Las redes neuronales convolucionales son muy poderosas en tareas de clasificación y reconocimiento de imágenes. Los modelos CNN aprenden características de las imágenes de entrenamiento con varios filtros aplicados en cada capa. Las características aprendidas en cada capa convolucional varían significativamente. Es un hecho observado que las capas iniciales capturan predominantemente los bordes, la orientación de la imagen y los colores en la imagen que son características de bajo nivel. Con un aumento en la cantidad de capas, CNN captura características de alto nivel que ayudan a diferenciar entre varias clases de imágenes.
Para comprender cómo las redes neuronales convolucionales aprenden las dependencias espaciales y temporales de una imagen, se pueden visualizar diferentes características capturadas en cada capa de la siguiente manera.
To visualize the features at each layer, Keras Model class is used. It allows the model to have multiple outputs. It maps given a list of input tensors to list of output tensors.tf.keras.Model()Arguments: inputs: It can be a single input or a list of inputs which are objects ofkeras.Inputclass outputs: Output/ List of outputs.
Teniendo en cuenta un conjunto de datos con imágenes de gatos y perros, construimos una red neuronal convolucional y agregamos un clasificador encima para reconocer la imagen dada como un gato o un perro.
Paso 1: Cargar el conjunto de datos y preprocesar los datos
Las imágenes de entrenamiento y las imágenes de validación se cargan en un generador de datos usando Keras ImageDataGenerator.
El modo de clase se considera ‘Binario’ y el tamaño de lote se considera 20. El tamaño objetivo de la imagen se fija en (150, 150).
from keras.preprocessing.image import ImageDataGenerator train_datagen = ImageDataGenerator(rescale = 1./255) test_datagen = ImageDataGenerator(rescale = 1./255) train_generator = train_datagen.flow_from_directory(train_img_path, target_size =(150, 150), batch_size = 20, class_mode = "binary") validation_generator = test_datagen.flow_from_directory(val_img_path, target_size =(150, 150), batch_size = 20, class_mode = "binary")
Paso 2: Arquitectura del modelo
Se agrega una combinación de capas convolucionales bidimensionales y capas de agrupación máxima, también se agrega una capa de clasificación densa encima. Para la capa Densa final, se usa la función de activación Sigmoid ya que es un problema de clasificación de dos clases.
from keras import models from keras import layers model = models.Sequential() model.add(layers.Conv2D(32, (3, 3), activation ='relu', input_shape =(150, 150, 3))) model.add(layers.MaxPooling2D((2, 2))) model.add(layers.Conv2D(64, (3, 3), activation ='relu')) model.add(layers.MaxPooling2D((2, 2))) model.add(layers.Conv2D(128, (3, 3), activation ='relu')) model.add(layers.MaxPooling2D((2, 2))) model.add(layers.Conv2D(128, (3, 3), activation ='relu')) model.add(layers.MaxPooling2D((2, 2))) model.add(layers.Flatten()) model.add(layers.Dense(512, activation ='relu')) model.add(layers.Dense(1, activation ="sigmoid")) model.summary()
Salida: Resumen del modelo
Model: "sequential_1" _________________________________________________________________ Layer (type) Output Shape Param # ================================================================= conv2d_1 (Conv2D) (None, 148, 148, 32) 896 _________________________________________________________________ max_pooling2d_1 (MaxPooling2 (None, 74, 74, 32) 0 _________________________________________________________________ conv2d_2 (Conv2D) (None, 72, 72, 64) 18496 _________________________________________________________________ max_pooling2d_2 (MaxPooling2 (None, 36, 36, 64) 0 _________________________________________________________________ conv2d_3 (Conv2D) (None, 34, 34, 128) 73856 _________________________________________________________________ max_pooling2d_3 (MaxPooling2 (None, 17, 17, 128) 0 _________________________________________________________________ conv2d_4 (Conv2D) (None, 15, 15, 128) 147584 _________________________________________________________________ max_pooling2d_4 (MaxPooling2 (None, 7, 7, 128) 0 _________________________________________________________________ flatten_1 (Flatten) (None, 6272) 0 _________________________________________________________________ dense_1 (Dense) (None, 512) 3211776 _________________________________________________________________ dense_2 (Dense) (None, 1) 513 ================================================================= Total params: 3, 453, 121 Trainable params: 3, 453, 121 Non-trainable params: 0
Paso 3: Compilación y entrenamiento del modelo en el conjunto de datos de gatos y perros
Función de pérdida: Cruz binaria
Optimizador de entropía: RMSprop
Métricas: Precisión
from keras import optimizers model.compile(loss ="binary_crossentropy", optimizer = optimizers.RMSprop(lr = 1e-4), metrics =['accuracy']) history = model.fit_generator(train_generator, steps_per_epoch = 100, epochs = 30, validation_data = validation_generator, validation_steps = 50)
Paso 4: Visualización de activaciones intermedias (Salida de cada capa)
Considere una imagen que no se usa para entrenamiento, es decir, a partir de datos de prueba, almacene la ruta de la imagen en una variable ‘image_path’.
