No existe un acuerdo universal sobre lo que sugiere la “ Minería de datos ”. El enfoque en la predicción de datos no siempre es correcto con el aprendizaje automático, aunque el énfasis en el descubrimiento de las propiedades de los datos sin duda se puede aplicar siempre a la minería de datos.
Entonces, comencemos con eso: el procesamiento de datos puede ser un campo interdisciplinario que se enfoca en descubrir las propiedades de los conjuntos de conocimiento. (Olvídese de que sea el paso de análisis de «descubrimiento de conocimiento en bases de datos» KDD, esto quizás fue válido hace años, ya no lo es).
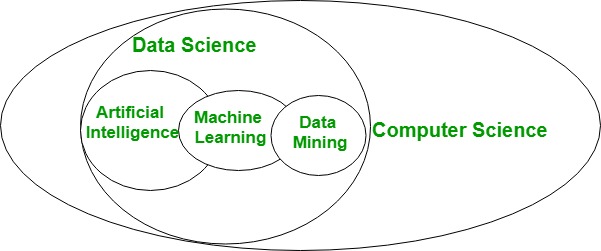
Existen diferentes enfoques para descubrir las propiedades de los conjuntos de conocimiento. El aprendizaje automático es uno de ellos. Otro es simplemente mirar los conjuntos de información técnicas de imagen de victimización o análisis de información topológica.
Por el contrario, el aprendizaje automático puede ser un subcampo de la ciencia del conocimiento que se centra en la planificación de algoritmos que pueden aprender y crear predicciones sobre la información. El aprendizaje automático incluye formas de aprendizaje supervisado y aprendizaje no supervisado. Las formas no supervisadas parten de conjuntos de información no etiquetados, por lo que, en cierto modo, se asocian directamente con la búsqueda de propiedades desconocidas en ellos (por ejemplo, grupos o reglas).
Está claro entonces que el aprendizaje automático se utilizará para el procesamiento de datos. Sin embargo, el procesamiento de datos utilizará diferentes técnicas además del aprendizaje automático.
Para crear cosas incluso más sofisticadas, actualmente tenemos un término de reemplazo, Ciencias de la información, que compite por la atención, particularmente con el procesamiento de datos y KDD. Incluso el grupo SIGKDD en ACM se está moviendo lentamente hacia la ciencia de la información de victimización. En su sitio web, actualmente se describen a sí mismos como «La comunidad para el procesamiento de datos, la ciencia de la información y el análisis». Según las predicciones, KDD puede desaparecer como término bastante antes de una edición larga, y el procesamiento de datos puede simplemente fusionarse con una ciencia de la información.
Digamos que el asunto es filtrar valores atípicos de su información (detección de anomalías), lo que podría ser una tarea de minería de conocimiento. Uno podría construir el uso de técnicas estándar de aprendizaje automático como la regla algorítmica K-means en el análisis de conglomerados para detectar estos valores atípicos y construir la regla algorítmica para aprender mientras hace esto.
Ahora, estos valores atípicos miden ‘anteriormente desconocidos’ y, por lo tanto, la tarea era la misma que la minería de datos, mientras que el aprendizaje automático entra en una imagen con el atributo de ‘aprendizaje’ de la regla algorítmica utilizada para encontrar los valores atípicos.
Para “enseñar a la máquina” desea información. Por ejemplo, si desea entrenar una red neuronal para predecir el ganador de la Superbowl, no puede simplemente ordenar que la agencia de la ONU ganó ese juego del año. Eso no está llegando a ser suficiente. Deseará mucha información, como la cantidad máxima que podrá obtener. Desea que cada estadística para cada jugador sea ideal para toda su carrera. Mucha de la información que tienes, gran parte de la red neuronal aprenderá de los mismos detalles. Intenté entrenar una red neuronal para hacer bromas pesadas y tenía como 10 kb de información. Pensé que era mucho, luego encontré un diario donde alguien fue víctima de más de 3mb. Es por eso que desea el procesamiento de datos. Si está pensando en el PC como alguien, ¿cuánto tiempo le tomará a alguien decirle que hable? Observan varias conversaciones; no solo escuchan diez conversaciones y luego, como por arte de magia, se vuelven fluidos. Por lo tanto, esencialmente, el procesamiento de datos es uno de los primeros pasos hacia el aprendizaje automático. Usted extrae la información, luego la organiza, la normaliza, etc. debido a las etapas iniciales del entrenamiento de una red neuronal.
Publicación traducida automáticamente
Artículo escrito por AbhinandanBhatnagar y traducido por Barcelona Geeks. The original can be accessed here. Licence: CCBY-SA