El aprendizaje profundo es un subcampo del aprendizaje automático relacionado con las redes neuronales artificiales. La palabra profunda significa redes neuronales más grandes con muchas unidades ocultas. Las CNN de aprendizaje profundo han demostrado ser la técnica más avanzada para tareas de reconocimiento de imágenes. Keras es una biblioteca de aprendizaje profundo en Python que proporciona una interfaz para crear una red neuronal artificial. Es un programa de código abierto. Está construido sobre Tensorflow.
El objetivo principal de este artículo es implementar una CNN para realizar la clasificación de imágenes en el famoso conjunto de datos MNIST de moda. En esto, implementaremos nuestra propia arquitectura CNN. El proceso se dividirá en tres pasos: análisis de datos, entrenamiento de modelos y predicción.
Primero, incluyamos todas las bibliotecas requeridas
Python3
# To load the mnist data from keras.datasets import fashion_mnist from tensorflow.keras.models import Sequential # importing various types of hidden layers from tensorflow.keras.layers import Conv2D, MaxPooling2D, Dense, Flatten # Adam optimizer for better LR and less loss from tensorflow.keras.optimizers import Adam import matplotlib.pyplot as plt import numpy as np
Análisis de los datos
En el análisis de datos, veremos la cantidad de imágenes disponibles, las dimensiones de cada imagen, etc. Luego dividiremos los datos en entrenamiento y prueba.
El conjunto de datos del MNIST de moda consta de 60 000 imágenes para el conjunto de entrenamiento y 10 000 imágenes para el conjunto de prueba. Cada imagen es una imagen en escala de grises de tamaño 28 x 28 clasificada en diez clases diferentes.
Cada imagen tiene una etiqueta asociada a ella. Hay, en total, diez etiquetas disponibles, y son:
- camiseta/parte superior
- Pantalón
- Pull-over
- Vestir
- Abrigo
- Sandalia
- Camisa
- zapatilla de deporte
- Bolsa
- Botín
Python3
# Split the data into training and testing
(trainX, trainy), (testX, testy) = fashion_mnist.load_data()
# Print the dimensions of the dataset
print('Train: X = ', trainX.shape)
print('Test: X = ', testX.shape)
Visualización de datos
Ahora veremos algunas de las imágenes de muestra del conjunto de datos MNIST de moda. Para esto, usaremos la biblioteca matplotlib para mostrar los datos de nuestra array np en forma de gráficos de imágenes.
Python3
for i in range(1, 10):
# Create a 3x3 grid and place the
# image in ith position of grid
plt.subplot(3, 3, i)
# Insert ith image with the color map 'grap'
plt.imshow(trainX[i], cmap=plt.get_cmap('gray'))
# Display the entire plot
plt.show()
Producción:

Agregaremos una dimensión de color vacía al conjunto de datos. Ahora las dimensiones de las imágenes serán de 28 x 28 x 1, por lo que ahora las imágenes se han convertido en imágenes de tres canales.
Python3
trainX = np.expand_dims(trainX, -1) testX = np.expand_dims(testX, -1) print(trainX.shape)
Redes neuronales convolucionales (CNN)
La red neuronal convolucional (CNN) es una subclase de una red neuronal artificial (ANN) que se utiliza principalmente para aplicaciones relacionadas con imágenes. La entrada para una CNN es una imagen, y se realizan diferentes operaciones en esa imagen para extraer sus características importantes y luego decidir los pesos para dar la salida correcta. Estas funciones se aprenden mediante filtros. Los filtros ayudan a detectar ciertas propiedades de la imagen, como líneas horizontales, líneas verticales, bordes, esquinas, etc. A medida que profundizamos en la red, la red aprende a detectar características complejas como objetos, cara, fondo, primer plano, etc.
Las CNN tienen tres tipos principales de capas:
- Capa Convolucional: Esta capa es la capa principal de CNN. Cuando se introduce una imagen en la capa de convolución, se utiliza un filtro o un núcleo de tamaño variable, pero generalmente de tamaño 3×3, para detectar las características. El producto punto se lleva a cabo con la imagen, y el núcleo es la salida que se almacena en una celda de una array que se denomina mapa de características o mapa de activación. Una vez realizada la operación, el filtro se desplaza una distancia y luego repite el proceso. Esta distancia se llama zancada. Después de cada operación de convolución, se aplica una transformación ReLu al mapa de características para introducir la no linealidad en el modelo.
- Capa de agrupación: esta capa es responsable de reducir la cantidad de parámetros en la siguiente capa. También se conoce como downsampling o reducción de dimensionalidad.
- Capa totalmente conectada: las neuronas de esta capa tienen conectividad total con todas las neuronas de la capa anterior y la capa siguiente. La capa FC ayuda a mapear la entrada con la salida.
