La clasificación de imágenes es uno de los problemas de aprendizaje automático supervisado que tiene como objetivo categorizar las imágenes de un conjunto de datos en sus respectivas categorías o etiquetas. La clasificación de imágenes de varias razas de perros es un problema clásico de clasificación de imágenes. Por lo tanto, tenemos que clasificar más de una clase, por eso el nombre de clasificación multiclase y, en este artículo, haremos lo mismo utilizando un modelo preentrenado InceptionResNetV2 y personalizándolo.
Primero analicemos algunas de las terminologías.
Aprendizaje por transferencia: el aprendizaje por transferencia es un método popular de aprendizaje profundo que sigue el enfoque de usar el conocimiento que se aprendió en alguna tarea y aplicarlo para resolver el problema de la tarea de destino relacionada. Entonces, en lugar de crear una red neuronal desde cero, » transferimos » las características aprendidas que son básicamente los » pesos » de la red. Para implementar el concepto de transferencia de aprendizaje, hacemos uso de » modelos pre-entrenados «.
Necesidades para el aprendizaje de transferencia : las características de bajo nivel del modelo A (tarea A) deberían ser útiles para aprender el modelo B (tarea B).
Modelo preentrenado: los modelos preentrenados son los modelos de aprendizaje profundo que se entrenan en conjuntos de datos muy grandes, se desarrollan y están disponibles por otros desarrolladores que desean contribuir a esta comunidad de aprendizaje automático para resolver tipos similares de problemas. Contiene los sesgos y pesos de la red neuronal que representan las características del conjunto de datos en el que se entrenó. Las características aprendidas son siempre transferibles. Por ejemplo, un modelo entrenado en un gran conjunto de datos de imágenes de flores contendrá características aprendidas como esquinas, bordes, forma, color, etc.
InceptionResNetV2: InceptionResNetV2 es una red neuronal convolucional que tiene 164 capas de profundidad, entrenada en millones de imágenes de la base de datos de ImageNet y puede clasificar imágenes en más de 1000 categorías, como flores, animales, etc. El tamaño de entrada de las imágenes es 299- por-299.
Descripción del conjunto de datos:
- El conjunto de datos utilizado comprende 120 razas de perros en total.
- Cada imagen tiene un nombre de archivo que es su identificación única.
- Conjunto de datos de tren (train.zip) : contiene 10,222 imágenes que se utilizarán para entrenar nuestro modelo
- Test dataset (test.zip) : contiene 10.357 imágenes que tenemos que clasificar en las respectivas categorías o etiquetas.
- etiquetas.csv : contiene nombres de raza correspondientes a la identificación de la imagen.
- sample_submission.csv : contiene la forma correcta de envío de la muestra que se debe realizar
Todos los archivos mencionados anteriormente se pueden descargar desde aquí .
NOTA : para un mejor rendimiento, use GPU.
Primero importamos todas las bibliotecas necesarias.
Python3
import numpy as np
import pandas as pd
import seaborn as sns
import matplotlib.pyplot as plt
from sklearn.metrics import classification_report, confusion_matrix
# deep learning libraries
import tensorflow as tf
import keras
from keras.preprocessing.image import ImageDataGenerator
from tensorflow.keras import applications
from keras.models import Sequential, load_model
from keras.layers import Conv2D, MaxPooling2D, GlobalAveragePooling2D, Flatten, Dense, Dropout
from keras.preprocessing import image
import cv2
import warnings
warnings.filterwarnings('ignore')
Cargar conjuntos de datos y carpetas de imágenes
Python3
from google.colab import drive
drive.mount("/content/drive")
# datasets
labels = pd.read_csv("/content/drive/My Drive/dog/labels.csv")
sample = pd.read_csv('/content/drive/My Drive/dog/sample_submission.csv')
# folders paths
train_path = "/content/drive/MyDrive/dog/train"
test_path = "/content/drive/MyDrive/dog/test"
Visualización de los primeros cinco registros del conjunto de datos de etiquetas para ver sus atributos.
Python3
labels.head()
Producción:
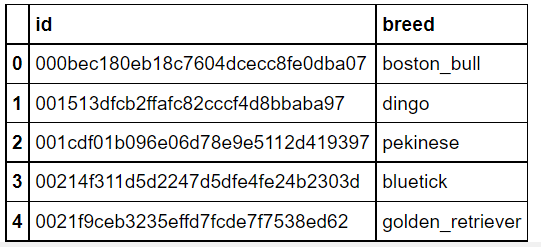
Agregar la extensión ‘.jpg’ a cada identificación
Esto se hace para obtener las imágenes de la carpeta, ya que el nombre de la imagen y la identificación son los mismos, por lo que agregar la extensión .jpg nos ayudará a recuperar las imágenes fácilmente.
