Feature Scaling es una técnica para estandarizar las características independientes presentes en los datos en un rango fijo. Se realiza durante el preprocesamiento de datos para manejar magnitudes, valores o unidades muy variables. Si no se realiza el escalado de características, entonces un algoritmo de aprendizaje automático tiende a sopesar los valores más altos, más altos y considera los valores más pequeños como los valores más bajos, independientemente de la unidad de los valores.
Ejemplo: si un algoritmo no utiliza el método de escalado de características, puede considerar que el valor de 3000 metros es mayor que 5 km, pero en realidad no es cierto y, en este caso, el algoritmo dará predicciones incorrectas. Por lo tanto, usamos Feature Scaling para llevar todos los valores a las mismas magnitudes y, por lo tanto, abordar este problema.
Técnicas para realizar Feature Scaling
Considere las dos más importantes:
- Normalización mín.-máx.: esta técnica vuelve a escalar una característica o un valor de observación con un valor de distribución entre 0 y 1.

- Estandarización: es una técnica muy efectiva que vuelve a escalar el valor de una característica para que tenga una distribución con un valor medio de 0 y una varianza igual a 1.

Descargue el conjunto de datos:
vaya al enlace y descargue Data_for_Feature_Scaling.csv
Código: código de Python que explica el funcionamiento de Feature Scaling en los datos
# Python code explaining How to
# perform Feature Scaling
""" PART 1
Importing Libraries """
import numpy as np
import matplotlib.pyplot as plt
import pandas as pd
# Sklearn library
from sklearn import preprocessing
""" PART 2
Importing Data """
data_set = pd.read_csv('C:\\Users\\dell\\Desktop\\Data_for_Feature_Scaling.csv')
data_set.head()
# here Features - Age and Salary columns
# are taken using slicing
# to handle values with varying magnitude
x = data_set.iloc[:, 1:3].values
print ("\nOriginal data values : \n", x)
""" PART 4
Handling the missing values """
from sklearn import preprocessing
""" MIN MAX SCALER """
min_max_scaler = preprocessing.MinMaxScaler(feature_range =(0, 1))
# Scaled feature
x_after_min_max_scaler = min_max_scaler.fit_transform(x)
print ("\nAfter min max Scaling : \n", x_after_min_max_scaler)
""" Standardisation """
Standardisation = preprocessing.StandardScaler()
# Scaled feature
x_after_Standardisation = Standardisation.fit_transform(x)
print ("\nAfter Standardisation : \n", x_after_Standardisation)
Producción :
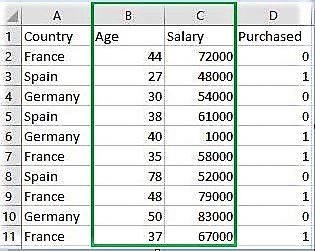
Country Age Salary Purchased 0 France 44 72000 0 1 Spain 27 48000 1 2 Germany 30 54000 0 3 Spain 38 61000 0 4 Germany 40 1000 1 Original data values : [[ 44 72000] [ 27 48000] [ 30 54000] [ 38 61000] [ 40 1000] [ 35 58000] [ 78 52000] [ 48 79000] [ 50 83000] [ 37 67000]] After min max Scaling : [[ 0.33333333 0.86585366] [ 0. 0.57317073] [ 0.05882353 0.64634146] [ 0.21568627 0.73170732] [ 0.25490196 0. ] [ 0.15686275 0.69512195] [ 1. 0.62195122] [ 0.41176471 0.95121951] [ 0.45098039 1. ] [ 0.19607843 0.80487805]] After Standardisation : [[ 0.09536935 0.66527061] [-1.15176827 -0.43586695] [-0.93168516 -0.16058256] [-0.34479687 0.16058256] [-0.1980748 -2.59226136] [-0.56487998 0.02294037] [ 2.58964459 -0.25234403] [ 0.38881349 0.98643574] [ 0.53553557 1.16995867] [-0.41815791 0.43586695]]
Publicación traducida automáticamente
Artículo escrito por Mohit Gupta_OMG 🙂 y traducido por Barcelona Geeks. The original can be accessed here. Licence: CCBY-SA