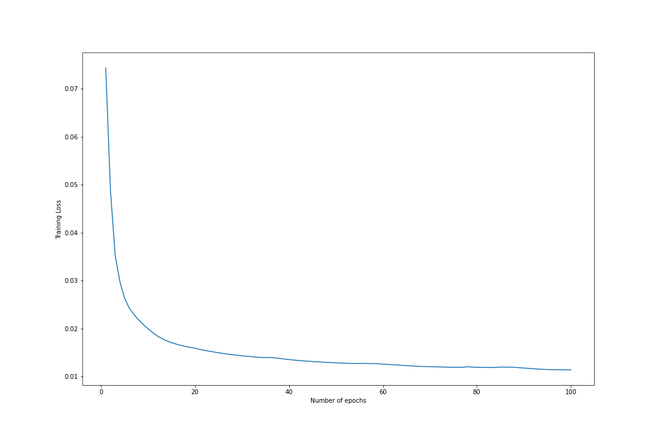
Pérdida de entrenamiento vs. Épocas
Paso 4: Visualización de la reconstrucción
La mejor parte de este proyecto es que el lector puede visualizar la reconstrucción de cada época y comprender el aprendizaje iterativo del modelo.
- En primer lugar, trazamos las primeras 5 imágenes reconstruidas (o generadas) para las épocas = [1, 5, 10, 50, 100].
- Luego, también trazamos las imágenes originales correspondientes en la parte inferior para comparar.
Podemos ver como la reconstrucción mejora para cada época y se acerca mucho al original de la última época.
Python
# Plotting is done on a 7x5 subplot
# Plotting the reconstructed images
# Initializing subplot counter
counter = 1
# Plotting reconstructions
# for epochs = [1, 5, 10, 50, 100]
epochs_list = [1, 5, 10, 50, 100]
# Iterating over specified epochs
for val in epochs_list:
# Extracting recorded information
temp = outputs[val]['out'].detach().numpy()
title_text = f"Epoch = {val}"
# Plotting first five images of the last batch
for idx in range(5):
plt.subplot(7, 5, counter)
plt.title(title_text)
plt.imshow(temp[idx].reshape(28,28), cmap= 'gray')
plt.axis('off')
# Incrementing the subplot counter
counter+=1
# Plotting original images
# Iterating over first five
# images of the last batch
for idx in range(5):
# Obtaining image from the dictionary
val = outputs[10]['img']
# Plotting image
plt.subplot(7,5,counter)
plt.imshow(val[idx].reshape(28, 28),
cmap = 'gray')
plt.title("Original Image")
plt.axis('off')
# Incrementing subplot counter
counter+=1
plt.tight_layout()
plt.show()
Producción:

Visualización de la reconstrucción a partir de los datos recopilados durante el proceso de entrenamiento
Paso 5: Comprobación del rendimiento en el equipo de prueba.
Una buena práctica en el aprendizaje automático es verificar también el rendimiento del modelo en el conjunto de prueba. Para ello, realizamos los siguientes pasos:
- Genere salidas para el último lote del conjunto de prueba.
- Trace las primeras 10 salidas y las imágenes originales correspondientes para comparar.
Como podemos ver, la reconstrucción también fue excelente en este conjunto de prueba, lo que completa la tubería.
Python
# Dictionary that will store the different
# images and outputs for various epochs
outputs = {}
# Extracting the last batch from the test
# dataset
img, _ = list(test_loader)[-1]
# Reshaping into 1d vector
img = img.reshape(-1, 28 * 28)
# Generating output for the obtained
# batch
out = model(img)
# Storing information in dictionary
outputs['img'] = img
outputs['out'] = out
# Plotting reconstructed images
# Initializing subplot counter
counter = 1
val = outputs['out'].detach().numpy()
# Plotting first 10 images of the batch
for idx in range(10):
plt.subplot(2, 10, counter)
plt.title("Reconstructed \n image")
plt.imshow(val[idx].reshape(28, 28), cmap='gray')
plt.axis('off')
# Incrementing subplot counter
counter += 1
# Plotting original images
# Plotting first 10 images
for idx in range(10):
val = outputs['img']
plt.subplot(2, 10, counter)
plt.imshow(val[idx].reshape(28, 28), cmap='gray')
plt.title("Original Image")
plt.axis('off')
# Incrementing subplot counter
counter += 1
plt.tight_layout()
plt.show()
Producción:
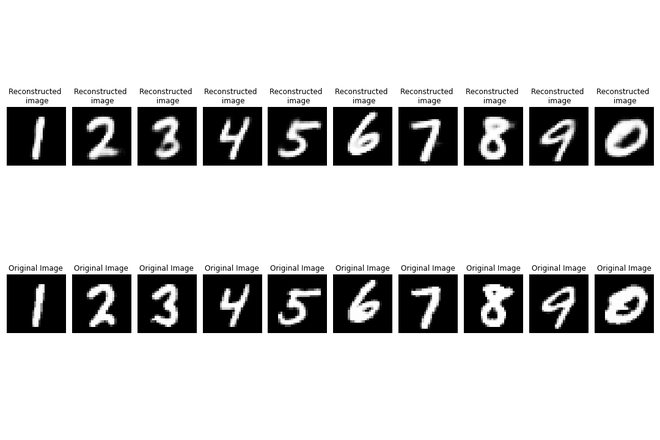
Verificación del rendimiento en el equipo de prueba
Conclusión:
Los codificadores automáticos se están convirtiendo rápidamente en una de las áreas de investigación más emocionantes en el aprendizaje automático. Este artículo cubrió la implementación de Pytorch de un codificador automático profundo para la reconstrucción de imágenes. Se anima al lector a jugar con la arquitectura de la red y los hiperparámetros para mejorar la calidad de la reconstrucción y los valores de pérdida.
Publicación traducida automáticamente
Artículo escrito por adityasaini70 y traducido por Barcelona Geeks. The original can be accessed here. Licence: CCBY-SA