Python3
def to_jpg(id): return id+".jpg" labels['id'] = labels['id'].apply(to_jpg) sample['id'] = sample['id'].apply(to_jpg)
Aumento de datos:
Es una técnica de preprocesamiento en la que aumentamos el conjunto de datos existente con versiones transformadas de las imágenes existentes. Podemos realizar escalado, rotaciones, aumento de brillo y otras transformaciones afines. Esta es una técnica útil ya que ayuda al modelo a generalizar bien los datos no vistos.
La clase ImageDataGenerator se utiliza para este propósito, que proporciona un aumento de datos en tiempo real.a
Descripción de algunos de sus parámetros que se utilizan a continuación:
- rescale : cambia la escala de los valores por el factor dado
- volteo horizontal : voltear aleatoriamente las entradas horizontalmente.
- validación_split : esta es la fracción de imágenes reservadas para la validación (entre 0 y 1).
Python3
# Data agumentation and pre-processing using tensorflow gen = ImageDataGenerator( rescale=1./255., horizontal_flip = True, validation_split=0.2 # training: 80% data, validation: 20% data ) train_generator = gen.flow_from_dataframe( labels, # dataframe directory = train_path, # images data path / folder in which images are there x_col = 'id', y_col = 'breed', subset="training", color_mode="rgb", target_size = (331,331), # image height , image width class_mode="categorical", batch_size=32, shuffle=True, seed=42, ) validation_generator = gen.flow_from_dataframe( labels, # dataframe directory = train_path, # images data path / folder in which images are there x_col = 'id', y_col = 'breed', subset="validation", color_mode="rgb", target_size = (331,331), # image height , image width class_mode="categorical", batch_size=32, shuffle=True, seed=42, )
Producción:

Veamos cómo se ve un solo lote de datos.
Python3
x,y = next(train_generator) x.shape # input shape of one record is (331,331,3) , 32: is the batch size
Producción:
(32, 331, 331, 3)
Trazado de imágenes del conjunto de datos del tren
Python3
a = train_generator.class_indices
class_names = list(a.keys()) # storing class/breed names in a list
def plot_images(img, labels):
plt.figure(figsize=[15, 10])
for i in range(25):
plt.subplot(5, 5, i+1)
plt.imshow(img[i])
plt.title(class_names[np.argmax(labels[i])])
plt.axis('off')
plot_images(x,y)
Producción:

Construyendo nuestro modelo
Este es el paso principal donde se construye el modelo de convolución neuronal.
Python3
# load the InceptionResNetV2 architecture with imagenet weights as base base_model = tf.keras.applications.InceptionResNetV2( include_top=False, weights='imagenet', input_shape=(331,331,3) ) base_model.trainable=False # For freezing the layer we make use of layer.trainable = False # means that its internal state will not change during training. # model's trainable weights will not be updated during fit(), # and also its state updates will not run. model = tf.keras.Sequential([ base_model, tf.keras.layers.BatchNormalization(renorm=True), tf.keras.layers.GlobalAveragePooling2D(), tf.keras.layers.Dense(512, activation='relu'), tf.keras.layers.Dense(256, activation='relu'), tf.keras.layers.Dropout(0.5), tf.keras.layers.Dense(128, activation='relu'), tf.keras.layers.Dense(120, activation='softmax') ])
Normalización por lotes :
- Es una técnica de normalización que se realiza a lo largo de mini lotes en lugar del conjunto de datos completo.
- Se utiliza para acelerar el entrenamiento y usar tasas de aprendizaje más altas.
- Mantiene la salida media cerca de 0 y la desviación estándar de salida cerca de 1.
GlobalAveragePooling2D :
- Toma un tensor de tamaño (ancho de entrada) x (alto de entrada) x (canales de entrada) y calcula el valor promedio de todos los valores en toda la array (ancho de entrada) x (alto de entrada) para cada uno de los (canales de entrada).
- La dimensionalidad de las imágenes se reduce al reducir el número de píxeles en la salida de la capa de red neuronal anterior.
- Al usar esto, obtenemos un tensor de tamaño unidimensional (canales de entrada) como nuestra salida.
- Operación de agrupación promedio global 2D. Aquí ‘Profundidad’ = ‘Filtros’
Capas densas : estas capas son capas regulares de redes neuronales totalmente conectadas conectadas después de las capas convolucionales.
Drop out layer : también se utiliza cuya función es soltar aleatoriamente algunas neuronas de la unidad de entrada para evitar el sobreajuste. El valor de 0,5 indica que se deben descartar 0,5 fracciones de neuronas.
Compilar el modelo:
Antes de entrenar nuestro modelo, primero debemos configurarlo y eso lo hace model.compile(), que define la función de pérdida, los optimizadores y las métricas para la predicción.
