En este artículo, veremos algunos conceptos básicos de ANN y una implementación simple de una red neuronal artificial. Tensorflow es una poderosa biblioteca de aprendizaje automático para crear modelos y redes neuronales.
Entonces, antes de comenzar ¿Qué son las redes neuronales artificiales? Aquí hay una definición simple y clara de redes neuronales artificiales. En pocas palabras, las redes neuronales artificiales son una larga historia que imita un cerebro humano para aprender de algunas características clave y clasificarlas o predecirlas en el mundo real. Una red neuronal artificial se compone de un número de neuronas que se compara con las neuronas del cerebro humano.
Está diseñado para hacer que una computadora aprenda a partir de pequeños conocimientos y características y hacerla autónoma para aprender del mundo real y brindar soluciones en tiempo real más rápido que un humano.
Una neurona en una red neuronal artificial, realizará dos operaciones en su interior
- Suma de todos los pesos
- Función de activación
Entonces, una red neuronal artificial básica tendrá la forma de,
- Capa de entrada : para obtener los datos del usuario o un cliente o un servidor para analizar y dar el resultado.
- Capas ocultas : esta capa puede estar en cualquier número y estas capas analizarán las entradas al pasar a través de ellas con diferentes sesgos, pesos y funciones de activación para proporcionar una salida.
- Capa de salida : aquí es donde podemos obtener el resultado de una red neuronal.
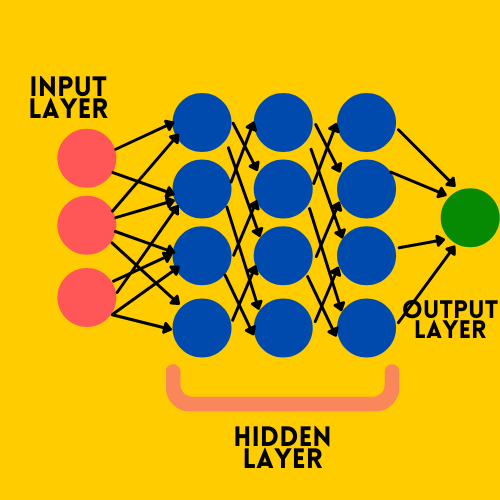
Entonces, como conocemos el esquema de las redes neuronales, ahora pasaremos a las funciones y métodos importantes que ayudan a una red neuronal a aprender correctamente de los datos.
Nota: Cualquier red neuronal puede aprender de los datos, pero sin buenos valores de parámetros, es posible que una red neuronal no pueda aprender de los datos correctamente y no le dará el resultado correcto.
Algunas de las características que determinan la calidad de nuestra red neuronal son:
- Capas
- Función de activación
- Función de pérdida
- Optimizador
Ahora vamos a discutir cada uno de ellos en detalle,
La primera etapa de la construcción de nuestro modelo es:
Python3
# Defining the model model = keras.Sequential([ keras.layers.Dense(32, input_shape=(2,), activation='relu'), keras.layers.Dense(16, activation = 'relu'), keras.layers.Dense(2, activation = 'sigmoid') ])
Capas
Las capas en una red neuronal son muy importantes, como vimos anteriormente, una red neuronal artificial consta de 3 capas: una capa de entrada, una capa oculta y una capa de salida. La capa de entrada consta de las características y los valores que deben analizarse dentro de una red neuronal. Básicamente, esta es una capa que leerá nuestras características de entrada en una red neuronal artificial.
Una capa oculta es una capa donde ocurre toda la magia cuando todas las neuronas de entrada pasan las características a la capa oculta con un peso y un sesgo. Todas y cada una de las neuronas dentro de la capa oculta sumarán todas las características ponderadas de todas las capas de entrada y aplique una función de activación para mantener los valores entre 0 y 1 para facilitar el aprendizaje. Aquí debemos elegir el número de neuronas en cada capa manualmente y debe ser el mejor valor para la red.
