Al construir y entrenar redes neuronales, es crucial inicializar los pesos de manera adecuada para garantizar un modelo con alta precisión. Si los pesos no se inicializan correctamente, puede dar lugar al problema del gradiente de fuga o al problema del gradiente explosivo. Por lo tanto, seleccionar una estrategia de inicialización de peso adecuada es fundamental al entrenar modelos DL. En este artículo, aprenderemos algunas de las técnicas de inicialización de peso más comunes, junto con su implementación en Python usando Keras en TensorFlow .
Como requisitos previos, se espera que los lectores de este artículo tengan un conocimiento básico de pesos, sesgos y funciones de activación. Para comprender qué es todo esto, usted y qué papel desempeñan en las redes neuronales profundas, le recomendamos que lea el artículo Red neuronal profunda con L: capas
Terminología o notaciones
Las siguientes anotaciones deben tenerse en cuenta al comprender las técnicas de inicialización de peso. Estas notaciones pueden variar en diferentes publicaciones. Sin embargo, los que se usan aquí son los más comunes, que generalmente se encuentran en trabajos de investigación.
fan_in = Número de caminos de entrada hacia la neurona
fan_out = Número de caminos de salida hacia la neurona
Ejemplo: considere la siguiente neurona como parte de una red neuronal profunda.
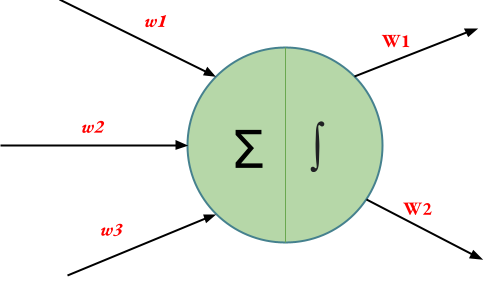
Para la neurona anterior,
fan_in = 3 (Número de caminos de entrada hacia la neurona)
fan_out = 2 (Número de caminos de salida hacia la neurona)
Técnicas de inicialización de pesos
1. Inicialización cero
Como sugiere el nombre, a todos los pesos se les asigna cero ya que el valor inicial es la inicialización cero. Este tipo de inicialización es muy ineficaz ya que las neuronas aprenden la misma característica durante cada iteración. Más bien, durante cualquier tipo de inicialización constante, ocurre el mismo problema. Por lo tanto, no se prefieren las inicializaciones constantes.
La inicialización cero se puede implementar en las capas de Keras en Python de la siguiente manera:
Python3
# Zero Initialization from tensorflow.keras import layers from tensorflow.keras import initializers initializer = tf.keras.initializers.Zeros() layer = tf.keras.layers.Dense( 3, kernel_initializer=initializer)
2. Inicialización aleatoria
En un intento por superar las deficiencias de la inicialización cero o constante, la inicialización aleatoria asigna valores aleatorios, excepto ceros, como pesos a las rutas de las neuronas. Sin embargo, al asignar valores aleatoriamente a los pesos, pueden ocurrir problemas como sobreajuste, problema de gradiente de desaparición, problema de gradiente explosivo.
La inicialización aleatoria puede ser de dos tipos:
- Aleatorio normal
- Uniforme aleatorio
a) Random Normal: Los pesos se inicializan a partir de valores en una distribución normal.