Python3
model.compile(optimizer='Adam',loss='categorical_crossentropy',metrics=['accuracy']) # categorical cross entropy is taken since its used as a loss function for # multi-class classification problems where there are two or more output labels. # using Adam optimizer for better performance # other optimizers such as sgd can also be used depending upon the model
Visualización de un informe resumido del modelo
Desplegando el resumen podemos comprobar nuestro modelo para confirmar que todo está como se esperaba.
Python3
model.summary()
Producción:

Definición de devoluciones de llamada para preservar los mejores resultados:
Devolución de llamada: es un objeto que puede realizar acciones en varias etapas de entrenamiento (por ejemplo, al comienzo o al final de una época, antes o después de un solo lote, etc.).
Python3
early = tf.keras.callbacks.EarlyStopping( patience=10, min_delta=0.001, restore_best_weights=True) # early stopping call back
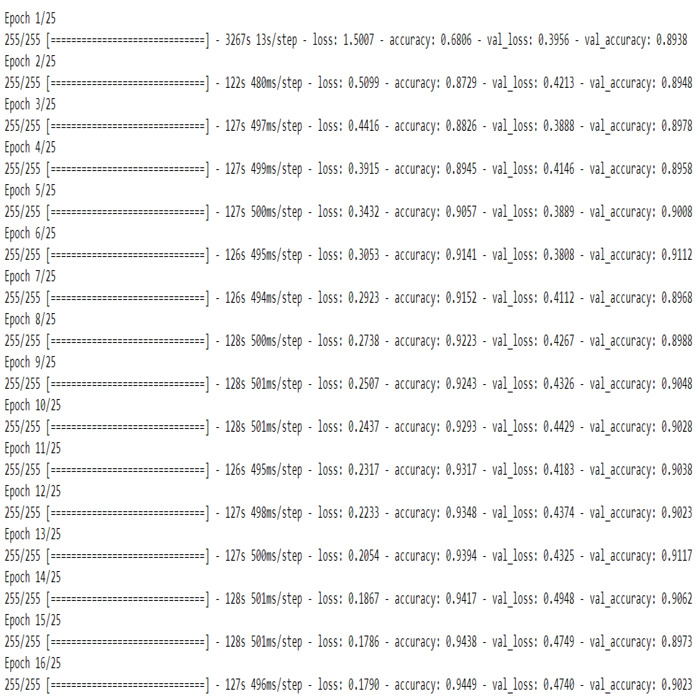
Entrenamiento del modelo: significa que estamos encontrando un conjunto de valores para pesos y sesgos que tienen una pérdida baja en promedio en todos los registros.
Python3
batch_size=32 STEP_SIZE_TRAIN = train_generator.n//train_generator.batch_size STEP_SIZE_VALID = validation_generator.n//validation_generator.batch_size # fit model history = model.fit(train_generator, steps_per_epoch=STEP_SIZE_TRAIN, validation_data=validation_generator, validation_steps=STEP_SIZE_VALID, epochs=25, callbacks=[early]
Producción:
Guardar el modelo
Podemos guardar el modelo para su uso posterior.
Python3
model.save("Model.h5")
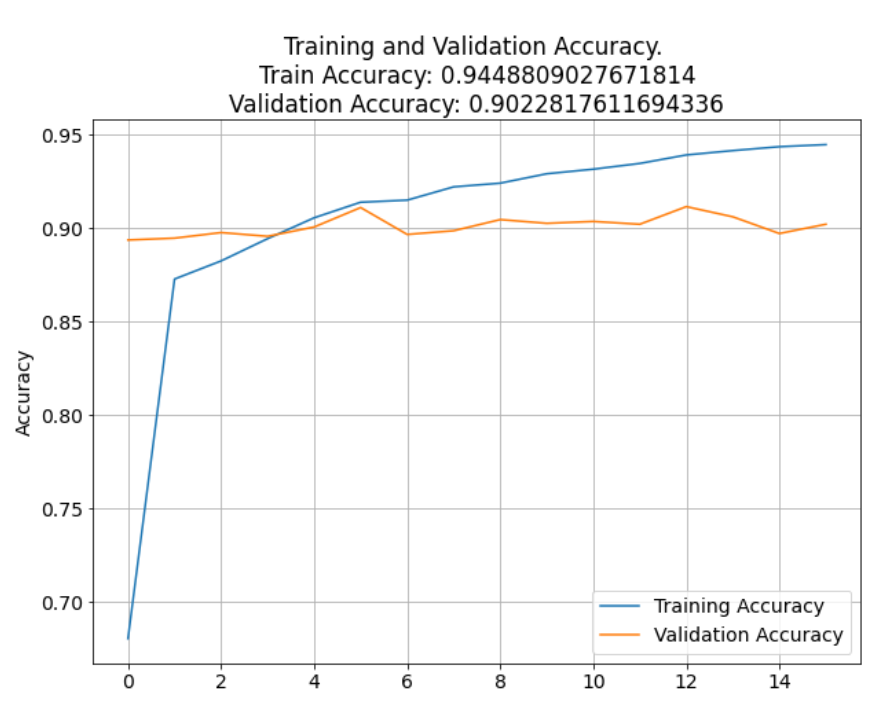
Visualización del rendimiento del modelo.