Aquí los verdaderos tomadores de decisiones son los pesos entre cada capa que finalmente pasarán un valor de 0 a 1 a la capa de salida. Hasta aquí hemos visto la importancia de cada nivel de capas en una red neuronal artificial. Hay muchos tipos de capas en TensorFlow pero la que usaremos mucho es Dense
sintaxis: tf.keras.layers.Dense()
Esta es una capa completamente conectada en la que todas y cada una de las entradas de funciones estarán conectadas de alguna manera con el resultado.
Función de activación
Las funciones de activación son simplemente métodos matemáticos que llevan todos los valores dentro de un rango de 0 a 1 para que sea mucho más fácil para la máquina aprender los datos en su proceso de análisis de datos. Hay una variedad de funciones de activación que son compatibles con el flujo Tensor. Algunas de las funciones comúnmente utilizadas son,
- Sigmoideo
- Relú
- softmax
- Silbido
- Lineal
Todas y cada una de las funciones de activación tienen sus propios casos de uso e inconvenientes específicos. Pero la función de activación que se usa en las capas ocultas y de entrada es ‘Relu’ y otra que tendrá un mayor impacto en el resultado son las pérdidas.
Luego de esto, podemos ver los parámetros en la compilación del modelo en TensorFlow,
Python
# Compilation of model model.compile(optimizer='adam' loss=a_loss_function metrics=['metrics'])
Pérdidas
Es muy importante tener en cuenta las funciones de pérdida al crear una red neuronal porque las funciones de pérdida en la red neuronal calcularán la diferencia entre la salida predicha y el resultado real y ayudarán en gran medida a los optimizadores en las redes neuronales a actualizar los pesos en su retropropagación.
Hay muchas funciones de pérdida que fueron compatibles con la biblioteca TensorFlow y, nuevamente, algunas de las más utilizadas son,
- Media absoluta
- Error medio cuadrado
- Entropía cruzada binaria
- Entropía cruzada categórica
- Entropía cruzada categórica escasa
Nota: Nuevamente, la elección de la pérdida depende completamente del tipo de problema y el resultado que esperamos de la red neuronal.
Optimizadores
Los optimizadores son una cosa muy importante porque esta es la función que ayuda a la red neuronal a cambiar los pesos en la propagación hacia atrás para que la diferencia entre el resultado real y el pronosticado disminuya a un ritmo gradual y obtenga ese punto donde la pérdida es mínima y el modelo es capaz de predecir resultados más precisos.
De nuevo, TensorFlow es compatible con muchos optimizadores, por mencionar algunos,
- Descenso de gradiente
- SDG – Descenso de gradiente estocástico
- Adagrado
- Adán
Después de compilar el modelo, necesitamos ajustar el modelo con el conjunto de datos para el entrenamiento,
Python
# fitting the model model.fit(train_data, train_label, epochs=5, batch_size=32)
Épocas
Las épocas son simplemente la cantidad de veces que todo el conjunto de datos pasa hacia adelante y hacia atrás al actualizar los pesos en una red neuronal. AL hacer esto, podemos encontrar patrones e información invisibles en cada época y, por lo tanto, mejora la precisión del modelo.
Y para manejar algunas limitaciones de las redes neuronales, como sobreajustar los datos de entrenamiento y no poder funcionar bien en los datos no vistos. Esto se puede resolver con algunas capas de abandono, lo que significa inactivar una cantidad de Nodes en una capa, lo que obliga a todos y cada uno de los Nodes de la red neuronal a aprender más sobre las características de la entrada y, por lo tanto, se puede resolver el problema.
En TensorFlow, agregar un abandono en una capa es literalmente una línea de código,
sintaxis: tf.keras.layers.Dropout(rate, noise_shape=Ninguno, seed=Ninguno, **kwargs )
Cómo entrenar una red neuronal con TensorFlow:
Paso 1: Importación de las bibliotecas
Vamos a importar las bibliotecas requeridas.
