Los r-vecinos más cercanos son una versión modificada de los k-vecinos más cercanos . El problema con k-vecinos más cercanos es la elección de k. Con una k más pequeña, el clasificador sería más sensible a los valores atípicos. Si el valor de k es grande, entonces el clasificador incluiría muchos puntos de otras clases. Es a partir de esta lógica que obtenemos el algoritmo r vecinos cercanos.
Intuición:
Considere los siguientes datos, como el conjunto de entrenamiento.
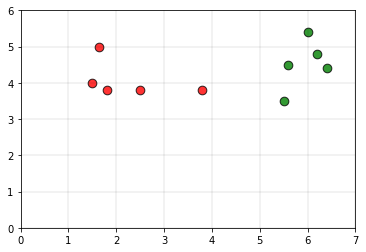
Los puntos de color verde pertenecen a la clase 0 y los puntos de color rojo pertenecen a la clase 1. Considere el punto blanco P como el punto de consulta cuyo
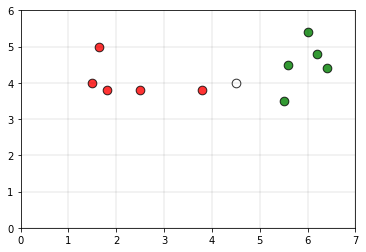
Si tomamos el radio del círculo como 2.2 unidades y si se dibuja un círculo usando el punto P como el centro del círculo, la gráfica sería la siguiente
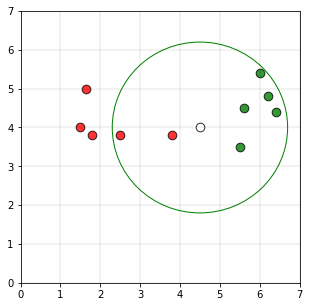
Como el número de puntos del círculo pertenecientes a la clase 1 (5 puntos) es mayor que el número de puntos pertenecientes a la clase 0 (2 puntos)
Algoritmo:
Paso 1: dado el punto P, determine el subconjunto de datos que se encuentra en la bola de radio r con centro en P,
segundo r (PAG) = { X yo ∊ X | dist( P, X i ) ≤ r }Paso 2: si B r (P) está vacío, genere la clase mayoritaria de todo el conjunto de datos.
Paso 3: si B r (P) no está vacío, genere la clase mayoritaria de los puntos de datos que contiene.
La implementación del algoritmo de vecinos del radio r es la siguiente:
C++
// C++ program to implement the
// r nearest neighbours algorithm.
#include <bits/stdc++.h>
using namespace std;
struct Point
{
// Class of point
int val;
// Co-ordinate of point
double x, y;
};
// This function classifies the point p using
// r k nearest neighbour algorithm. It assumes only
// two groups and returns 0 if p belongs to class 0, else
// 1 (belongs to class 1).
int rNN(Point arr[], int n, float r, Point p)
{
// frequency of group 0
int freq1 = 0;
// frequency of group 1
int freq2 = 0;
// Check if the distance is less than r
for (int i = 0; i < n; i++)
{
if ((sqrt((arr[i].x - p.x) * (arr[i].x - p.x) +
(arr[i].y - p.y) * (arr[i].y - p.y))) <= r)
{
if (arr[i].val == 0)
freq1++;
else if (arr[i].val == 1)
freq2++;
}
}
return (freq1 > freq2 ? 0 : 1);
}
// Driver code
int main()
{
// Number of data points
int n = 10;
Point arr[n];
arr[0].x = 1.5;
arr[0].y = 4;
arr[0].val = 0;
arr[1].x = 1.8;
arr[1].y = 3.8;
arr[1].val = 0;
arr[2].x = 1.65;
arr[2].y = 5;
arr[2].val = 0;
arr[3].x = 2.5;
arr[3].y = 3.8;
arr[3].val = 0;
arr[4].x = 3.8;
arr[4].y = 3.8;
arr[4].val = 0;
arr[5].x = 5.5;
arr[5].y = 3.5;
arr[5].val = 1;
arr[6].x = 5.6;
arr[6].y = 4.5;
arr[6].val = 1;
arr[7].x = 6;
arr[7].y = 5.4;
arr[7].val = 1;
arr[8].x = 6.2;
arr[8].y = 4.8;
arr[8].val = 1;
arr[9].x = 6.4;
arr[9].y = 4.4;
arr[9].val = 1;
// Query point
Point p;
p.x = 4.5;
p.y = 4;
// Parameter to decide the class of the query point
float r = 2.2;
printf("The value classified to query point"
" is: %d.\n", rNN(arr, n, r, p));
return 0;
}
Python3
# Python3 program to implement the
# r nearest neighbours algorithm.
import math
def rNN(points, p, r = 2.2):
'''
This function classifies the point p using
r k nearest neighbour algorithm. It assumes only
two groups and returns 0 if p belongs to class 0, else
1 (belongs to class 1).
Parameters -
points : Dictionary of training points having two
keys - 0 and 1. Each class have a list of
training data points belonging to them
p : A tuple, test data point of form (x, y)
k : radius of the r nearest neighbors
'''
freq1 = 0
freq2 = 0
for group in points:
for feature in points[group]:
if math.sqrt((feature[0]-p[0])**2 +
(feature[1]-p[1])**2) <= r:
if group == 0:
freq1 += 1
elif group == 1:
freq2 += 1
return 0 if freq1>freq2 else 1
# Driver function
def main():
# Dictionary of training points having two keys - 0 and 1
# key 0 have points belong to class 0
# key 1 have points belong to class 1
points = {0:[(1.5, 4), (1.8, 3.8), (1.65, 5), (2.5, 3.8), (3.8, 3.8)],
1:[(5.5, 3.5), (5.6, 4.5), (6, 5.4), (6.2, 4.8), (6.4, 4.4)]}
# query point p(x, y)
p = (4.5, 4)
# Parameter to decide the class of the query point
r = 2.2
print("The value classified to query point is: {}".format(
rNN(points, p, r)))
if __name__ == '__main__':
main()
The value classified to query point is: 1.
Se pueden usar otras técnicas como kd-tree y hashing sensible a la localidad para reducir la complejidad del tiempo de encontrar a los vecinos.
Aplicaciones: este algoritmo se puede utilizar para identificar valores atípicos. Si un patrón no tiene ninguna similitud con los patrones dentro del radio elegido, puede identificarse como un valor atípico.
Publicación traducida automáticamente
Artículo escrito por kanakalathav99 y traducido por Barcelona Geeks. The original can be accessed here. Licence: CCBY-SA