Python3
# store results
acc = history.history['accuracy']
val_acc = history.history['val_accuracy']
loss = history.history['loss']
val_loss = history.history['val_loss']
# plot results
# accuracy
plt.figure(figsize=(10, 16))
plt.rcParams['figure.figsize'] = [16, 9]
plt.rcParams['font.size'] = 14
plt.rcParams['axes.grid'] = True
plt.rcParams['figure.facecolor'] = 'white'
plt.subplot(2, 1, 1)
plt.plot(acc, label='Training Accuracy')
plt.plot(val_acc, label='Validation Accuracy')
plt.legend(loc='lower right')
plt.ylabel('Accuracy')
plt.title(f'\nTraining and Validation Accuracy. \nTrain Accuracy:
{str(acc[-1])}\nValidation Accuracy: {str(val_acc[-1])}')
Salida: Texto (0.5, 1.0, ‘\nPrecisión de entrenamiento y validación. \nPrecisión de entrenamiento: 0.9448809027671814\nPrecisión de validación: 0.9022817611694336’)
Python3
# loss
plt.subplot(2, 1, 2)
plt.plot(loss, label='Training Loss')
plt.plot(val_loss, label='Validation Loss')
plt.legend(loc='upper right')
plt.ylabel('Cross Entropy')
plt.title(f'Training and Validation Loss. \nTrain Loss:
{str(loss[-1])}\nValidation Loss: {str(val_loss[-1])}')
plt.xlabel('epoch')
plt.tight_layout(pad=3.0)
plt.show()
Producción:
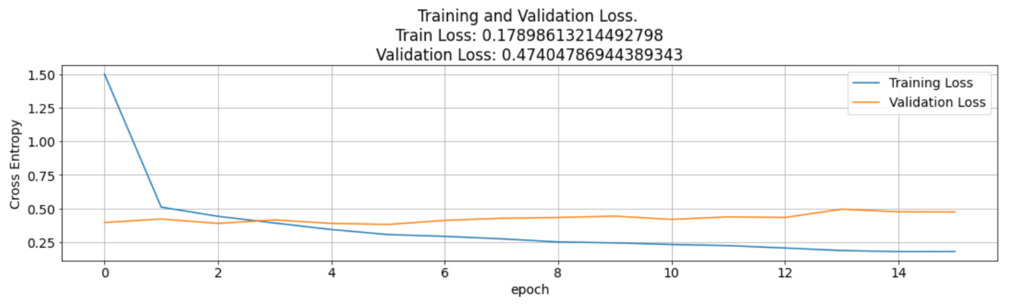
También se trazó un gráfico lineal de entrenamiento frente a precisión y pérdida de validación. El gráfico indica que las precisiones de validación y entrenamiento fueron casi consistentes entre sí y superiores al 90 %. La pérdida del modelo CNN es un gráfico de retraso negativo que indica que el modelo se está comportando como se esperaba con una pérdida decreciente después de cada época.
Evaluación de la precisión del modelo
Python3
accuracy_score = model.evaluate(validation_generator)
print(accuracy_score)
print("Accuracy: {:.4f}%".format(accuracy_score[1] * 100))
print("Loss: ",accuracy_score[0])
Producción:

Visualización de la imagen de prueba
Python3
test_img_path = test_path+"/000621fb3cbb32d8935728e48679680e.jpg"
img = cv2.imread(test_img_path)
resized_img = cv2.resize(img, (331, 331)).reshape(-1, 331, 331, 3)/255
plt.figure(figsize=(6,6))
plt.title("TEST IMAGE")
plt.imshow(resized_img[0])
Producción:

Hacer predicciones sobre los datos de prueba
Python3
predictions = []
for image in sample.id:
img = tf.keras.preprocessing.image.load_img(test_path +'/'+ image)
img = tf.keras.preprocessing.image.img_to_array(img)
img = tf.keras.preprocessing.image.smart_resize(img, (331, 331))
img = tf.reshape(img, (-1, 331, 331, 3))
prediction = model.predict(img/255)
predictions.append(np.argmax(prediction))
my_submission = pd.DataFrame({'image_id': sample.id, 'label': predictions})
my_submission.to_csv('submission.csv', index=False)
# Submission file ouput
print("Submission File: \n---------------\n")
print(my_submission.head()) # Displaying first five predicted output
Producción:
Publicación traducida automáticamente
Artículo escrito por jaimabhagwati y traducido por Barcelona Geeks. The original can be accessed here. Licence: CCBY-SA