Python
# Importing the libraries import pandas as pd import numpy as np from tensorflow import keras from tensorflow.keras import layers from sklearn.model_selection import train_test_split
Paso 2: Importación de los datos
Los datos que usamos para este ejemplo se generan aleatoriamente con Numpy. Puedes descargar los datos aquí . En estos datos, x e y son el punto de las coordenadas y la característica de color es el valor objetivo que se generó aleatoriamente, que es binario y representa Rojo – 1, Azul – 0.
Python
# Importing the data
df = pd.read_csv('data.txt')
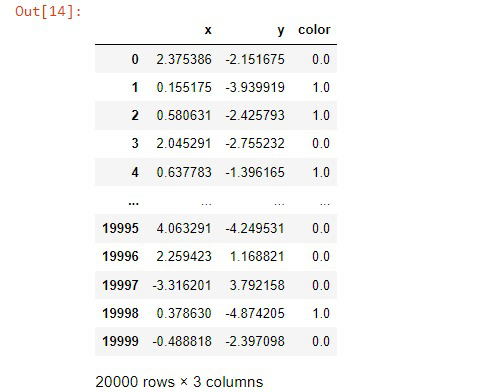
Los datos se verán como:
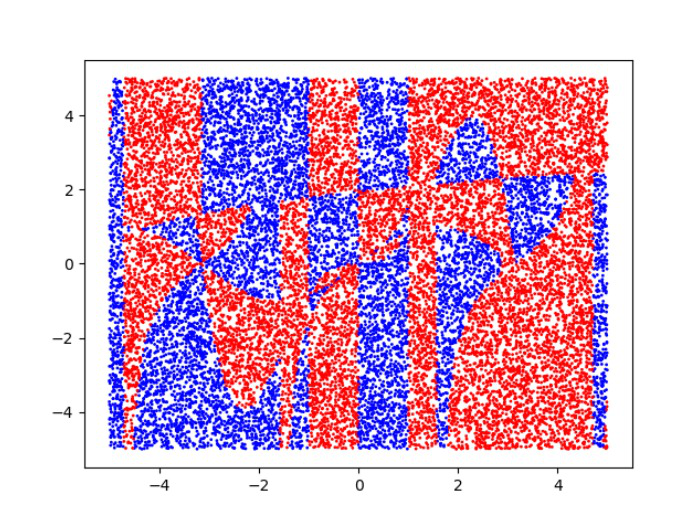
Paso 3: dividir los datos
Ahora vamos a dividir el conjunto de datos en divisiones de entrenamiento y prueba para evaluar el modelo con los datos no vistos y verificar su precisión.
Python
# split the data into train and test set train, test = train_test_split( df, test_size=0.2, random_state=42, shuffle=True)
Paso 4: Construcción de la entrada
En este paso, vamos a construir la entrada que necesitamos para alimentar una red. Para simplificar y por el bien del modelo, vamos a apilar las dos características de los datos en x y la variable de destino como y. Usamos numpy.column_stack() para apilar el
Python
# Constructing the input x = np.column_stack((train.x.values, train.y.values)) y = train.color.values
Paso 5: Construcción de un modelo
Ahora vamos a construir una red neuronal simple para clasificar el color del punto con dos Nodes de entrada y una capa oculta y una capa de salida con funciones de activación sigmoide y relu, y una función de pérdida de entropía cruzada categórica escasa y esto va a ser una red feed-forward totalmente conectada.