Entrenamiento modelo
Crearemos una arquitectura CNN sencilla con tres capas convolucionales seguidas de tres capas de agrupación máxima para este conjunto de datos. Las capas convolucionales realizarán la operación convolucional y extraerán las características, mientras que la capa de agrupación máxima reducirá la muestra de las características.
Python3
def model_arch(): models = Sequential() # We are learning 64 # filters with a kernal size of 5x5 models.add(Conv2D(64, (5, 5), padding="same", activation="relu", input_shape=(28, 28, 1))) # Max pooling will reduce the # size with a kernal size of 2x2 models.add(MaxPooling2D(pool_size=(2, 2))) models.add(Conv2D(128, (5, 5), padding="same", activation="relu")) models.add(MaxPooling2D(pool_size=(2, 2))) models.add(Conv2D(256, (5, 5), padding="same", activation="relu")) models.add(MaxPooling2D(pool_size=(2, 2))) # Once the convolutional and pooling # operations are done the layer # is flattened and fully connected layers # are added models.add(Flatten()) models.add(Dense(256, activation="relu")) # Finally as there are total 10 # classes to be added a FCC layer of # 10 is created with a softmax activation # function models.add(Dense(10, activation="softmax")) return models
Una vez definida la arquitectura del modelo, compilaremos y construiremos el modelo.
Python3
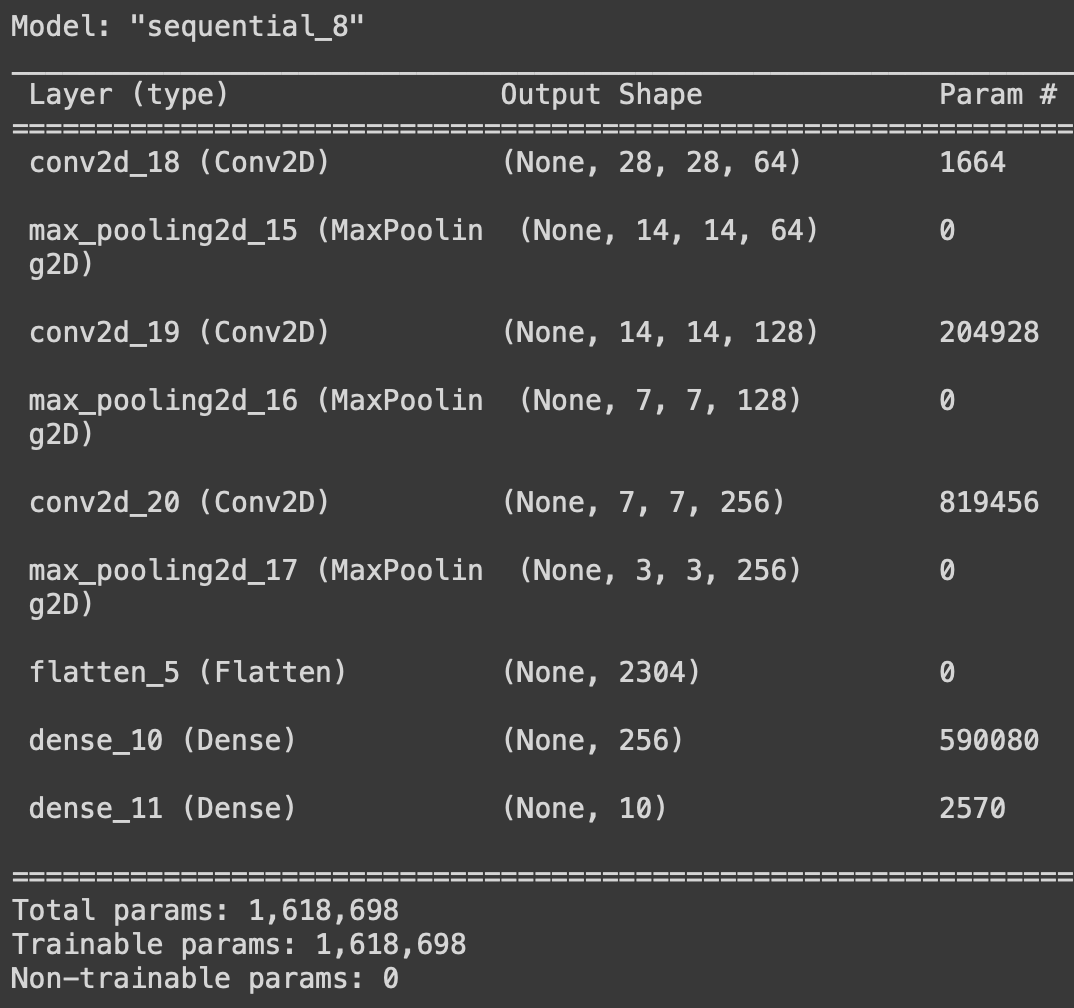
model = model_arch() model.compile(optimizer=Adam(learning_rate=1e-3), loss='sparse_categorical_crossentropy', metrics=['sparse_categorical_accuracy']) model.summary()
Usamos optimizadores de Adam en la mayoría de las arquitecturas de CNN porque son muy eficientes en problemas más grandes y nos ayudan a lograr pesos correctos y tasas de aprendizaje con pérdidas mínimas. El resumen del modelo es el siguiente.