La inicialización normal aleatoria se puede implementar en las capas de Keras en Python de la siguiente manera:
Python3
# Random Normal Distribution from tensorflow.keras import layers from tensorflow.keras import initializers initializer = tf.keras.initializers.RandomNormal( mean=0., stddev=1.) layer = tf.keras.layers.Dense(3, kernel_initializer=initializer)
b) Uniforme Aleatorio: Los pesos se inicializan a partir de valores en una distribución uniforme.
La inicialización uniforme aleatoria se puede implementar en las capas de Keras en Python de la siguiente manera:
Python3
# Random Uniform Initialization from tensorflow.keras import layers from tensorflow.keras import initializers initializer = tf.keras.initializers.RandomUniform( minval=0.,maxval=1.) layer = tf.keras.layers.Dense(3, kernel_initializer=initializer)
3. Inicialización de Xavier/Glorot
En la inicialización de peso de Xavier/Glorot, los pesos se asignan a partir de valores de una distribución uniforme de la siguiente manera:
![w_i \sim U\space[ -\sqrt{ \frac{\sigma }{fan\_in + fan\_out}}, \sqrt{ \frac{\sigma }{fan\_in + fan\_out}}]](https://www.geeksforgeeks.org/wp-content/ql-cache/quicklatex.com-ad8f226636f9e63ba020ec8c9af15d7b_l3.png "Rendered by QuickLaTeX.com")
La inicialización de Xavier/Glorot, a menudo denominada inicialización uniforme de Xavier, es adecuada para capas en las que la función de activación utilizada es Sigmoid. La inicialización de Xavier/Gorat se puede implementar en las capas de Keras en Python de la siguiente manera:
Python3
# Xavier/Glorot Uniform Initialization from tensorflow.keras import layers from tensorflow.keras import initializers initializer = tf.keras.initializers.GlorotUniform() layer = tf.keras.layers.Dense(3, kernel_initializer=initializer)
4. Inicialización normalizada de Xavier/Glorot
En la inicialización de pesos normalizados de Xavier/Glorot, los pesos se asignan a partir de valores de una distribución normal de la siguiente manera:

Aquí,  viene dada por:
viene dada por:

La inicialización de Xavier/Glorot también es adecuada para capas en las que la función de activación utilizada es Sigmoid . La inicialización normalizada de Xavier/Gorat se puede implementar en las capas de Keras en Python de la siguiente manera:
Python3
# Normailzed Xavier/Glorot Uniform Initialization from tensorflow.keras import layers from tensorflow.keras import initializers initializer = tf.keras.initializers.GlorotNormal() layer = tf.keras.layers.Dense(3, kernel_initializer=initializer)
5. Inicialización uniforme
En la inicialización de peso uniforme, los pesos se asignan a partir de valores de una distribución uniforme de la siguiente manera:
![w_i \sim U\space[ -\sqrt{ \frac{6 }{fan\_in}}, \sqrt{ \frac{6}{fan\_out}}]](https://www.geeksforgeeks.org/wp-content/ql-cache/quicklatex.com-8a3618b316f33bb702cf0a28a1ef7e4a_l3.png "Rendered by QuickLaTeX.com")
La inicialización uniforme es adecuada para capas donde se utiliza la función de activación de ReLU . La inicialización uniforme se puede implementar en las capas de Keras en Python de la siguiente manera:
Python3
# He Uniform Initialization from tensorflow.keras import layers from tensorflow.keras import initializers initializer = tf.keras.initializers.HeUniform() layer = tf.keras.layers.Dense(3, kernel_initializer=initializer)
6. La inicialización normal
En la inicialización de peso He Normal, los pesos se asignan a partir de valores de una distribución normal de la siguiente manera:
![w_i \sim N\space[0, \sigma ]](https://www.geeksforgeeks.org/wp-content/ql-cache/quicklatex.com-8faa66dc62c83bcd93c2a857c3e3191e_l3.png "Rendered by QuickLaTeX.com")
Aquí, \sigma viene dada por:

La inicialización uniforme también es adecuada para capas donde se utiliza la función de activación de ReLU . La inicialización uniforme se puede implementar en las capas de Keras en Python de la siguiente manera:
Python3
# He Normal Initialization from tensorflow.keras import layers from tensorflow.keras import initializers initializer = tf.keras.initializers.HeNormal() layer = tf.keras.layers.Dense(3, kernel_initializer=initializer)
Conclusión:
La inicialización del peso es un concepto muy imperativo en las redes neuronales profundas y el uso de la técnica de inicialización correcta puede afectar en gran medida la precisión del modelo de aprendizaje profundo. Por lo tanto, se debe emplear una técnica de inicialización de peso adecuada, teniendo en cuenta varios factores, como la función de activación utilizada.
Publicación traducida automáticamente
Artículo escrito por suvratarora06 y traducido por Barcelona Geeks. The original can be accessed here. Licence: CCBY-SA