Python
# Defining the model model = keras.Sequential([ keras.layers.Dense(4, input_shape=(2,), activation='relu'), keras.layers.Dense(2, activation='sigmoid') ]) # Compiling the model model.compile(optimizer='adam', loss=keras.losses.SparseCategoricalCrossentropy(), metrics=['accuracy']) # fitting the model model.fit(x, y, epochs=10, batch_size=8)
Producción:
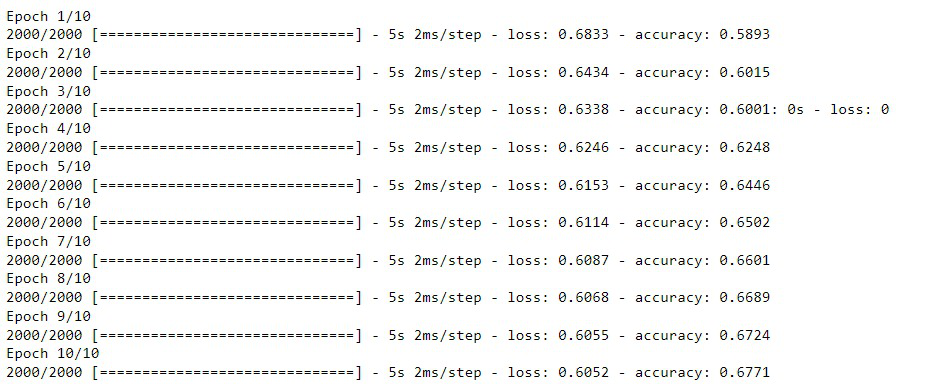
Si evaluamos el modelo con datos no vistos, dará una cantidad muy baja de precisión,
Python
# Evaluating the model x = np.column_stack((test.x.values, test.y.values)) y = test.color.values model.evaluate(x, y, batch_size=8)
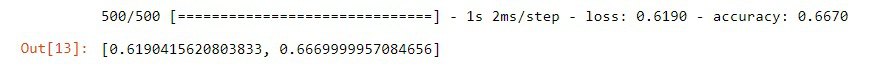
Paso 6: construir un mejor modelo
Ahora vamos a mejorar el modelo con algunas capas ocultas adicionales y una mejor función de activación ‘softmax’ en la capa de salida y construiremos una mejor red neuronal.
Python
# Defining the model model_better = keras.Sequential([ keras.layers.Dense(16, input_shape=(2,), activation='relu'), keras.layers.Dense(32, activation='relu'), keras.layers.Dense(32, activation='relu'), keras.layers.Dense(2, activation='softmax') ]) # Compiling the model model_better.compile(optimizer='adam', loss=keras.losses.SparseCategoricalCrossentropy(), metrics=['accuracy']) # Constructing the input x = np.column_stack((train.x.values, train.y.values)) y = train.color.values # fitting the model model_better.fit(x, y, epochs=10, batch_size=8)
Producción:
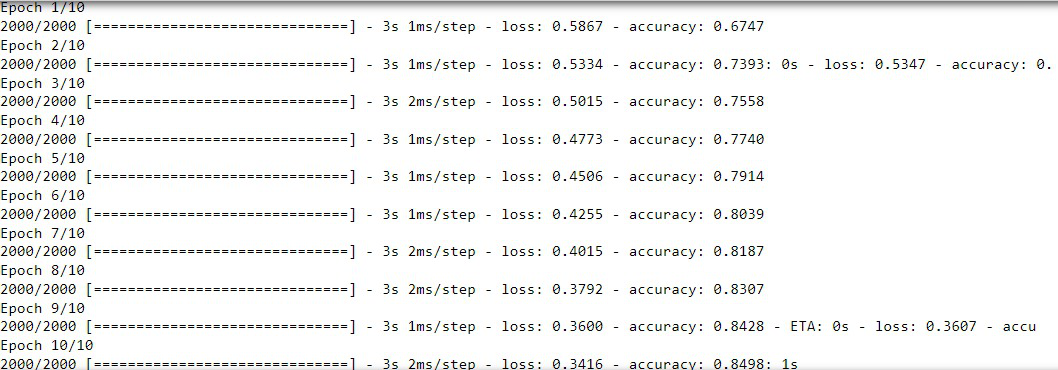
Paso 7: Evaluación del modelo
Finalmente, si evaluamos el modelo, podemos ver claramente que la precisión del modelo en datos no vistos ha mejorado de 66 -> 85. Así que construimos un modelo eficiente.

Publicación traducida automáticamente
Artículo escrito por sanjaysdev0901 y traducido por Barcelona Geeks. The original can be accessed here. Licence: CCBY-SA