Una vez que se establecen todos los parámetros del modelo, el modelo está listo para ser entrenado. Entrenaremos el modelo durante diez épocas, y cada época tendrá 100 pasos.
Python3
history = model.fit( trainX.astype(np.float32), trainy.astype(np.float32), epochs=10, steps_per_epoch=100, validation_split=0.33 )
Guardemos el modelo.
Python3
model.save_weights('./model.h5', overwrite=True)
Análisis del modelo
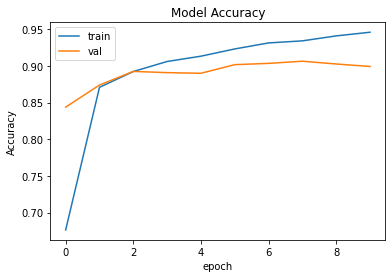
En esta sección, trazaremos algunos gráficos relacionados con la precisión y la pérdida para evaluar el rendimiento del modelo. Primero, veremos la precisión y trazaremos la pérdida.
Python3
# Accuracy vs Epoch plot
plt.plot(history.history['sparse_categorical_accuracy'])
plt.plot(history.history['val_sparse_categorical_accuracy'])
plt.title('Model Accuracy')
plt.ylabel('Accuracy')
plt.xlabel('epoch')
plt.legend(['train', 'val'], loc='upper left')
plt.show()
Producción:
Python3
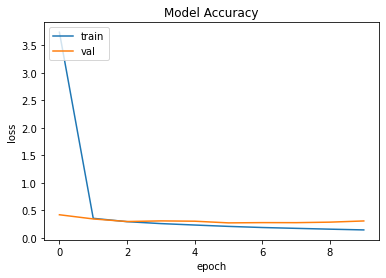
# Loss vs Epoch plot
plt.plot(history.history['loss'])
plt.plot(history.history['val_loss'])
plt.title('Model Accuracy')
plt.ylabel('loss')
plt.xlabel('epoch')
plt.legend(['train', 'val'], loc='upper left')
plt.show()
Producción:
Para hacer las predicciones, llame a la función predict() en el modelo y pásele la imagen. Para realizar la predicción, primero crearemos una lista de etiquetas en el orden de la capa de salida correspondiente de la CNN. La función predecir() devolverá la lista de valores de probabilidades de que la entrada actual probablemente pertenezca a qué clase. Luego, al usar argmax(), encontraremos el valor más alto y luego generaremos la etiqueta correcta.
Python3
# There are 10 output labels for the Fashion MNIST dataset labels = ['t_shirt', 'trouser', 'pullover', 'dress', 'coat', 'sandal', 'shirt', 'sneaker', 'bag', 'ankle_boots'] # Make a prediction predictions = model.predict(testX[:1]) label = labels[np.argmax(predictions)] print(label) plt.imshow(testX[:1][0]) plt.show()
Producción:
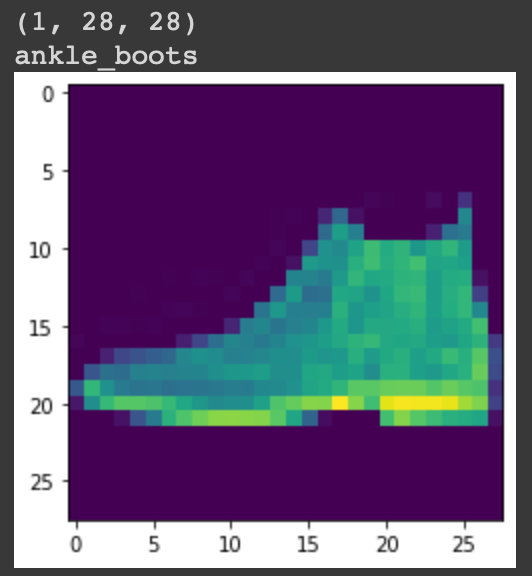
Por lo tanto, hemos realizado con éxito la clasificación de imágenes en el conjunto de datos MNIST de moda.
Publicación traducida automáticamente
Artículo escrito por sahilgangurde08 y traducido por Barcelona Geeks. The original can be accessed here. Licence: CCBY-SA