Pérdida de registro
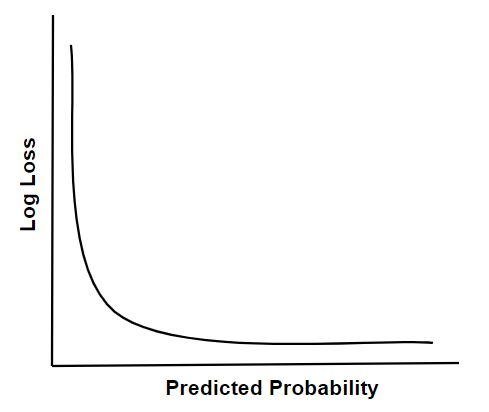
Es la medida de evaluación para comprobar el rendimiento del modelo de clasificación. Mide la cantidad de divergencia de la probabilidad predicha con la etiqueta real. Entonces, cuanto menor sea el valor de pérdida de registro, mayor será la perfección del modelo. Para un modelo perfecto, el valor de pérdida de registro = 0. Por ejemplo, como la precisión es el recuento de predicciones correctas, es decir, la predicción que coincide con la etiqueta real, el valor de pérdida de registro es la medida de incertidumbre de nuestras etiquetas predichas en función de cómo varía de la etiqueta real.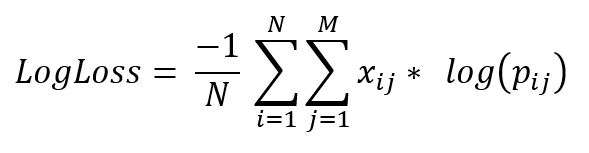
where, N : no. of samples. M : no. of attributes. yij : indicates whether ith sample belongs to jth class or not. pij : indicates probability of ith sample belonging to jth class.
Implementación de LogLoss usando sklearn
from sklearn.metrics import log_loss: LogLoss = log_loss(y_true, y_pred, eps = 1e-15, normalize = True, sample_weight = None, labels = None)
Error medio cuadrado
Es simplemente el promedio del cuadrado de la diferencia entre los valores originales y los valores pronosticados.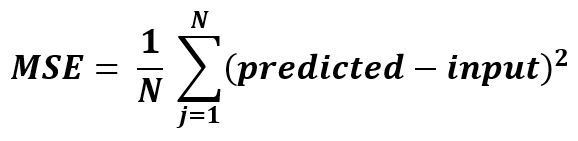
Implementación del error cuadrático medio usando sklearn
from sklearn.metrics import mean_squared_error MSE = mean_squared_error(y_true, y_pred)
Publicación traducida automáticamente
Artículo escrito por Mohit Gupta_OMG 🙂 y traducido por Barcelona Geeks. The original can be accessed here. Licence: CCBY-SA