from keras.preprocessing import image import numpy as np # Pre-processing the image img = image.load_img(image_path, target_size = (150, 150)) img_tensor = image.img_to_array(img) img_tensor = np.expand_dims(img_tensor, axis = 0) img_tensor = img_tensor / 255. # Print image tensor shape print(img_tensor.shape) # Print image import matplotlib.pyplot as plt plt.imshow(img_tensor[0]) plt.show()
Producción:
Tensor shape:
(1, 150, 150, 3)
Input image:

Código: uso de la clase Keras Model para obtener resultados de cada capa
# Outputs of the 8 layers, which include conv2D and max pooling layers layer_outputs = [layer.output for layer in model.layers[:8]] activation_model = models.Model(inputs = model.input, outputs = layer_outputs) activations = activation_model.predict(img_tensor) # Getting Activations of first layer first_layer_activation = activations[0] # shape of first layer activation print(first_layer_activation.shape) # 6th channel of the image after first layer of convolution is applied plt.matshow(first_layer_activation[0, :, :, 6], cmap ='viridis') # 15th channel of the image after first layer of convolution is applied plt.matshow(first_layer_activation[0, :, :, 15], cmap ='viridis')
Producción:
First layer activation shape: (1, 148, 148, 32) Sixth channel of first layer activation:Fifteenth channel of first layer activation:
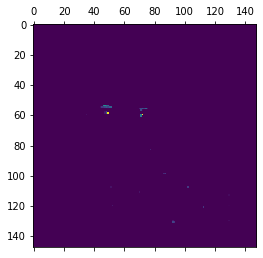
Como ya se discutió, las capas iniciales identifican características de bajo nivel. El sexto canal identifica los bordes de la imagen, mientras que el decimoquinto canal identifica el color de los ojos.
Código: Los nombres de las ocho capas en nuestro modelo.
layer_names = [] for layer in model.layers[:8]: layer_names.append(layer.name) print(layer_names)
Producción:
Layer names: ['conv2d_1', 'max_pooling2d_1', 'conv2d_2', 'max_pooling2d_2', 'conv2d_3', 'max_pooling2d_3', 'conv2d_4', 'max_pooling2d_4']
Mapas de características de cada capa:
Capa 1: conv2d_1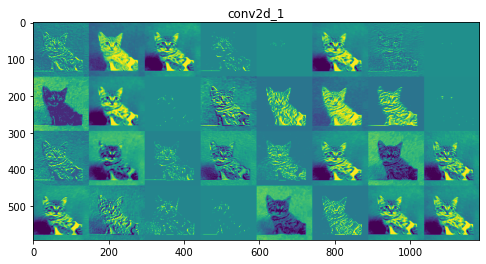
Capa 2: max_pooling2d_1
Capa 3: conv2d_2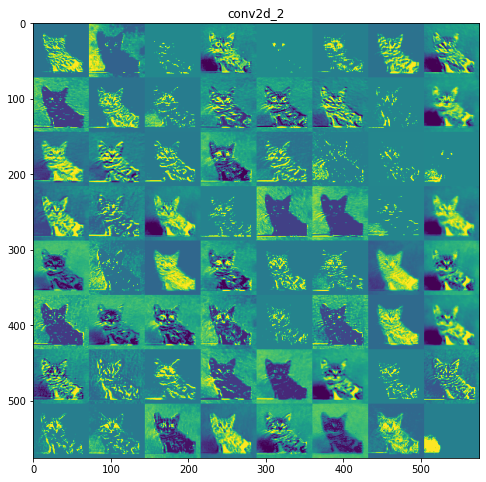
Capa 4: max_pooling2d_2
Capa 5: conv2d_3
Capa 6: max_pooling2d_3
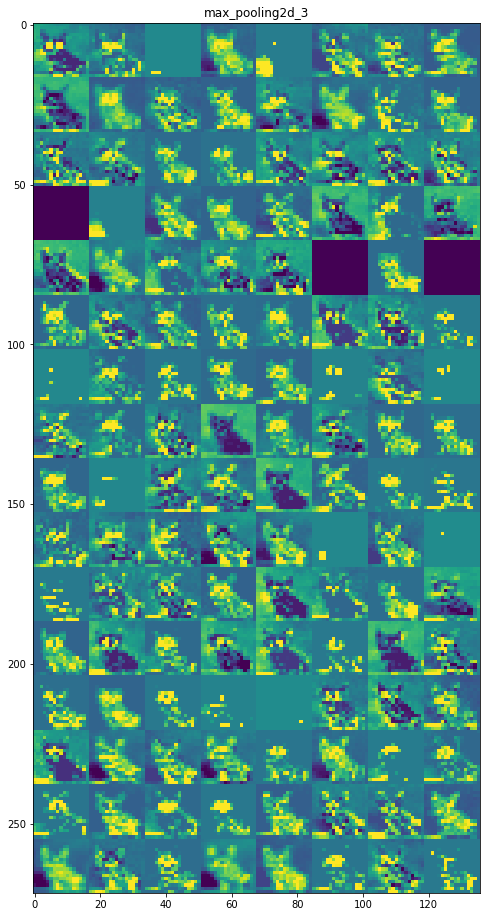
Capa 7: conv2d_4
Capa 8: max_pooling2d_4
Inferencia:
las capas iniciales son más interpretables y conservan la mayoría de las características de la imagen de entrada. A medida que aumenta el nivel de la capa, las características se vuelven menos interpretables, se vuelven más abstractas e identifican características específicas de la clase dejando atrás las características generales de la imagen.
Referencias:
- https://keras.io/api/modelos/modelo/
- https://www.kaggle.com/c/dogs-vs-cats
- https://www.geeksforgeeks.org/introduction-convolution-neural-network/